 Google研究科學家:告別卷積
Google研究科學家:告別卷積
編譯 |凱隱 出品 | AI科技大本營(ID:rgznai100)
Transformer是由谷歌于2017年提出的具有里程碑意義的模型,同時也是語言AI革命的關鍵技術。在此之前的SOTA模型都是以循環神經網絡為基礎(RNN, LSTM等)。從本質上來講,RNN是以串行的方式來處理數據,對應到NLP任務上,即按照句中詞語的先后順序,每一個時間步處理一個詞語。
相較于這種串行模式,Transformer的巨大創新便在于并行化的語言處理:文本中的所有詞語都可以在同一時間進行分析,而不是按照序列先后順序。為了支持這種并行化的處理方式,Transformer依賴于注意力機制。注意力機制可以讓模型考慮任意兩個詞語之間的相互關系,且不受它們在文本序列中位置的影響。通過分析詞語之間的兩兩相互關系,來決定應該對哪些詞或短語賦予更多的注意力。
相較于RNN必須按時間順序進行計算,Transformer并行處理機制的顯著好處便在于更高的計算效率,可以通過并行計算來大大加快訓練速度,從而能在更大的數據集上進行訓練。例如GPT-3(Transformer的第三代)的訓練數據集大約包含5000億個詞語,并且模型參數量達到1750億,遠遠超越了現有的任何基于RNN的模型。
現有的各種基于Transformer的模型基本只是與NLP任務有關,這得益于GPT-3等衍生模型的成功。然而,最近ICLR 2021的一篇投稿文章開創性地將Transformer模型跨領域地引用到了計算機視覺任務中,并取得了不錯地成果。這也被許多AI學者認為是開創了CV領域的新時代,甚至可能完全取代傳統的卷積操作。 其中,Google的Deepmind 研究科學家Oriol Vinyals的看法很直接:告別卷積。 以下為該論文的詳細工作:
基本內容 Transformer的核心原理是注意力機制,注意力機制在具體實現時主要以矩陣乘法計算為基礎,這意味著可以通過并行化來加快計算速度,相較于只能按時間順序進行串行計算的RNN模型而言,大大提高了訓練速度,從而能夠在更大的數據集上進行訓練。 此外,Transformer模型還具有良好的可擴展性和伸縮性,在面對具體的任務時,常用的做法是先在大型數據集上進行訓練,然后在指定任務數據集上進行微調。并且隨著模型大小和數據集的增長,模型本身的性能也會跟著提升,目前為止還沒有一個明顯的性能天花板。
Transformer的這兩個特性不僅讓其在NLP領域大獲成功,也提供了將其遷移到其他任務上的潛力。此前已經有文章嘗試將注意力機制應用到圖像識別任務上,但他們要么是沒有脫離CNN的框架,要么是對注意力機制進行了修改,導致計算效率低,不能很好地實現并行計算加速。因此在大規模圖片分類任務中,以ResNet為基本結構的模型依然是主流。
這篇文章首先嘗試在幾乎不做改動的情況下將Transformer模型應用到圖像分類任務中,在 ImageNet 得到的結果相較于 ResNet 較差,這是因為Transformer模型缺乏歸納偏置能力,例如并不具備CNN那樣的平移不變性和局部性,因此在數據不足時不能很好的泛化到該任務上。然而,當訓練數據量得到提升時,歸納偏置的問題便能得到緩解,即如果在足夠大的數據集上進行與訓練,便能很好地遷移到小規模數據集上。 在此基礎上,作者提出了Vision Transformer模型。下面將介紹模型原理。
模型原理 該研究提出了一種稱為Vision Transformer(ViT)的模型,在設計上是盡可能遵循原版Transformer結構,這也是為了盡可能保持原版的性能。 雖然可以并行處理,但Transformer依然是以一維序列作為輸入,然而圖片數據都是二維的,因此首先要解決的問題是如何將圖片以合適的方式輸入到模型中。本文采用的是切塊 + embedding的方法,如下圖:
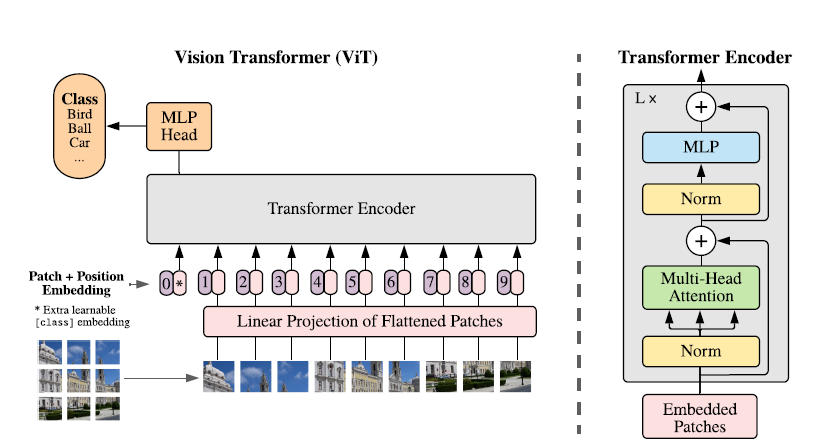
首先將原始圖片劃分為多個子圖(patch),每個子圖相當于一個word,這個過程也可以表示為:

