 這三種學習模式在于深度學習的未來
這三種學習模式在于深度學習的未來
作者 | Andre Ye 譯者 | 平川 策劃 | 陳思
深度學習是一個廣闊的領域,它圍繞著一種形態由數百萬甚至數十億個變量決定并不斷變化的算法——神經網絡。似乎每隔一天就有大量的新方法和新技術被提出來。不過,總的來說,現代深度學習可以分為三種基本的學習范式。每一種都有自己的學習方法和理念,提升了機器學習的能力,擴大了其范圍。
本文最初發布于 Towards Data Science 博客,由 InfoQ 中文站翻譯并分享。
深度學習的未來在于這三種學習模式,而且它們彼此之間密切相關:
混合學習——現代深度學習方法如何跨越監督學習和非監督學習之間的邊界,以適應大量未使用的無標簽數據?
復合學習——如何以創造性的方法將不同的模型或組件連接起來,以生成一個大于各部分之和的復合模型?
簡化學習——出于性能和部署目的,如何減少模型的規模和信息流,同時保持相同或更強的預測能力?
混合學習
這種范式試圖跨越監督學習和非監督學習之間的界限。由于有標簽數據缺乏且成本高,所以常常在業務上下文中使用。從本質上說,混合學習是對下面這個問題的回答:
如何使用監督方法解決非監督問題?
首先,半監督學習在機器學習領域取得了良好的進展,因為它只需要很少的有標簽數據就能夠在監督問題上有非常好的表現。例如,一個設計良好的半監督式 GAN(生成式對抗網絡)只需要 25 個訓練樣本,就能在 MNIST 數據集上獲得了超過 90% 的準確率。
半監督學習是針對有大量無監督數據和少量有監督數據的數據集而設計的。傳統上,監督學習模型只在一部分數據上進行訓練,無監督模型則在另一部分數據上進行訓練,而半監督模型則可以將有標簽數據與從無標簽數據中提取的見解結合起來。
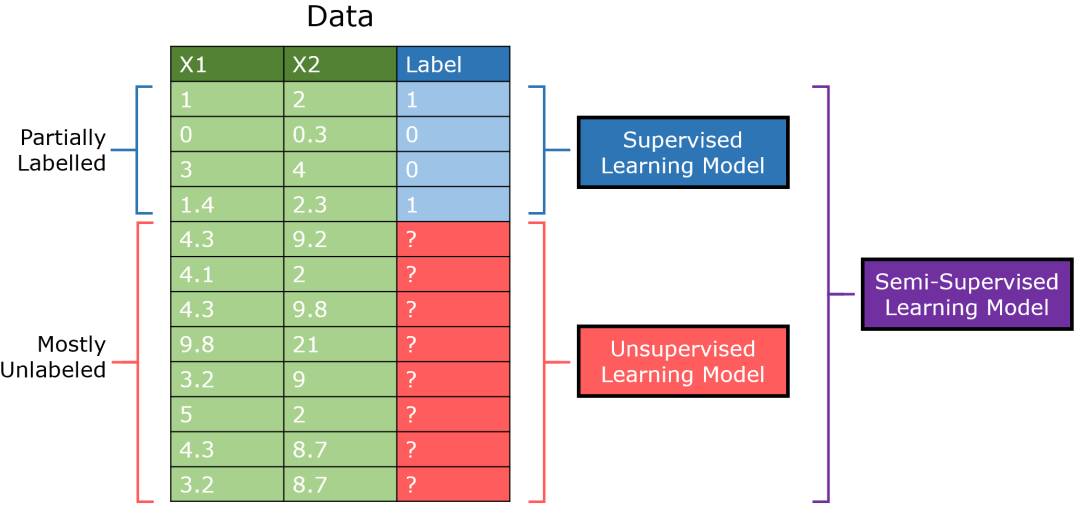
半監督 GAN(簡稱 SGAN)是對 標準生成式對抗網絡模型 的改寫。判別器輸出 0/1 表示圖像是否生成,它也輸出項的類別(多輸出學習)。
