 算法的算法:人工神經網絡
算法的算法:人工神經網絡
在上周的人工神經網絡課程中介紹了機器學習中的支持向量機(SVM:Support Vector Machine)與前饋網絡RBF的之間的聯系,而對于由傳遞函數為線性函數組成的單層網絡的代表自適應線性單元(ADLINE:Adaptive Linear Element)更是和傳統信號處理中的自適應濾波器相類似。
這些都會讓我們看到神經網絡算法似乎能夠與很多其他學科算法搭起聯系。下面由Matthew P. Burruss的博文中《 Every Machine Learning Algorithm Can Be Represented as a Neural Network》 更是將這個觀點進行了詳細的梳理。
Every Machine Learning Algorithm Can Be Represented as a Neural Network》:
從1950年代的早期研究開始,機器學習的所有工作似乎都隨著神經網絡的創建而匯聚起來。從Logistic回歸到支持向量機,算法層出不窮,毫不夸張的說,神經網絡成為算法的算法,為機器學習的頂峰。它也從最初不斷嘗試中成為機器學習的通用表達形式。
在這個意義上,它不僅僅簡單的是一個算法,而是一個框架和理念,這也為構建神經網絡提供了更加廣泛的自由空間:比如它包括不同的隱層數量和節點數量、各種形式的激活(傳遞)函數、優化工具、損失函數、網絡類型(卷積、遞歸等)以及一些專用處理層(各種批處理模式、網絡參數隨機丟棄:Dropout等)。
由此,可以將神經網絡從一個固定算法展拓到一個通用觀念,并得到如下有趣的推文:任何機器學習算法,無論是決策樹還是k近鄰,都可以使用神經網絡來表示。
這個概念可以通過下面的一些舉例得到驗證,同樣也可以使用數據進行嚴格的證明。
1.回歸
