


近日,第29屆國際計算機學會信息與知識管理大會(CIKM 2020)在線上召開,CIKM是CCF推薦的B類國際學術會議,是信息檢索和數據挖掘領域頂級學術會議之一。
本屆CIKM會議共收到920篇論文投稿,其中錄用論文193篇,錄取率約為21%。 而在眾多論文當中,一篇BOSS直聘和中國人民大學聯合發表的基于多視圖協作學習的人崗匹配研究吸引了我們的注意力。

論文題目:《Learning to Match Jobs with Resumes from Sparse Interaction Data using Multi-View Co-Teaching Network》。 論文鏈接:https://arxiv.org/abs/2009.13299 本論文針對求職者和招聘方的交互行為數據稀疏且帶有噪聲這一場景,基于多視圖協作學習,提出了一個新型匹配模型。 新型模型相比以往模型,增加了基于關系的匹配模塊,且將兩個匹配模塊融合進行協作訓練,優化了該場景下的人崗匹配效率。 CIKM大會評審反饋,該論文提出的多視圖協作學習網絡能夠解決人崗匹配系統的負樣本噪聲問題。同時,融合文本匹配模塊和關系匹配模塊進行的聯合表示學習有助于解決雙邊交互行為數據稀疏問題,突破了以往匹配模型需要大量有效樣本數據的限定條件。而該思路對于互聯網求職招聘場景以外領域的推薦系統研究也有一定指導意義。
1
背景介紹
近年來,隨著以BOSS直聘為代表的移動互聯網求職招聘平臺的興起,人崗匹配任務越來越受到學術界的關注。 針對該問題,常見的方法是將其轉化為一個有監督的文本匹配任務來解決,當標記樣本足夠充分時,此類方法往往能取得較好的效果。 然而,在真實的互聯網求職招聘平臺上,求職者和招聘方的交互行為數據往往是稀疏且帶有噪聲的,這嚴重影響著匹配算法的性能。 因此,本文提出了一種基于稀疏交互數據的多視圖協作學習模型,并將其應用于人崗匹配任務,取得了較好的效果。 該方法的思路如下: 我們設計了一種全新的匹配模型,包含基于文本的匹配模塊和基于關系的匹配模塊兩部分,這兩部分能捕獲不同視角下的語義信息,并相互補充。 此外,為了解決交互行為數據稀疏的問題,我們設計了兩種特定訓練策略來更好地融合這兩個匹配模塊: 一方面,兩個模塊共享學習參數和表示,可以增強每個模塊初始的表示; 另一方面,我們采用了一種協作學習的機制來減少噪聲數據對訓練的影響。核心思想是讓這兩個模塊通過選擇更置信的訓練實例來互相指導訓練。 這兩種策略可以更好地用于表示的增強和數據的增強。 與單純基于文本的匹配模型相比,我們所提出的方法能夠從有限甚至稀疏的交互數據中更好地學習數據的表示,在帶有噪聲的訓練數據上該方法也更具魯棒性。
2
問題定義
對于人崗匹配任務,給定職位文本數據集合

和簡歷文本數據集合

,以及匹配結果集合
。 其中,每一個職位j或簡歷r均由多句描述職位或簡歷的文本構成, 代表簡歷和職位是否匹配。根據上述定義,我們的任務是學習一個預測函數
代表簡歷和職位是否匹配。根據上述定義,我們的任務是學習一個預測函數
來預測未知的職位簡歷對的匹配結果。
3
方法描述
多視圖協作學習的人崗匹配模型圖 為了解決在線求職招聘場景下由于交互數據稀疏和采樣負例而帶來的噪聲問題,我們提出了一種基于多視圖協作學習的人崗匹配模型。
基于文本的匹配模塊近年來,基于預訓練語言模型的方法在各種自然語言處理任務上均取得了不錯的效果。 鑒于此,這里采用BERT編碼簡歷和職位的每一個句子表示,然后使用Transformer編碼表示整篇文檔表示。

j和r分別代表職位和簡歷文檔,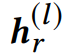 和分別代表第層的輸入簡歷和職位的向量。
和分別代表第層的輸入簡歷和職位的向量。

最后將職位表示和簡歷表示拼接后再接一個Sigmoid層輸出得到的 作為候選簡歷和職位的匹配分。
作為候選簡歷和職位的匹配分。
基于關系的匹配模塊前文所述的匹配模塊主要關注文本語義上的匹配,但由于顯式交互數據是相對稀疏的,因此挖掘潛在的隱式關聯將有助于抽取出更多額外信息作為補充。 為此我們設計了基于關系的匹配模塊,該模塊包含構造職位-簡歷關系圖和學習職位簡歷的表示兩部分。構造職位-簡歷關系圖首先定義職位-簡歷關系圖

