 做芯片要軟硬結合
做芯片要軟硬結合
2016 年,第一顆基于可重構計算的人工智能芯片誕生于清華。該成果曾發表在《IEEE 固態電路期刊》,《麻省理工科技評論》也報道過該芯片。
這是清華可重構計算實驗室 “十年磨一劍” 的成果。2006 年起,清華開始研究可重構計算并成立實驗室。
2018 年,該實驗室開始走向產品化,并成立清微智能公司。兩年來,公司已在語音識別、視覺識別等領域研發出規模化應用產品,并和阿里巴巴等互聯網巨頭建立合作。如今,清微智能將最新技術運用于 AI 編譯工具鏈中,并服務于其量產芯片 TX5 系列中,通過編譯優化,全球首款多模態智能計算芯片TX510 用于人臉識別時,其處理速度能夠提升一倍。
DeepTech 近日聯系到清微智能首席科學家、清華大學微電子與納電子學系教授尹首一,就該公司的主要產品、和他本人近日以通訊作者發表的新論文進行了深度交流。
自 2018 年以來,清微智能針對終端產品的語音和視覺兩大應用場景,量產出貨兩款芯片產品:超低功耗的智能語音 SoC 芯片 TX210,已應用至多款 TWS 耳機、電子產品及多種智能家居產品中;TX510 芯片于 2020 年 7 月實現量產,在金融支付、智能安防、工業機器人、航空等領域也已分批交付客戶,出貨量已超十萬片,并承擔多個國家重大項目的建設。
圖|TX 510 應用領域
以清微智能的 TX510 智能視覺芯片系列為例,該芯片的休眠功耗為 10uW、支持中斷喚醒,冷啟動下的人臉檢測識別時間小于 100ms,典型工作功耗為 350mW,算力達 1.2T (Int8)/9.6T (Binary),AI 有效能效比達 5.6TOPS/W。
TX510 還擁有可重構 AI 引擎,其支持 AlexNet、GoogleNet、ResNet、VGG、Faster-RCNN、YOLO、SSD、FCN 和 SegNet 等主流神經網絡,可實現人臉識別、物體識別和手勢識別等功能,適用于 AIoT、智能安防、智能家居、智能穿戴、智能制造等領域。
TX510 內置 3D 引擎,支持 3D 結構光、TOF(Time of flight,飛行時間)和立體視覺,誤識率千萬分之一的情況下識別率大于 90%。
在接口方面,TX510 支持市面上主流的視頻接口、存儲接口和通用接口,可保證產品兼容性。
盡管從硬件層面芯片性能已經取得了較大進步,但尹首一告訴 DeepTech,業界向來有一個共識,光有芯片架構還不夠,編譯工具和開發工具等軟硬件體系也必須做好。否則,很難完全把硬件功能的優勢發揮出來。
在軟件上面,其團隊已經有新進展。
做芯片要軟硬結合
在近日的第 16 屆 ACM/IEEE 國際嵌入式系統會議 上,清華微電子所魏少軍、尹首一教授團隊的論文《面向神經網絡處理器的非規則網絡結構高效調度技術》(“Efficient Scheduling of Irregular Network Structures on CNN Accelerators”) 獲得最佳論文獎。
尹首一表示,這是中國完成單位首次在 AI 編譯優化領域獲得國際學術會議最佳論文獎。該研究成果填補了大規模、非規則神經網絡編譯映射這一技術空白,可大幅提升神經網絡處理器的計算性能。
該成果解決的痛點在于,隨著 AI 算法的不斷普及,以 AIoT 為代表的嵌入式系統應用,給 AI 芯片的性能、功耗、成本、可靠性和可編程性等提出了嚴格且迫切的需求。為此,基于可重構架構、專用指令集架構、存內計算架構等技術的神經網絡處理器應運而生。