首先讓我們定義什么是神經網絡:它是一個由輸入層,隱藏層和輸出層組成的體系結構,每一層的節點之間都有連接。信息從輸入層輸入到網絡,然后逐層通過隱層傳遞到輸出層。在層之間傳遞過程中,數據通過線性變換(權重和偏差)和非線性函數(激勵函數)變換。存在很多算法來對網絡中可變參數進行訓練。
Logistic回歸簡單定義為標準回歸,每個輸入均具有乘法系數,并添加了附加偏移量(截距),然后經過Signmoid型函數傳遞。這可以通過沒有隱藏層的神經網絡來表示, 結果是通過Sigmoid形式的輸出神經元的多元回歸。
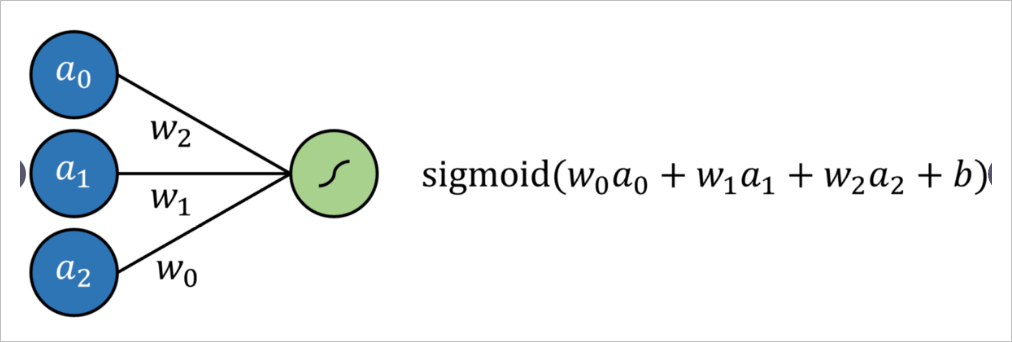
通過將輸出神經元激活函數替換為線性激活函數(可以簡單地映射輸出 ,換句話說,它什么都不做),就形成線性回歸。
2.支持向量機
支持向量機(SVM)算法嘗試通過所謂的“核函數技術”將數據投影到新的高維空間中,從而提高數據的線性可分離性。轉換完數據后,算法可在高位空間獲得兩類之間最優的分類超平面。超平面被簡單地定義為數據維度的線性組合,非常像2維空間中的直線和3維空間中的平面。
從這個意義上講,人們可以將SVM算法看作是數據到新空間的投影,然后是 多重回歸。神經網絡的輸出可以通過某種有界輸出函數傳遞,以實現概率結果。
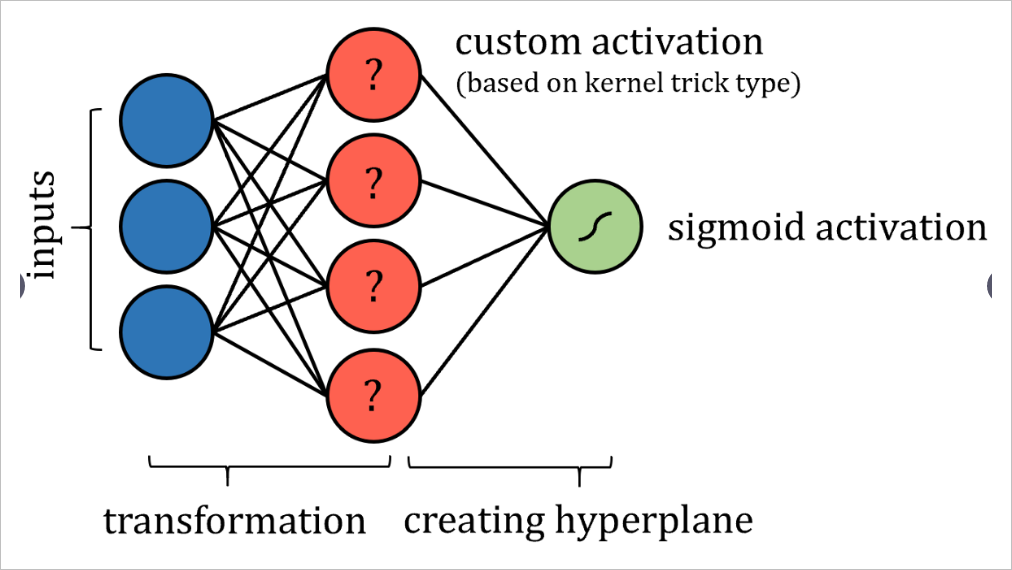
當然,可能需要實施一些限制,例如限制節點之間的連接并固定某些參數,這些更改當然不會脫離“神經網絡”標簽的完整性。也許需要添加更多的層,以確保支持向量機的這種表現能夠達到與實際交易一樣的效果。
3.決策樹
諸如決策樹算法之類的基于樹的算法有些棘手。關于如何構建這種神經網絡的答案在于分析它如何劃分其特征空間。當訓練點遍歷一系列拆分節點時,特征空間將拆分為多個超立方體。在二維示例中,垂直線和水平線創建了正方形。
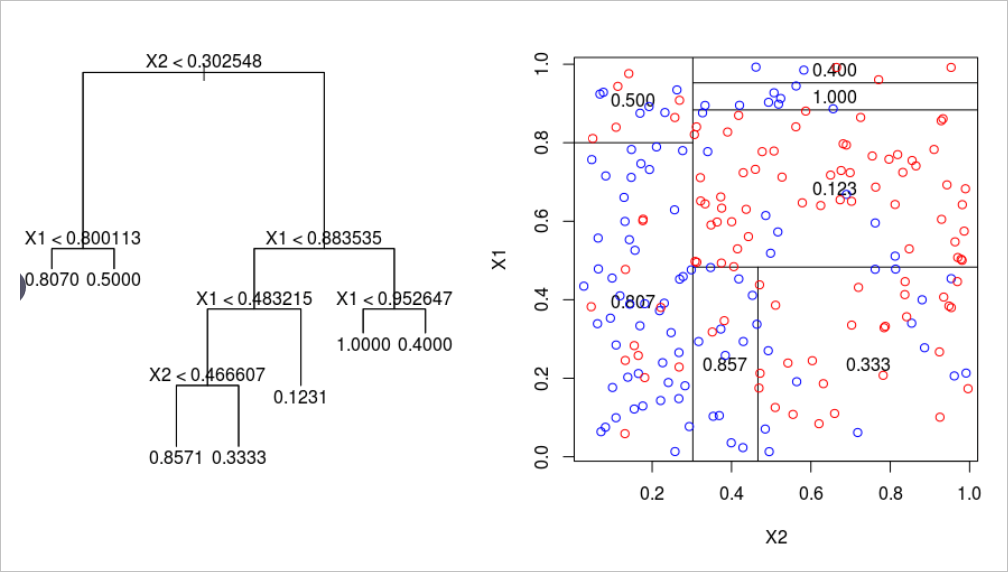