這是基于這樣一種想法,即通過判別器學習區分真實的和生成的圖像,它能夠學習它們的結構而不需要具體的標簽。通過少量標簽數據的額外增強,半監督模型就可以在少量監督數據的情況下實現最高的性能。
要了解關于 SGAN 和半監督學習的更多內容,請查看這里:
https://towardsdatascience.com/supervised-learning-but-a-lot-better-semi-supervised-learning-a42dff534781
GAN 還參與了混合學習的另一個領域——自監督學習,在這種學習中,非監督問題被明確地定義為監督問題。GAN 通過引入生成器人為地創建監督數據;創建標簽來識別真實 / 生成的圖像。在無監督的前提下,創建了一個有監督的任務。
或者,考慮使用 編碼器 - 解碼器壓縮模型。在最簡單的形式中,它們是中間有少量節點(表示某種瓶頸壓縮形式)的神經網絡。兩端分別是編碼器和解碼器。
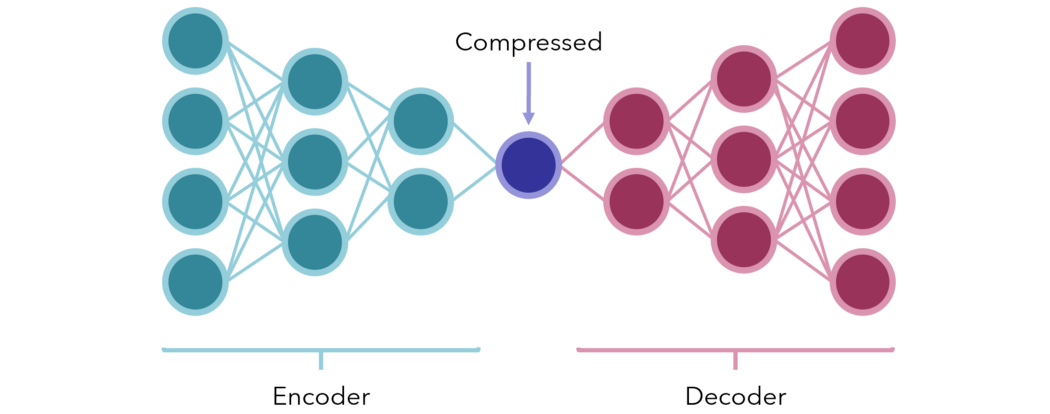
網絡被訓練成產生與輸入向量相同的輸出(從無監督數據人為地創建監督任務)。由于故意在中間設置了瓶頸,所以網絡不會被動地傳遞信息;相反,它必須找到最好的方法將輸入內容保存到一個小的單元中,這樣,解碼器就可以再次合理地對它解碼。
訓練完成后,將編碼器和解碼器分開,用于壓縮或編碼數據的接收端,以極小的形式傳輸信息,而又幾乎不丟失數據。它們還可以用來降低數據的維數。
另一個例子,考慮一個大型的文本集(可能是來自數字平臺的評論)。通過一些聚類或流形學習(manifold learning)方法,我們可以為文本集生成聚類標簽,然后用它們作為標簽(如果聚類做得好的話)。
在對每個類進行解釋之后(例如,類 A 表示對產品的抱怨,類 B 表示積極的反饋,等等),可以使用像 BERT 這樣的深層 NLP 架構將新文本分類到這些類中,所有這些都是使用了完全未標記的數據,并將人的參與降至最低。
