") 科學家發(fā)現:人工智能可根據照片內容識別攝影師身份
科學家發(fā)現:人工智能可根據照片內容識別攝影師身份
在日常生活中,我們經常會看到一些十分漂亮、構思精妙的照片,但某張照片背后的攝影師是誰?我們有時卻并不清楚。
在一項新的國際跨學科研究中,研究人員通過使用人工智能算法分析近 60000 張二戰(zhàn)時期的歷史照片發(fā)現,人工智能可以根據照片內容來識別攝影師的身份。相關研究成果以論文的形式發(fā)表在科學雜志 IEEE Access上。
研究人員展示了使用現代神經網絡分析圖像的優(yōu)勢,以使機器可以自動檢測各種場景中的人和物體,甚至可以根據圖像中的特征區(qū)分攝影師,這些操作比任何人工檢查過程都要快得多。獲得的結果將有助于歷史學家、其他研究人員和專業(yè)人員在工作中使用歷史照片檔案來分析和比較特定攝影師的作品。
通過這項工作,研究人員證明了人工智能可以在某些方面幫助學者“追溯”歷史照片檔案的潛力。
令人驚訝
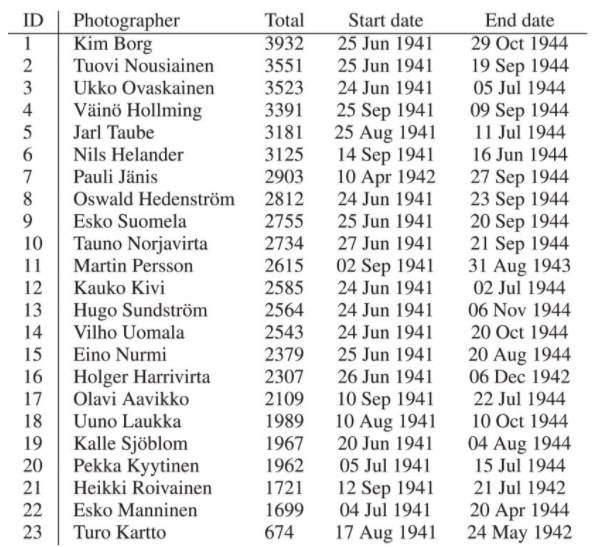
研究人員選擇了 23 名芬蘭戰(zhàn)地攝影師作為實驗對象。他們中的 20 人是芬蘭戰(zhàn)時照片檔案中圖像總數最高的攝影師,另外 3 人則是因為有專家認為他們的照片對這項攝影新聞研究很有趣。
他們提出并評估了機器學習可以幫助分析歷史圖像的幾個應用領域,即分析場景中存在的對象、照片取景評估、攝影師分類以及評估它們的視覺相似性。
他們使用人工智能技術對這 23 位著名芬蘭攝影師在第二次世界大戰(zhàn)期間拍攝的照片進行了識別,所用照片來自公開可用的芬蘭戰(zhàn)時照片檔案庫,其中包含約 160000 張 1939-1945 年間從芬蘭冬季戰(zhàn)爭、延續(xù)戰(zhàn)爭(第二次世界大戰(zhàn)期間芬蘭與蘇聯之間的兩場戰(zhàn)爭中的第二場戰(zhàn)爭)和拉普蘭戰(zhàn)爭中拍攝的照片。
由于芬蘭戰(zhàn)時照片檔案中的數千張照片仍然沒有攝影師的名字,所以這項研究中選用的照片總數為 59000 多張。
這種自動分析可以作為一種工具,以提供基于內容的公共照片檔案的文本描述,比如丹麥抵抗博物館的照片檔案。今年 9 月生效歐盟可訪問性指令(DIRECTIVE(EU)2016/2102),要求將圖像內容的文字描述添加到網絡上的所有公共圖像中。
對此,論文作者之一 Alexandros Iosifidis 表示:“這讓我們非常驚訝,人工智能可以根據照片中的特征(如內容和框架)識別攝影師。”
準確率最高可達 69.7%
在這項研究中,研究人員應用了最先進的目標檢測模型和神經網絡體系結構,以獲得來自杰出二戰(zhàn)攝影師的統計數據和特征。
由于每個攝影師都有一定數量的重復圖像,這里研究人員根據拍攝時間將照片分成訓練集和測試集,以確保描述同一事件的照片不會用于訓練和測試。
研究中分析的照片顯示,一些攝影師具有非常獨特且容易識別的特征,而另一些則很難被人工智能識別。這一人工智能模型的分類準確率區(qū)間為 20.1-69.7%,平均為 41.1%。
通過將識別結果與先前對檢測到的物體的分析進行比較發(fā)現,一些攝影師因為有著特定的拍攝物體和喜好很容易被識別。因此,研究人員檢查了每個攝影師照片中的典型物體類別,并分析了他們捕捉和框定人的方式差異。
Roivainen 拍攝的照片中擁有最多的狗、馬和汽車,預測準確率為 69.7%;Hollming 拍攝了大量滑雪照片,所有照片中只有幾把椅子出現,即戶外照片多,預測準確率為 51.4%;Manninen 拍攝的人物照片中的平均人數最高,椅子(即室內照片)出現率最高,預測準確率為 35.5%;SJ Blom 喜歡在城市環(huán)境中拍攝照片,預測準確率為 50.4%。