因此,可以通過更嚴格的激活來模擬沿特征線分割特征空間的類似方式,例如階躍函數,其中輸入是一個值或另一個值-本質上是分隔線。權重和偏差可能需要實施值限制,因此僅用于通過拉伸,收縮和定位來定向分隔線。為了獲得概率結果,可以通過激活函數傳遞結果。
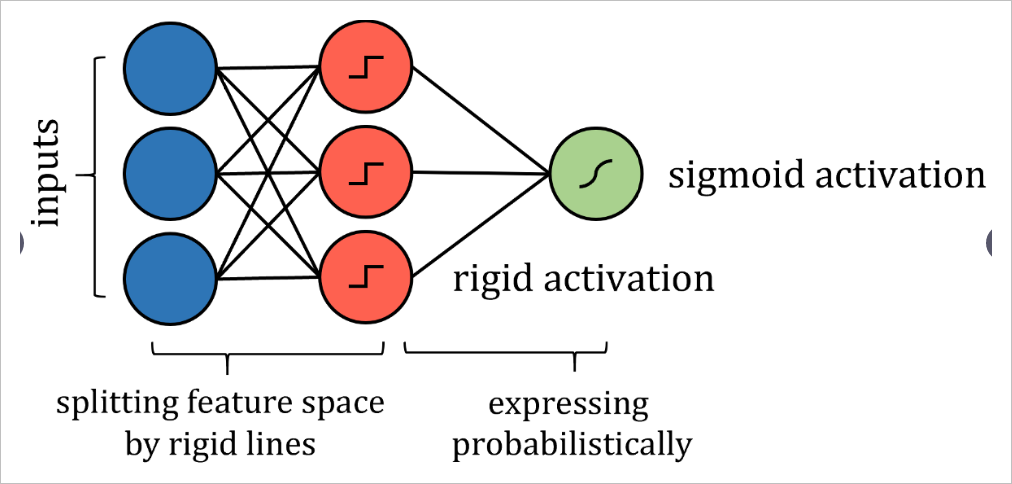
盡管算法的神經網絡表示與實際算法之間存在許多技術差異,但重點是網絡表達的思想相同,并且可以與實際算法相同的策略和性能來解決問題。
也許您不滿意將算法簡單地轉換為神經網絡形式,也許希望看到通用過程可以將所有棘手的算法都進行這種轉換,例如k近鄰算法或樸素貝葉斯算法等,而不是針對每個算法都手工進行轉換。
這種同樣算法轉換的答案就在于通用函數逼近定理,這也是在大量神經網絡工作原理背后的支撐數學原理。它的主要含義是:足夠大的神經網絡可以以任意精度對任何函數建模。
假設有一些函數 代表數據背后的規律:對于每個數據點 , 始終返回等于或非常接近 的值。
建模的目的是找到該內部映射關系 一個有效表示,我們將其記為預測函數 。所有機器學習算法對這個任務的處理方式都大不相同,采用不同用于驗證結果有效的假設條件,并給出具體算法來獲得最優結果 。這些獲得優化結果p(x)的算法,可說從在這些假設條件限制下,利用純粹的數學推導獲得。描述函數如何將目標映射到輸入的函數實際上可以采用任何形式,下面給出幾種典型的情況:

有的時候通過數學推導可以對表達式進行求解。但面對大量待定函數參數,往往需要通過不停的試湊來搜索。但是,神經網絡在尋找 的方式上有些不同。
任何函數都可以由許多類似階梯的部分合理地逼近,劃分的區間步數越多,逼近的精度就越高。
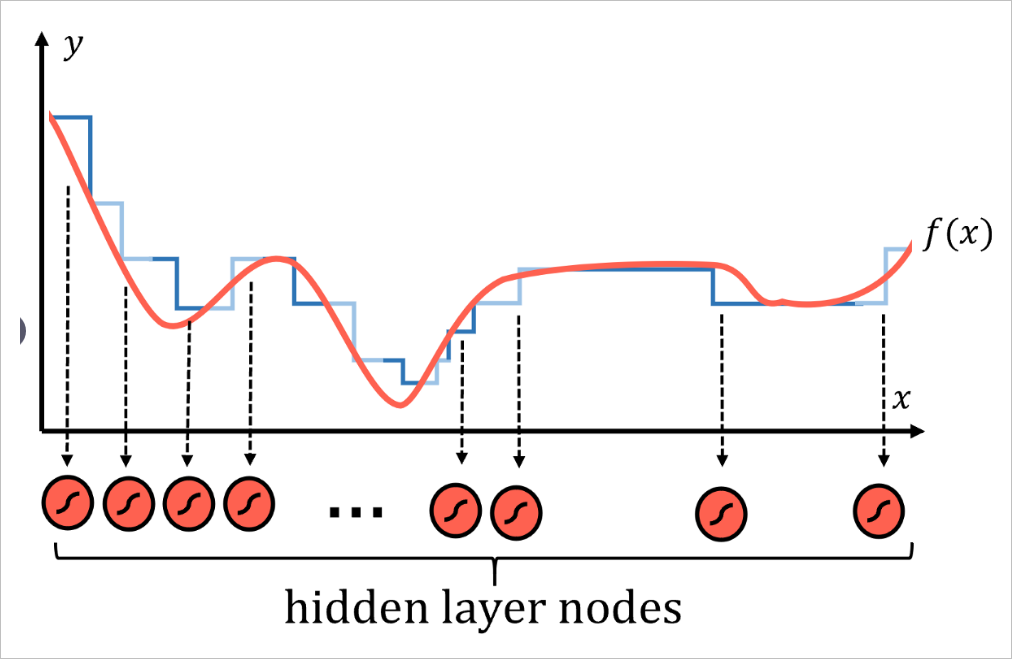