這又是一個將非監督任務轉換為監督任務的有趣應用。在一個絕大多數數據都是非監督數據的時代,通過混合學習,在監督學習和非監督學習之間創造性地架起一座橋梁,具有巨大的價值和潛力。
復合學習
復合學習為的是利用幾種模式的知識,而不是一種。該方法認為,通過獨特的組合或信息注入——包括靜態和動態——與單一模式相比,深度學習能夠在理解和性能方面不斷地深入。
遷移學習是復合學習的一個明顯的例子,它的前提是模型的權重可以從一個在類似的任務上預先訓練過的模型中借用,然后在特定任務上進行微調。像 Inception 或 VGG-6 這樣的預訓練模型,其結構和權重被設計成可以區分幾種不同類別的圖像。
如果我要訓練一個神經網絡來識別動物(貓、狗等),我不會從頭開始訓練卷積神經網絡,因為要達到不錯的效果需要太長時間。相反,我會使用一個預先訓練過的模型(比如 Inception,它已經存儲了圖像識別的基礎知識),在數據集上額外進行幾個 epoch 的訓練。
類似地,在 NLP 神經網絡中,詞嵌入會根據單詞之間的關系在一個嵌入空間中將單詞映射到實際距離較近的其他單詞(例如,“apple”和“orange”的距離比“apple”和“truck”的距離更小)。像 GloVe 這樣預先訓練好的嵌入可以放到神經網絡中,從單詞到有意義的數字化實體的有效映射開始。
較為隱秘的一點是,競爭也能促進知識增長。首先,生成式對抗網絡借鑒了復合學習范式,從根本上使兩個神經網絡相互競爭。生成器的目標是欺騙判別器,而判別器的目標是不被騙。
下文會將模型之間的競爭稱為“對抗性學習”,不要與另一種 設計惡意輸入并利用模型弱決策邊界 的對抗性學習相混淆。
對抗性學習可以增強模型,通常是不同類型的模型,在對抗性學習中,一個模型的性能可以用其他模型的性能來表示。在對抗性學習領域還有很多研究需要做,生成式對抗網絡是這個子領域唯一突出的創新。
