 深鑒科技基于FPGA技術的人工智能芯片設計
深鑒科技基于FPGA技術的人工智能芯片設計
深鑒科技發明的人工智能芯片,結合了神經網絡專用處理器和通用處理器的芯片結構,不僅可以提供一個靈活的系統,并且可以適用于復雜的神經網絡。
近年來,隨著人工智能領域的興起,越來越多的AI芯片公司出現在了人們的視野之中,AI芯片被廣泛應用于金融、購物、安防、早教以及無人駕駛等領域。而這其中,深鑒科技也憑借著先進的技術在市場中嶄露頭角。
深鑒科技的AI芯片基于FPGA設計,其設計的亞里士多德架構是針對卷積神經網絡而設計的,其設計的笛卡爾架構是專為處理DNN/RNN網絡而設計的,可對經過結構壓縮后的稀疏神經網絡進行極致高效的硬件加速。
在人工智能領域,卷積神經網絡尤其在圖像處理領域有著非常廣泛的應用,其具有訓練方法簡單、計算結構統一的特點。但是神經網絡存儲計算量都很大。工程師們試圖在FPGA上搭建或者直接設計專用芯片來實現人工智能芯片,但是,這種專用神經網絡加速器的硬件還是不夠靈活,且能夠完成的任務較為單一。
為了解決這樣的問題,深鑒科技在16年8月19日申請了一項名為“通用處理器與神經網絡處理器的協同系統設計”的發明專利(申請號:201610695285.4),申請人為北京深鑒科技有限公司。
根據該專利目前公開的資料,讓我們一起來看看這項人工智能芯片專利吧。
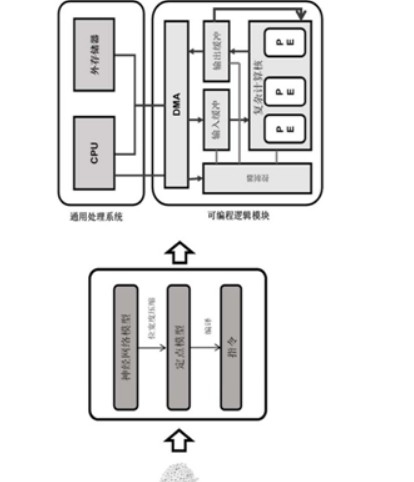
如上圖,為把人工神經網絡模型部署在專用硬件上的流程示意圖,這是一套為了加速神經網絡訓練過程,從優化流程的硬件架構的角度提出了一整套的技術方案,其中顯示了如何壓縮CNN模型以減少內存占用和操作數量,同時最大限度地減少精度損失。
這種硬件架構包括PS和PL兩個模塊,其中:PS為通用處理系統,其中包含有CPU和外部存儲器;PL為可編程邏輯模塊,其中包含有DMA、計算核、輸入輸出緩沖以及控制器等。計算核包括多個處理單元,其負責在人工智能網絡的卷積層以及全連接層的大多數計算任務,是實現人工智能芯片的核心部件。
值得一提的是,在這種架構中,雖然DMA分布在PL一側,但是卻直接被CPU所控制,并且將數據從外部存儲區內搬運到PL中。同時,這種硬件架構僅僅是進行了功能上的劃分,PL和PS之間的界限并不絕對,例如PL和CPU都可以僅僅實現在SOC上,而外部存儲器可以由另一個存儲器芯片實現并于SOC芯片中的CPU相連接。
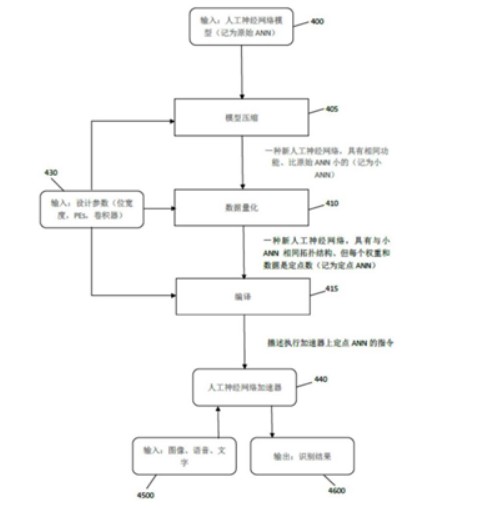
如上圖為優化人工神經網絡的整體流程圖,首先要對于模型進行壓縮,壓縮可以對CNN模型進行修剪,而網絡修剪是一種有效的方法,可以減少網絡的復雜性和過度擬合。其次,進行數據定點量化,目的是為了將浮點數轉換為定點數的同時得到最高精度。
之后再通過編譯,通過這樣的結構設計得到人工神經網絡加速器,從而可以做到輸入圖像、語音、文字,即可輸出識別的結果。這樣進行精簡后的結構有利于硬件設計,同時省去了較為復雜的運算,進一步提高了人工智能芯片進行運算的效率。
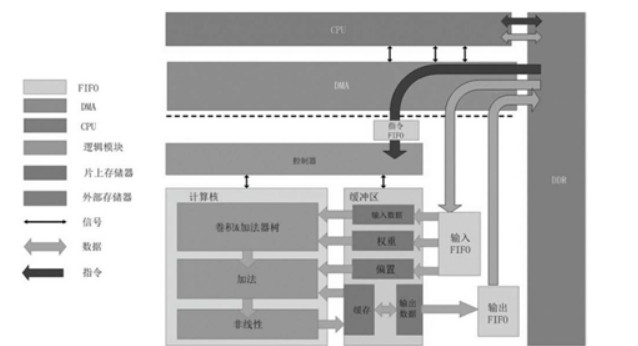
如上圖,為使用CPU和專用加速器的協同設計來實現人工神經網絡的硬件架構,在這種硬件架構中,CPU控制DMA,由DMA來負責調度數據,具體而言,CPU可以控制DMA將外部存儲器中的指令搬運到FIFO(緩沖器)中,隨后,這種為神經網絡設計的加速器從FIFO中取出指令并執行。
在運行的時候,CPU需要時刻監控DMA的狀態:當輸入緩沖區的數據未滿時,需要把數據從DDR中搬運到輸入緩沖區中;當輸出緩沖區不為空時,需要將數據從輸出緩沖區中搬運回DDR中。
此外,這種結構中使用的專用加速器包括:控制器、計算核以及緩沖區,計算核包括卷機器、加法器樹和非線性模塊,這些結構保證了人工智能芯片完成深度神經網絡的運算,從而可以完成不同的復雜的人工智能任務。
以上就是深鑒科技發明的人工智能芯片,這種結合神經網絡專用處理器和通用處理器的芯片結構,可以為人工智能應用提供一個靈活的系統,并能夠適用于復雜的神經網絡。并且該方案實現了控制器與存儲器的分離,控制器和存儲器可以使用不同的SOC芯片完成,進而保證了系統的穩定性。
關于嘉德
深圳市嘉德知識產權服務有限公司由曾在華為等世界500強企業工作多年的知識產權專家、律師、專利代理人組成,熟悉中歐美知識產權法律理論和實務,在全球知識產權申請、布局、訴訟、許可談判、交易、運營、標準專利協同創造、專利池建設、展會知識產權、跨境電商知識產權、知識產權海關保護等方面擁有豐富的經驗。
責任編輯:tzh
-
FPGA
+關注
關注
1629文章
21729瀏覽量
603013 -
芯片
+關注
關注
455文章
50715瀏覽量
423164 -
AI
+關注
關注
87文章
30734瀏覽量
268893 -
人工智能
+關注
關注
1791文章
47184瀏覽量
238267
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論