每一個區間都對應神經網絡中的一些節點,即隱層中具有S型激活函數的節點。激活函數本質上是概率階躍函數。實際上每個節點都代表函數 的一個局部。然后,通過系統中的權重和偏差,網絡為特定輸入來激活不同的神經元,使其輸出為1),否則輸出0。于是便可以將不同函數的局部最后合并成整個函數。
這種處理模式不僅對應上面的一維函數有效,在圖像中也觀察到了這種通過激活不同節點以尋找數據中特定的模式。
通用逼近定理已擴展為適用于其他激活函數(如ReLU和神經網絡類型),但原理仍然適用。神經網絡是實現通用逼近定義的最佳表現形式。
相對于通過復雜方程和關系數學形式來描述通用逼近定理,神經網絡則通過構建特殊的網絡結構,并通過訓練數據來獲得結構中的參數。這個過程就好像是通過蠻力記憶將函數存儲在網絡中。這個匯集眾多節點的網絡結構,通過訓練過程來逼近任意函數過程就表現出具有某種聰明特征的智能系統了。
基于以上假設,神經網絡至少可以在理論上構造出一個函數,該函數基本上具有所需的精度(節點數越多,近似值越準確,當然不考慮過擬合的技術性),具有正確結構的神經網絡可以對任何其他機器學習預測函數進行建模,反過來,其他任何機器學習算法,都不能這么說。
神經網絡使用的方法并不是對一些現有的優化模型,比如多項式回歸或者節點系統,只是對少量參數進行優化,它是直接去逼近數據內部所蘊含的規律,而不是基于某種特定的模型來描述數據。這種理念是那些常見到的網絡模型結構與其它機器學習之間最為不同之處。
借助神經網絡的力量以及對深度學習的不斷延伸領域的不斷研究,無論是視頻,聲音,流行病學數據還是兩者之間的任何數據,都將能夠以前所未有的精度來進行建模。神經網絡確實可以被成為算法之算法。
責任編輯:haq
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100721 -
機器學習
+關注
關注
66文章
8408瀏覽量
132576
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論