另一方面,競爭性學習與對抗性學習類似,但是逐節點執行的:節點競爭對輸入數據的一個子集作出響應的權利。競爭性學習是在一個“競爭層”中實現的,在這個“競爭層”中,除了某些權重隨機分布外,神經元都是相同的。
將每個神經元的權值向量與輸入向量進行比較,然后激活(output = 1)相似度最高的“贏者全拿”神經元,其余神經元“不激活”(output = 0),這種無監督技術是 自組織映射 和 特征發現 的核心組成部分。
復合學習的另一個有趣的例子是神經結構搜索。簡而言之,在強化學習環境中,神經網絡(通常是 RNN)通過學習為數據集生成最好的神經網絡——算法為你找出最好的架構!
集成(Ensemble)方法也是一種重要的復合學習方法。深度集成方法已經被證明非常 有效,而且,端到端模型疊加,像編碼器和解碼器,已經變得越來越流行。
復合學習的主要目的是找出在不同模型之間建立聯系的獨特方法。它的前提是:
單個模型,即使是一個非常大的模型,其性能也不如幾個小模型 / 組件,其中每一個都被委派專門處理一部分任務。
例如,考慮為一家餐館構建一個聊天機器人的任務。
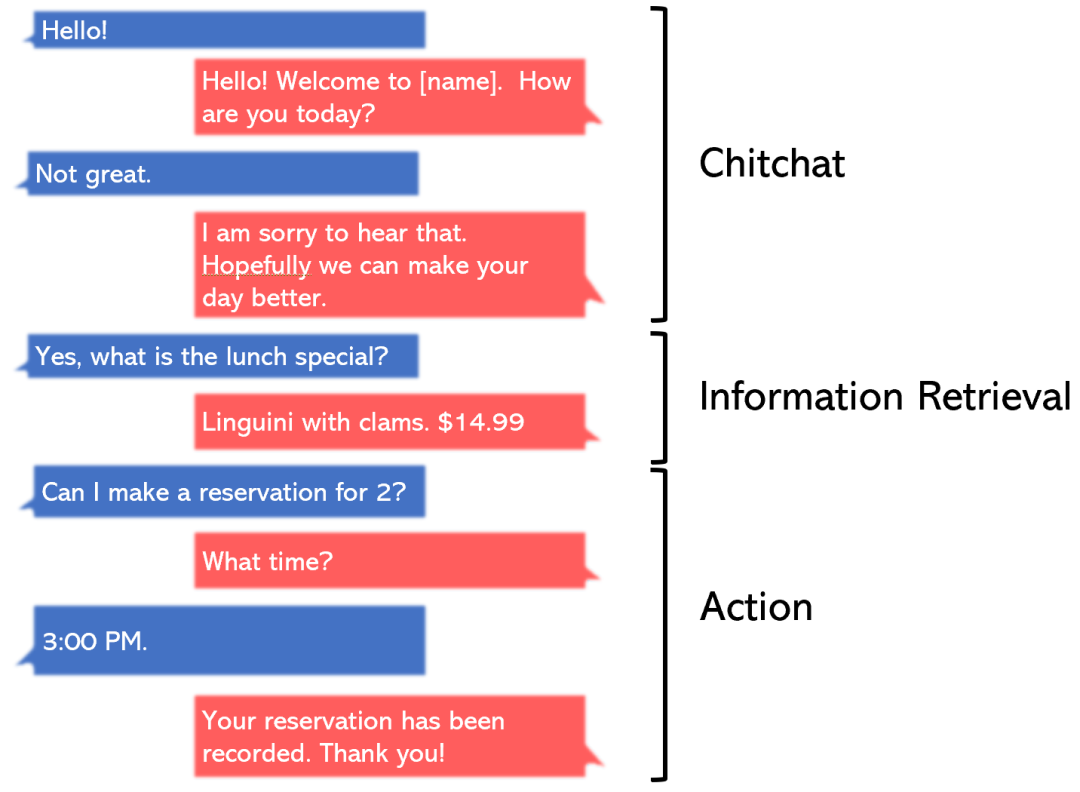
我們可以將其劃分為三個獨立的部分:寒暄 / 閑聊、信息檢索和動作,并針對每個部分單獨設計一個模型。或者,我們可以委托一個模型來執行所有這三個任務。
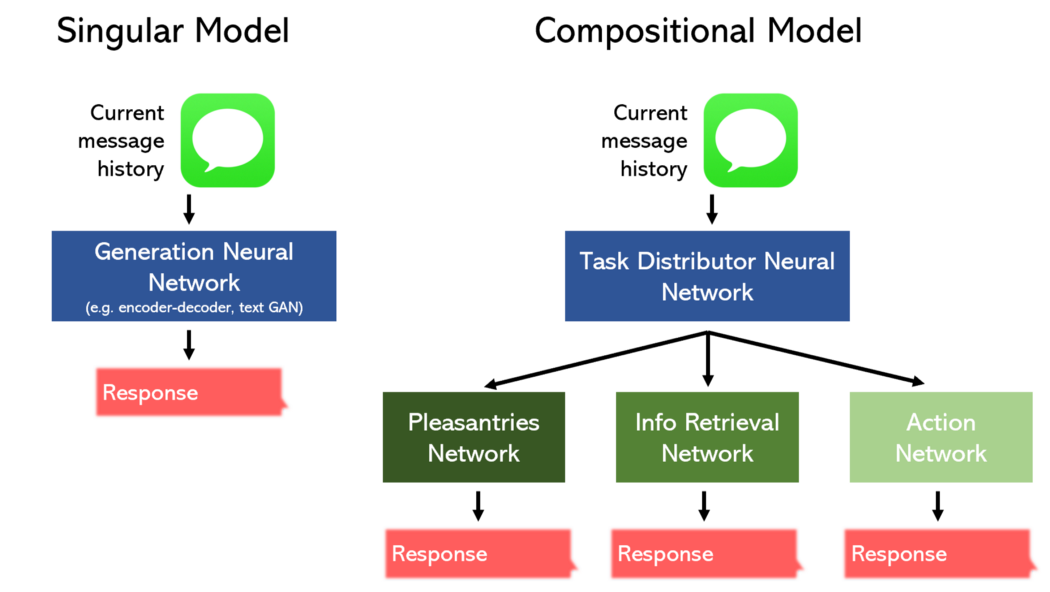
復合模型性能更好,同時占用的空間更少,這應該沒什么可奇怪的。此外,這些非線性拓撲可以用 Keras 函數式 API 這樣的工具輕松構建。
為了處理越來越多樣化的數據類型,如視頻和三維數據,研究人員必須建立創造性的復合模型。
簡化學習
模型的規模,尤其是在 NLP 領域(深度學習研究的中心),正在大幅增長。最新的 GPT-3 模型有 1750 億個參數。把它和 BERT 比較就像把木星和蚊子比較一樣(并不夸張)。未來,深度學習的模型會更大嗎?