其中x是輸入圖片,xp則是處理后的子圖序列,P2則是子圖的分辨率,N則是切分后的子圖數量(即序列長度),顯然有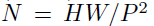 。由于Transformer只接受1D序列作為輸入,因此還需要對每個patch進行embedding,通過一個線性變換層將二維的patch嵌入表示為長度為D的一維向量,得到的輸出被稱為patch嵌入。 ? 類似于BERT模型的[class] token機制,對每一個patch嵌入
。由于Transformer只接受1D序列作為輸入,因此還需要對每個patch進行embedding,通過一個線性變換層將二維的patch嵌入表示為長度為D的一維向量,得到的輸出被稱為patch嵌入。 ? 類似于BERT模型的[class] token機制,對每一個patch嵌入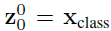 ,都會額外預測一個可學習的嵌入表示,然后將這個嵌入表示在encoder中的最終輸出(
,都會額外預測一個可學習的嵌入表示,然后將這個嵌入表示在encoder中的最終輸出(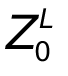 )作為對應patch的表示。在預訓練和微調階段,分類頭都依賴于。 ? 此外還加入了位置嵌入信息(圖中的0,1,2,3…),因為序列化的patch丟失了他們在圖片中的位置信息。作者嘗試了各種不同的2D嵌入方法,但是相較于一般的1D嵌入并沒有任何顯著的性能提升,因此最終使用聯合嵌入作為輸入。 ? 模型結構與標準的Transformer相同(如上圖右側),即由多個交互層多頭注意力(MSA)和多層感知器(MLP)構成。在每個模塊前使用LayerNorm,在模塊后使用殘差連接。使用GELU作為MLP的激活函數。整個模型的更新公式如下:
)作為對應patch的表示。在預訓練和微調階段,分類頭都依賴于。 ? 此外還加入了位置嵌入信息(圖中的0,1,2,3…),因為序列化的patch丟失了他們在圖片中的位置信息。作者嘗試了各種不同的2D嵌入方法,但是相較于一般的1D嵌入并沒有任何顯著的性能提升,因此最終使用聯合嵌入作為輸入。 ? 模型結構與標準的Transformer相同(如上圖右側),即由多個交互層多頭注意力(MSA)和多層感知器(MLP)構成。在每個模塊前使用LayerNorm,在模塊后使用殘差連接。使用GELU作為MLP的激活函數。整個模型的更新公式如下:
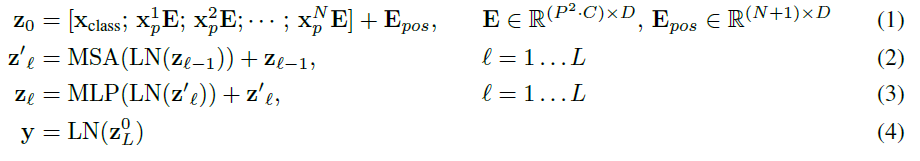
其中(1)代表了嵌入層的更新,公式(2)和(3)則代表了MSA和MLP的前向傳播。 此外本文還提出了一種直接采用ResNet中間層輸出作為圖片嵌入表示的方法,可以作為上述基于patch分割方法的替代。
