") 地平線推出自主研發(fā)的人工智能芯片
地平線推出自主研發(fā)的人工智能芯片
地平線發(fā)明的卷積處理引擎及控制方法,采用多個緩沖存儲器串聯(lián)的方式進行數(shù)據(jù)的傳輸,能有效降低AI芯片的硬件設計復雜度和成本以及提高芯片的處理效率。
早在2017年,在“AI芯·時代”發(fā)布會上,地平線就發(fā)布了中國首款全球領先的嵌入式人工智能芯片——面向智能駕駛的征程(Journey)1.0處理器和面向智能攝像頭的旭日(Sunrise)1.0處理器,同步發(fā)布的還有針對智能駕駛、智能城市和智能商業(yè)三大應用場景的人工智能解決方案。
地平線發(fā)布的“旭日 1.0”和“征程 1.0”是完全由地平線自主研發(fā)的人工智能芯片,具有全球領先的性能。我們知道,人工智能芯片及其使用的卷積神經(jīng)網(wǎng)絡算法已經(jīng)成功地應用于圖像處理、自動駕駛等諸多領域。
隨著應用需求的不斷發(fā)展,卷積神經(jīng)網(wǎng)絡中涉及的乘加運算的運算量越來越多,對于用于卷積神經(jīng)網(wǎng)絡運算的卷積神經(jīng)網(wǎng)絡加速器的處理性能也提出越來越高的要求。但是,隨著數(shù)據(jù)量和運算量的增加,卷積神經(jīng)網(wǎng)絡加速器消耗在存取數(shù)據(jù)上的時間急劇增加,并且在很多情況下成為制約卷積神經(jīng)網(wǎng)絡加速器的處理性能的主要因素之一。
因此, 為實現(xiàn)AI芯片的高性能,地平線在18年11月6日申請了一項名為“卷積處理引擎及控制方法和相應的卷積神經(jīng)網(wǎng)絡加速器”的發(fā)明專利(申請?zhí)枺?01811323140.7),申請人為地平線(上海)人工智能技術有限公司。
根據(jù)該專利目前公開的資料,讓我們一起來看看地平線的這項AI芯片技術吧。
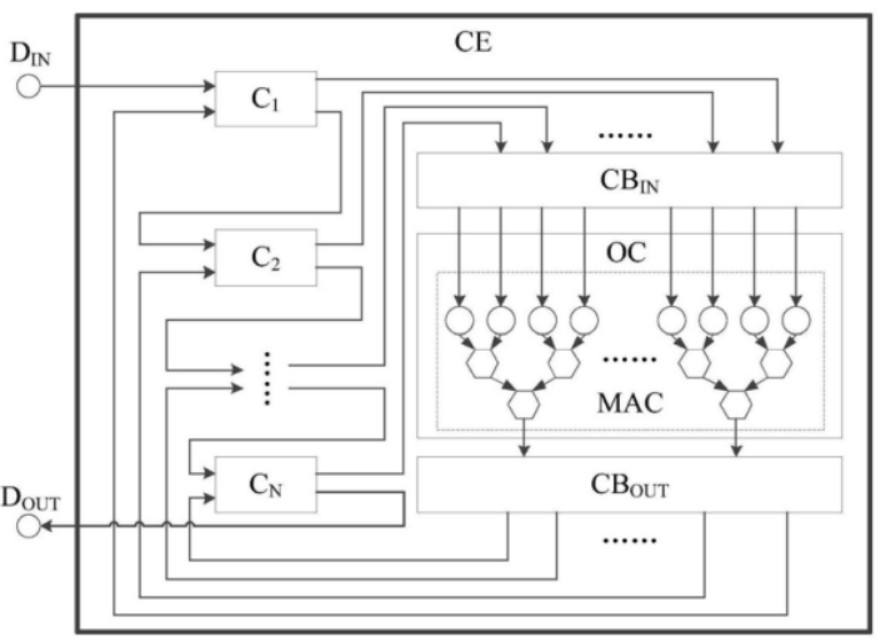
如上圖,為該專利中發(fā)明的卷積處理引擎示意圖,為了提高卷積處理引擎的處理效率,該方案在卷積處理引擎中設置了多個高速緩沖存儲器(C1-Cn):用于緩存輸入數(shù)據(jù)的輸入高速緩沖存儲器和用于緩存輸出數(shù)據(jù)的輸出高速緩沖存儲器。