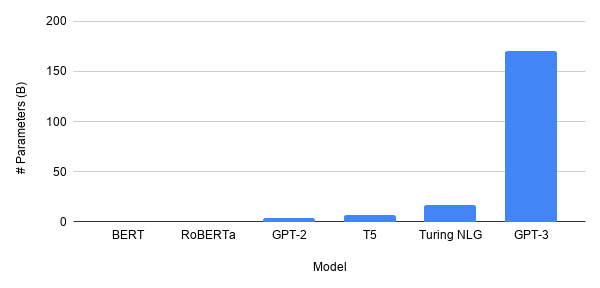
很可能不會。誠然,GPT-3 非常強大,但歷史一再表明,“成功的科學”是那些對人類影響最大的科學。當學術偏離現實太遠時,通常會淡出人們的視線。這就是神經網絡在 20 世紀末期被短暫遺忘的原因,因為可用的數據太少了,以至于這個想法,無論多么巧妙,都是沒用的。
GPT-3 是另一種語言模型,它可以寫出令人信服的文本。它的應用在哪里?是的,它可以生成查詢的答案。不過,還有更高效的方法來實現這一點(例如,遍歷一個知識圖,并使用一個更小的模型如 BERT 來輸出答案)。
考慮到 計算能力的枯竭,GPT-3 的龐大規模(更不用說更大的模型)似乎是不可行的,或者是不必要的。
“摩爾定律有點過時了。”——微軟首席執行官 Satya Nadella
相反,我們正在走向一個嵌入式人工智能的世界,智能冰箱可以自動訂購食品雜貨,無人機可以自行導航飛遍整個城市。強大的機器學習方法應該能夠下載到個人電腦、手機和小型芯片上。
這就需要輕量級人工智能:在保持性能的同時使神經網絡更小。
事實證明,在深度學習研究中,幾乎所有的東西都與直接或間接地減少必要參數的數量有關,而這又與提高泛化能力和性能緊密相關。例如,卷積層的引入大大減少了神經網絡處理圖像所需的參數數量。遞歸層在使用相同權值的同時融入了時間的概念,使得神經網絡能夠以更少的參數更好地處理序列。
嵌入層顯式地將實體映射到具有物理意義的數值,這樣負擔就不會落在其他參數上。有一種解釋說,Dropout 層在對輸入的某些部分進行操作時會顯式地屏蔽參數。L1/L2 正則化 確保網絡利用了所有的參數,而且每個參數都不會太大,并最大化了每個參數的信息價值。
隨著專用層的建立,網絡對更復雜、更大數據的要求越來越少。其他最新方法明確地尋求簡化網絡。
神經網絡剪枝 試圖去除對網絡輸出沒有價值的突觸和神經元。通過剪枝,網絡可以在去除大部分網絡節點的情況下保持其性能。
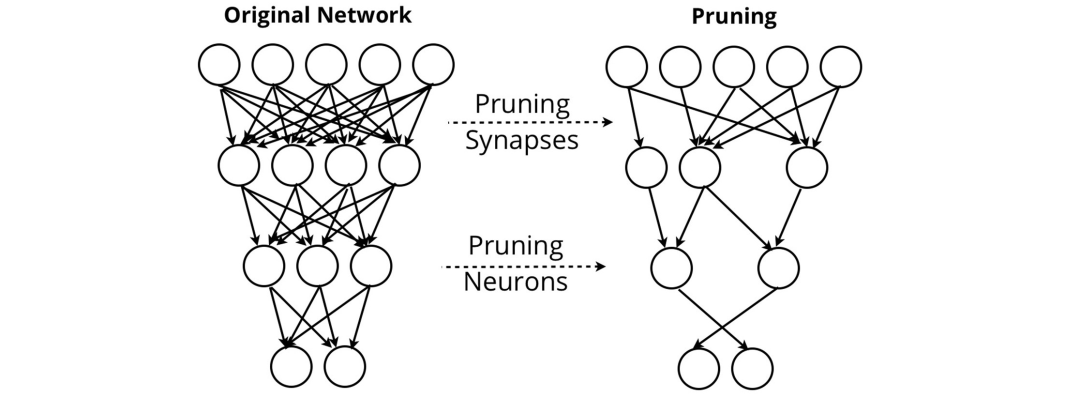
其他方法,如 Patient Knowledge Distillation,可以將大型語言模型壓縮成可下載到用戶手機上的形式。對于支撐谷歌翻譯的 谷歌神經機器翻譯(GNMT)系統 來說,這種考慮是有必要的,該系統需要創建一個能夠離線訪問的高性能翻譯服務。