相比 CPU/GPU 等傳統架構,神經網絡處理器可將 AI 算法的計算能效提高 1~2 個數量級,目前其已在移動設備、可穿戴設備、智能傳感器等應用場景中獲得廣泛的應用。
但是,神經網絡處理器的應用離不開編譯器的支撐,編譯器一方面實現了 AI 應用到芯片的自動化部署,另一方面通過優化算法到芯片架構的適配,能為 AI 應用的執行效率帶來大幅提升。
當架構設計經過工藝制造并固化為硬件電路后,硬件電路的運算行為則由編譯器所生成的機器碼來指揮,執行速度和能量開銷也將因此而確定。因此,編譯器的優化程度是研發 AI 芯片的關鍵所在。
然而,當前最先進的神經網絡模型,仍舊具備不可預測的非規則網絡拓撲結構,在編譯層面表現為錯綜復雜的數據流圖、和呈指數增長的解空間,而這給編譯器中的表達式優化、算子調度、資源分配、循環優化、自動代碼生成等關鍵技術環節帶來嚴峻挑戰。
現有的深度學習編譯框架,如 TVM、TensorRT 等僅針對網絡中的某些特定模式進行優化,它們沒有處理任意結構的能力,因此未能有效解決上述難題。
針對上述問題,魏少軍、尹首一團隊在本次研究中,研發出支持任意網絡拓撲結構的端到端深度學習編譯框架(下稱編譯框架),相比同類編譯映射方法實現了 1.41-2.61 倍的計算加速。
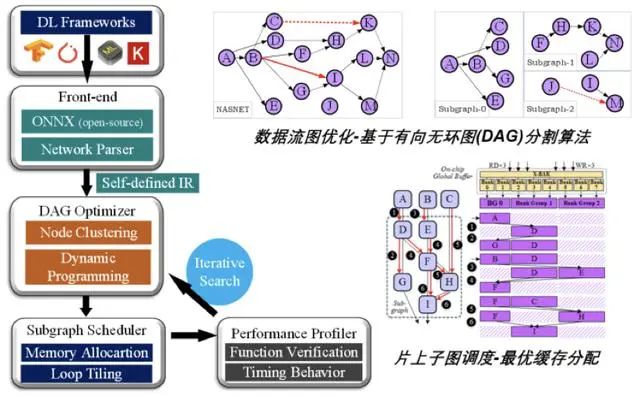
圖|支持任意網絡拓撲結構的端到端深度學習編譯框架
具體來說,本次編譯框架有三大創新性技術貢獻點。
第一, 針對結構復雜的數據流圖,提出了基于計算節點深度聚類的編譯方法,該方法可對圖結構進行復雜度降維和搜索路徑生成,進而可求解到具備全局最優特性的圖調度方案,在硬件處理器上表現為多級存儲系統間的數據傳輸開銷、與額外計算開銷之間的最佳平衡,即推理計算性能達到最優;
第二,針對非規則網絡結構導致的解空間指數增長,提出了一種基于回溯搜索和參數匹配的啟發式資源分配方法,并對神經網絡基本算子在時空域上的分布進行聯合優化,從而實現硬件層面上處理器緩存資源利用率最大化;
第三,針對新型網絡結構的循環優化問題,該團隊推導得出最小循環變換粒度,并在編譯框架中建立了最優陣列映射機制,使得嵌套循環的運算與計算資源達到最優匹配。
由于該編譯框架的優化方法具備通用性,因此它也能用于專用神經網絡處理器以外的其他架構。
對于研究該問題的初衷,尹首一表示,這來自該團隊親身經歷的痛點。過去,在開發神經網絡處理器時,人們往往只考慮到處理單元陣列的搭建和底層的數據復用等問題。而對于神經網絡算法編譯,由于當時的模型結構簡單、調度空間有限,僅僅采用常規編譯優化就已足夠。
然而,在面對近年來基于神經架構搜索(NAS)等方法所生成的復雜網絡結構時,之前的設計范式不再能提供具備接近最優性能的解決方案,從而大大制約了算力的發揮。因而該團隊認識到,必須要有針對性的軟件編譯工具,才能對新型 AI 應用進行充分的優化和加速。
尹首一告訴 DeepTech,在編譯方面他們并非 “新人”。他和團隊十多年來一直研究通用可重構處理器編譯問題,已具備較為深厚的研究基礎,因而在面對神經網絡編譯這一新問題時,能迅速把握問題本質,從而得以快速完成研究。
據他介紹,目前由其擔任首席科學家的清微智能,已經將該論文的技術發明運用在 AI 編譯工具鏈中,并已服務于量產芯片 TX5 系列中。對終端客戶而言,這意味著可用同樣的費用買到更多的算力。例如,通過編譯優化,TX510 芯片用于人臉識別時,其處理速度能夠提升一倍。