并且這些緩沖存儲器兩兩之間相互耦合,如下圖所示,例如C1的輸出端藕接到高速緩沖存儲器C2的輸入端,串聯(lián)在最開始位置處的存儲器C1將接收和緩存來自于卷積處理引擎外部的數(shù)據(jù),并且最末尾的存儲器將緩存的數(shù)據(jù)傳送到引擎的外部,也就是運算后的結果數(shù)據(jù)。
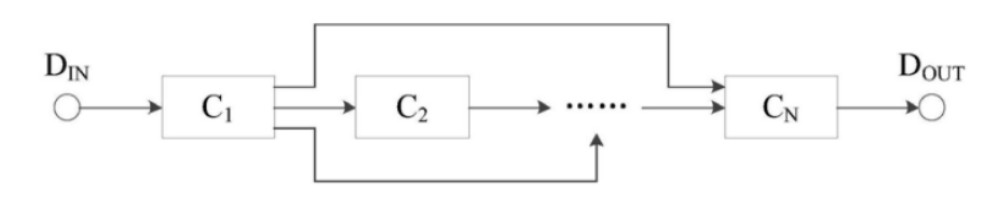
這樣盡管有多個緩沖器,但是與外部數(shù)據(jù)進行交換的始終只有兩個,從而保證了數(shù)據(jù)的安全性以及簡化了芯片內(nèi)部結構的設計。而與存儲器配合的是運算電路OC,運算電路中的乘法累加器陣列可以耦合到每個高速緩沖存儲器的輸入端,連接方式有直接互連和間接互連兩種。
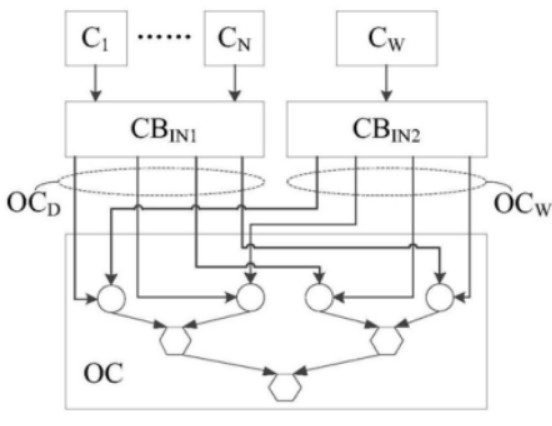
如上圖,為該卷積處理引擎中的運算電路OC的結構示意圖,可以看到高速緩沖存儲器布置在其最頂部,通過共同的交叉開關或者單獨的交叉開關耦接到高速緩沖存儲器的輸出段。
值得一提的是,該專利發(fā)明的卷積處理引擎CE,不需要針對運算電路OC分別設置輸入和輸出高速緩沖存儲器,只有一個存儲器接收外部數(shù)據(jù),也僅有一個存儲器向外輸出數(shù)據(jù)。因此,這種設計方案能夠簡化每個存儲器與處理引擎中其他部件之間的連線,同時簡化了數(shù)據(jù)傳輸?shù)目刂七壿嫞瑥亩軌驑O大地降低硬件設置的復雜度和軟件控制復雜度,并且有利于降低功耗。
下面我們再來看看上面這種處理引擎在整個AI芯片中的整體布置示意圖。
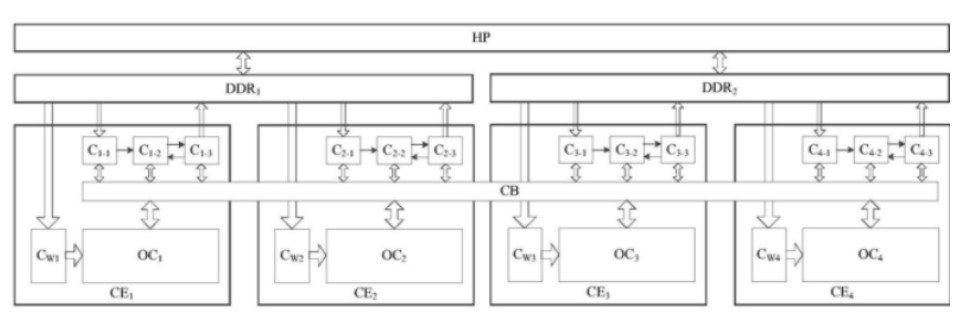
可以看到,卷積神經(jīng)網(wǎng)絡加速器包括兩個片外存儲器DDR1和DDR2以及四個卷積處理引擎CE1-CE4。每個卷積處理引擎包括運算電路、單獨的用于緩存運算參數(shù)的高速緩沖存儲器以及三個串聯(lián)在一起的高速緩沖存儲器,其中高速緩沖存儲器的輸入端還耦合到高速緩沖存儲器的輸出端。