本質上講,簡化學習以部署為中心進行設計。這就是為什么大多數關于簡化學習的研究都來自于公司的研究部門。以部署為中心的設計不能盲目地遵循數據集上的性能指標,而要關注模型部署時的潛在問題。
例如,前面提到的 對抗性輸入 是設計用來欺騙網絡的惡意輸入。可以用噴漆或貼紙來欺騙自動駕駛汽車,使其遠遠超過限速。負責任的簡化學習不僅是使模型足夠輕量化,而且要確保它能夠適應數據集中沒有表示出的極端情況。
在深度學習研究中,簡化學習得到的關注最少,因為“我們成功地在可行的架構規模下實現了良好的性能”遠不如“我們利用一個擁有無數參數的架構實現了最先進的性能”那么吸引人。
不可避免地,當對更高百分比的追求消失時,正如創新的歷史所顯示的那樣,簡化學習——實際上就是實用的學習——將得到更多它應該得到的關注。
總 結
混合學習試圖跨越監督學習和非監督學習的邊界。像半監督和自監督學習這樣的方法能夠從無標簽數據中提取有價值的見解,當無監督數據的數量呈指數增長時,這些見解就變得非常有價值。
隨著任務變得越來越復雜,復合學習將一個任務分解為幾個更簡單的組件。當這些組件一起工作或者相互對抗,就可以得到一個更強大的模型。
深度學習已經進入炒作階段,而簡化學習還沒有得到太多關注,但很快就會出現足夠實用并且是以部署為中心的設計。
感謝閱讀!
原文標題:深度學習未來的三種范式
文章出處:【微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
機器學習
+關注
關注
66文章
8406瀏覽量
132565 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:深度學習未來的三種范式
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
什么是PID調節器的三種模式
AI大模型與深度學習的關系
I2S有左對齊,右對齊跟標準的I2S三種格式,那么這三種格式各有什么優點呢?
深度學習算法在集成電路測試中的應用
深度學習中的時間序列分類方法
深度學習與nlp的區別在哪
555集成芯片的三種工作模式及區別
動態無功補償裝置的三種運行模式


buck電路有哪三種工作模式





 工商網監
工商網監
評論