目前,清微智能的 AI 編譯工具鏈還在不斷升級優化中,旨在使實際運行中的神經網絡處理器逼近其理論算力上限。
AI 芯片公司應 “軟硬” 結合
尹首一認為,和所有初創公司一樣,AI 芯片企業要想構建成功的商業模式,在市場競爭中站穩腳跟,就得扎實細致地研究客戶實際需求。
當前,AI 芯片的客戶多數是整機和應用開發相關企業,這類客戶主要面向算法和應用來開發神經網絡模型,他們急需的是將生成的模型、便捷高效地在硬件設備上進行部署,因此他們不太關心硬件的底層架構和編譯細節。
但是,芯片公司光有先進的硬件和架構是不夠的,因為這無法讓客戶快速用起來,也無法將硬件算力轉化為可觀的計算性能。這時,AI 芯片公司就得提供軟硬件全棧式解決方案。參照英偉達在圖形加速領域的成功經驗,有兩點值得其他公司學習:其一是先進的 GPU 硬件架構,其二則是 GPU 開發工具鏈的成熟和完善。
目前,尹首一把主要精力集中在前沿研究上,這些研究成果不斷支撐著產品的競爭優勢。以清微智能 AI 編譯工具鏈為例,它集成了模型自動量化、定點訓練、通用算法計算和網絡調度映射等多方面的先進技術,可高效處理神經網絡和及其他 AI 算法,并且兼容主流的深度學習框架,因而實現了從應用算法、到可重構計算硬件的端到端部署。
通過這套 AI 工具鏈,開發者可在不改變編程習慣的情況下,快速高效地部署 AI 算法。以已經量產出貨的視覺智能芯片 TX510 為例,開發者可以僅僅通過調用功能級 API,就實現包含剪枝參數和權值位寬參數在內的最優模型壓縮策略,以及包括數據流圖優化、算子時空域映射在內的最優調度結果。
尹首一最后總結到,和操作系統一樣,編譯器也是核心基礎軟件,它是一切可編程芯片的靈魂,應當受到國內公司的更多重視。做 AI 芯片的公司,應當從開發伊始就對軟硬件兩方面的技術路線進行充分布局,這樣才能走得更遠。
-End-
原文標題:AI芯片公司,架構、編譯兩手都要硬!搭載清華最新深度學習編譯研究成果的芯片已商用
文章出處:【微信公眾號:DeepTech深科技】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
芯片
+關注
關注
456文章
50910瀏覽量
424514 -
AI
+關注
關注
87文章
31042瀏覽量
269391 -
人工智能
+關注
關注
1792文章
47378瀏覽量
238882
原文標題:AI芯片公司,架構、編譯兩手都要硬!搭載清華最新深度學習編譯研究成果的芯片已商用
文章出處:【微信號:deeptechchina,微信公眾號:deeptechchina】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
芯片為什么要進行封裝?
瑞薩電子與吉利汽車聯合舉辦汽車主控芯片軟硬解耦能力提升訓練營

結合芯片行業現狀,數字芯片設計什么方向最值得投身?

地平線征程家族出貨量突破700萬
使用NE555芯片做MOS管延時的控制芯片,帶載啟動的時候,定時器工作在打嗝狀態,MOS管不能正常打開,怎么解決?
香橙派與昇思MindSpore合作提速,軟硬結合助力開發者構建創新AI應用

Orin芯片與邊緣計算結合
線路板廠一文詳解PCB軟硬結合板優缺點
紫光同芯重磅發布兩款芯片,未來重點布局人工智能等領域

激光焊錫技術在R-FPC線路板制造領域的應用


官宣10家首批量產合作車企,地平線征程6發布即爆款







 工商網監
工商網監
評論