另外,交叉開關CB跨越四個卷積處理引擎,因此能夠被每個卷積處理引擎中的串聯(lián)的三個緩沖存儲器所共用,這樣的配置可以允許一個卷積處理器引擎使用另一個卷積處理器引擎的高速緩沖存儲器。
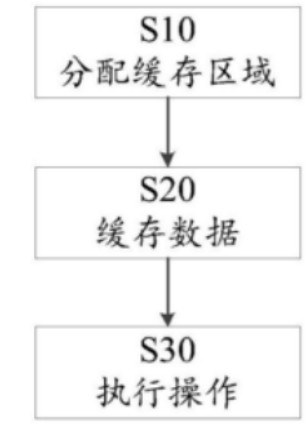
最后,我們再來看看可以用于控制上述這種硬件結構中卷積處理引擎的方法,首先可以確定待處理的卷積神經(jīng)網(wǎng)絡中連續(xù)的兩層中串聯(lián)在一起的高速緩沖存儲器的對應關系,也就是確定每層的輸入特征數(shù)與高速緩沖存儲器之間的對應關系。
其次,可以從卷積處理引擎外部接收輸入特征數(shù)據(jù)并存儲到高速緩沖存儲器的對應部分中,最后在執(zhí)行操作中,控制卷積處理引擎中的運算電路執(zhí)行第一操作。
以上就是地平線發(fā)明的卷積處理引擎及控制方法,這種卷積處理引擎采用多個緩沖存儲器串聯(lián)的方式進行數(shù)據(jù)的傳輸,每層中獲得的特征數(shù)據(jù)可以存儲在對應高速緩沖存儲器的對應部分。因此,這樣的設計方案可以以很低的硬件設計復雜度、控制復雜度、成本以及功耗來高效率地實現(xiàn)卷積運算。
關于嘉德
深圳市嘉德知識產(chǎn)權服務有限公司由曾在華為等世界500強企業(yè)工作多年的知識產(chǎn)權專家、律師、專利代理人組成,熟悉中歐美知識產(chǎn)權法律理論和實務,在全球知識產(chǎn)權申請、布局、訴訟、許可談判、交易、運營、標準專利協(xié)同創(chuàng)造、專利池建設、展會知識產(chǎn)權、跨境電商知識產(chǎn)權、知識產(chǎn)權海關保護等方面擁有豐富的經(jīng)驗。
責任編輯:tzh
-
芯片
+關注
關注
455文章
50721瀏覽量
423165 -
AI
+關注
關注
87文章
30746瀏覽量
268896 -
人工智能
+關注
關注
1791文章
47200瀏覽量
238268
發(fā)布評論請先 登錄
相關推薦
智駕科技企業(yè)地平線登陸港交所
地平線港交所上市,智駕行業(yè)迎來新風口了嗎?







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論