研究結果證明,除了確定照片的作者身份之外,這些特征代表了模型對這些攝影師的整體視覺相似性和照片風格相似性的認知。此外,由于卷積神經網絡可以在一定程度上從照片中識別攝影師,某些照片可以被認為是特定攝影師的典型。其中最著名的攝影師是 Heikki Roivainen,他是芬蘭植物學教授,曾在延續(xù)戰(zhàn)爭期間擔任官方戰(zhàn)地攝影師。
通往更多應用的大門
在這項工作中,研究人員只使用了可公開獲得的預處理對象檢測模型和基本照片信息,但他們認為這一模型可用于大多數照片檔案,且提供了所有代碼、模型和數據注釋,以及如何使用它們的詳細描述。
例如,可以通過考慮攝影師的意圖和他們的照片質量來進一步增強攝影師分析。此外,可以通過考慮信息融合方法來增強對象檢測性能,以及改善較小尺寸對象的檢測。除了對象級分析,場景識別將有助于進一步描述攝影師的特征。
在未來,研究人員將專注于需要更專業(yè)方法的問題,比如識別僅出現在芬蘭歷史照片或二戰(zhàn)期間的對象類別。他們的目標是利用原始的文本照片描述來產生更完整的對象標簽以及主題和事件識別。
這將有助于人們解決分析戰(zhàn)時照片時面臨的最大挑戰(zhàn)之一,即區(qū)分拍攝對象的不同狀態(tài)——照片中的人是活著的、受傷的還是死亡的。
這些更精細的結果最終可以幫助人們更詳細地描繪出傳統知識攝影師的目標、素質和性格。這項研究的目標是在檔案中公布所有的結果,以幫助對檔案進行不同類型的社會研究。
對于此次研究結果,作者之一、從事新聞攝影研究已有 25 年以上的 Anssi M?nnist? 認為,“對照片蘊含的內容進行大數據分析是我的一個長期夢想,我對這個項目的結果非常著迷。人工智能可以識別諸如照片中的框架和內容的各個方面,這將在人文科學和社會科學領域中有著廣泛的應用。”
責編AJX
-
算法
+關注
關注
23文章
4608瀏覽量
92844 -
人工智能
+關注
關注
1791文章
47208瀏覽量
238290 -
照片
+關注
關注
0文章
15瀏覽量
9597
發(fā)布評論請先 登錄
相關推薦
嵌入式和人工智能究竟是什么關系?
《AI for Science:人工智能驅動科學創(chuàng)新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創(chuàng)新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創(chuàng)新》第二章AI for Science的技術支撐學習心得
《AI for Science:人工智能驅動科學創(chuàng)新》第一章人工智能驅動的科學創(chuàng)新學習心得
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創(chuàng)新
FPGA在人工智能中的應用有哪些?
中國科學家發(fā)現新型高溫超導體
圖像識別屬于人工智能嗎
前OpenAI首席科學家創(chuàng)辦新的AI公司
本源量子參與的國家重點研發(fā)計劃青年科學家項目啟動會順利召開

嵌入式人工智能的就業(yè)方向有哪些?

谷歌DeepMind科學家欲建AI初創(chuàng)公司
飛騰首席科學家竇強榮獲 “國家卓越工程師” 稱號






 工商網監(jiān)
工商網監(jiān)
評論