模型訓練和分辨率調整 和之前常用的做法一樣,在針對具體任務時,先在大規模數據集上訓練,然后根據具體的任務需求進行微調。這里主要是更換最后的分類頭,按照分類數來設置分類頭的參數形狀。此外作者還發現在更高的分辨率進行微調往往能取得更好的效果,因為在保持patch分辨率不變的情況下,原始圖像分辨率越高,得到的patch數越大,因此得到的有效序列也就越長。
對比實驗4.1 實驗設置 首先作者設計了多個不同大小的ViT變體,分別對應不同的復雜度。
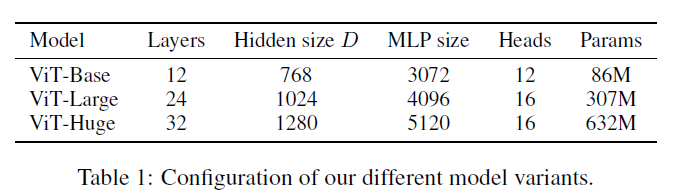
數據集主要使用ILSVRC-2012,ImageNet-21K,以及JFT數據集。 4.2 與SOTA模型的性能對比 首先是和ResNet以及efficientNet的對比,這兩個模型都是比較有代表的基于CNN的模型。
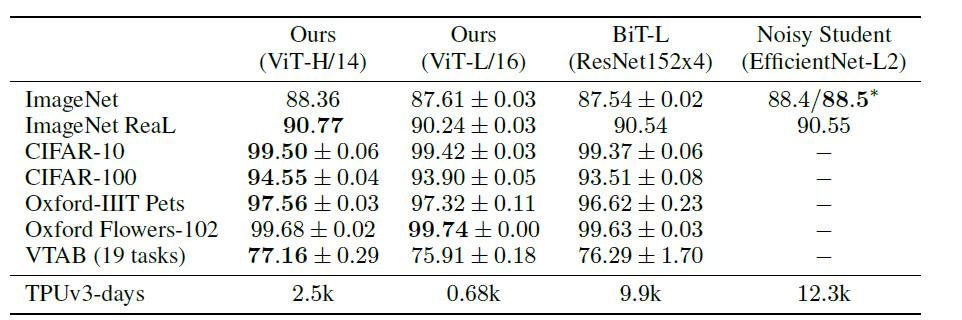
其中ViT模型都是在JFT-300M數據集上進行了預訓練。從上表可以看出,復雜度較低,規模較小的ViT-L在各個數據集上都超過了ResNet,并且其所需的算力也要少十多倍。ViT-H規模更大,但性能也有進一步提升,在ImageNet, CIFAR,Oxford-IIIT, VTAB等數據集上超過了SOTA,且有大幅提升。 作者進一步將VTAB的任務分為多組,并對比了ViT和其他幾個SOTA模型的性能:
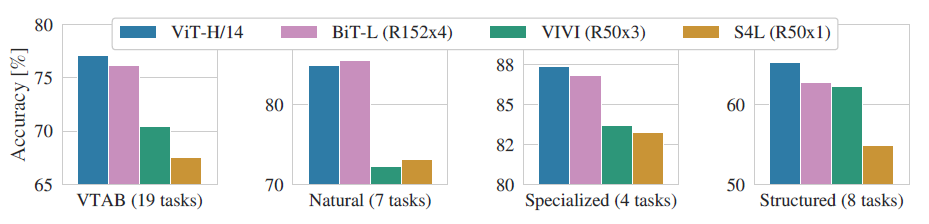
可以看到除了在Natrual任務中ViT略低于BiT外,在其他三個任務中都達到了SOTA,這再次證明了ViT的性能強大。 4.3 不同預訓練數據集對性能的影響 預訓練對于該模型而言是一個非常重要的環節,預訓練所用數據集的規模將影響模型的歸納偏置能力,因此作者進一步探究了不同規模的預訓練數據集對性能的影響:
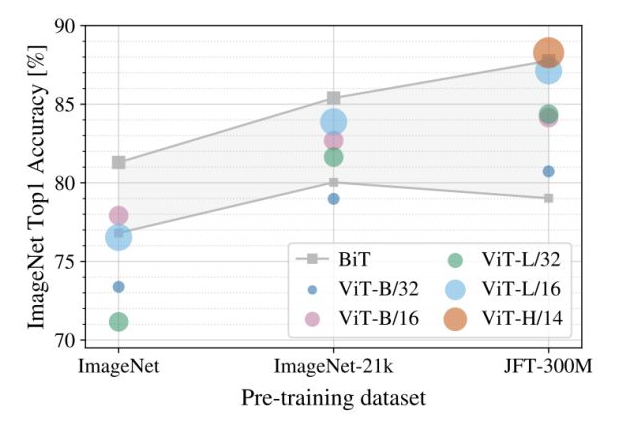
上圖展示了不同規模的預訓練數據集(橫軸)對不同大小的模型的性能影響,注意微調時的數據集固定為ImageNet。可以看到對大部分模型而言,預訓練數據集規模越大,最終的性能越好。并且隨著數據集的增大,較大的ViT模型(ViT-H/14)要由于較小的ViT模型(ViT-L)。 此外,作者還在不同大小的JFT數據集的子集上進行了模型訓練:
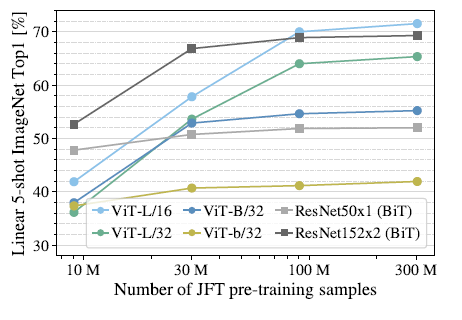
可以發現ViT-L對應的兩個模型在數據集規模增大時有非常明顯的提升,而ResNet則幾乎沒有變化。這里可以得出兩個結論,一是ViT模型本身的性能上限要優于ResNet,這可以理解為注意力機制的上限高于CNN。二是在數據集非常大的情況下,ViT模型性能大幅超越ResNet, 這說明在數據足夠的情況下,注意力機制完全可以代替CNN,而在數據集較小的情況下(10M),卷積則更為有效。 除了以上實驗,作者還探究了ViT模型的遷移性能,實驗結果表明不論是性能還是算力需求,ViT模型在進行遷移時都優于ResNet。
可視化分析 可視化分析可以幫助我們了解ViT的特征學習過程。顯然,ViT模型的注意力一定是放在了與分類有關的區域:

總結 本文提出的基于patch分割的圖像解釋策略,在結合Transformer的情況下取得了非常好的效果,這為CV領域的其他研究提供了一個很好的思路。此外,接下來應該會出現許多基于這篇工作的研究,進一步將這一劃時代的模型應用到更多的任務上,例如目標檢測、實例分割、行為識別等等。此外,也會出現針對patch分割策略的改進,來進一步提高模型性能。
原文標題:告別 CNN?一張圖等于 16x16 個字,計算機視覺也用上 Transformer 了
文章出處:【微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
谷歌
+關注
關注
27文章
6172瀏覽量
105631 -
AI
+關注
關注
87文章
31134瀏覽量
269471 -
CV
+關注
關注
0文章
53瀏覽量
16877 -
解釋器
+關注
關注
0文章
103瀏覽量
6543
原文標題:告別 CNN?一張圖等于 16x16 個字,計算機視覺也用上 Transformer 了
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
西湖大學:科學家+AI,科研新范式的樣本

螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
受人眼啟發!科學家開發出新型改良相機

中國科學家發現新型高溫超導體
天津大學科學家突破人類大腦器官成功驅動機器人
新華社:突破性成果!祝賀我國科學家成功研發這一傳感器!

前OpenAI首席科學家創辦新的AI公司
助力科學發展,NVIDIA AI加速HPC研究

本源量子參與的國家重點研發計劃青年科學家項目啟動會順利召開

NVIDIA首席科學家Bill Dally:深度學習硬件趨勢

康奈爾大學科學家研制出5分鐘快速充電鋰電池
谷歌DeepMind科學家欲建AI初創公司
飛騰首席科學家竇強榮獲 “國家卓越工程師” 稱號






 工商網監
工商網監
評論