。其中,

代表職位和簡歷兩類節點,

代表關系集合。 由于有職位和簡歷兩類節點,所以共包含三種連接類型,即職位-職位,職位-簡歷和簡歷-簡歷。同時,采用如下兩種數據信號來刻畫節點間的連接關系:第一類是相同領域標簽的職位或者簡歷之間構建連接關系;第二類是根據職位描述或簡歷文本中抽取出的關鍵詞,職位或者簡歷之間出現了同樣的關鍵詞構建連接關系。職位簡歷的表示學習基于職位-簡歷關系圖,可以進一步捕捉圖上潛在的語義信息來學習節點上的特征表示(即職位和簡歷)。 圖神經網絡近年來已經成為學習圖節點特征表示的最流行的方法,由于在職位-簡歷關系圖中存在大量不同類別的關系連接,為了更好刻畫在這類帶有豐富關系的圖結構,這里采用關系圖卷積網絡(Relational Graph Convolutional Network)來刻畫不同關系和節點的表示。 第l層的節點學習到的表示的公式如下:


代表了第l層節點的表示, ?代表節點
?代表節點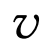 的鄰接節點集合。由于每一種關系t對應一個特定的參數矩陣
的鄰接節點集合。由于每一種關系t對應一個特定的參數矩陣 ,所以能夠基于關系的語義信息學習到節點的表示。 通過在圖上學習的節點表示,最終得到簡歷和職位的表示,與之前的方法類似,通過拼接簡歷表示和職位表示計算最終匹配分。
,所以能夠基于關系的語義信息學習到節點的表示。 通過在圖上學習的節點表示,最終得到簡歷和職位的表示,與之前的方法類似,通過拼接簡歷表示和職位表示計算最終匹配分。

多視圖的協作學習網絡接下來將介紹所設計的多視圖協作學習網絡,以及如何將基于文本和基于關系的匹配模塊集成到統一的訓練方法中。 首先,網絡會共享學習到的信息和參數,以增強每個模塊的原始表示;其次,針對如何減少訓練數據對噪聲的影響,我們借鑒了機器學習中協同學習的思想,通過選擇更可靠的訓練實例來讓這兩個組件相互幫助。接下來,介紹這兩種策略的細節。表示增強由于在匹配過程中包含文本表示和關系表示兩類表示方法,為了在初始表示學習的過程中互相增強,在初始學習文本模塊的表示時會拼接關系圖上節點的表示。

類似地,為了增強圖關系上節點的表示,會采用文本模塊學習到的表示作為關系圖訓練時的初始表示。
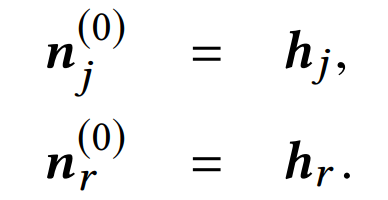
利用協作學習的數據增強這里的基本假設是,真實樣本通常在不同的模型視角下會得到相似的預測結果,而噪聲數據則會在不同視角下表現得不穩定。 在協作學習網絡中,文本匹配模塊和關系匹配模塊可以視為兩個對等的learner。用于訓練一個learner的樣本首先由另一個learner進行檢查,并且僅將標記為高置信度的實例保留在訓練過程中。 由于這兩個learner從不同視角對數據建模,學習的策略有所不同,因此他們可以互相幫助選擇高置信度的訓練樣本,從而提升模型效果。 具體訓練方法如下圖所示:

提出的co-teaching的算法流程圖 這里具體提出了兩種實現策略。(1)實例的重加權給定一個模型,其對等模型目的是在不同視角下,增加高置信度樣本的權重并降低不可靠樣本的權重。例如,對于模型B,假設在訓練過程中的一個batch中有K個實例。

讓其對等模型A為這個K個實例分配權重。其核心想法是根據樣本真實標簽信息與A的預測之間的一致程度對實例賦予權重:

這里的權重越高代表了該實例越可信。同時將這些權重結果傳遞給模型B并讓其進行模型參數的更新。(2)實例的篩選過濾除了對不同樣本重新加權外,還可以直接篩除相對較差的實例。直觀地,如果實例對應的損失較小,則它離決策邊界很遠,更有可能是可靠的樣本。可以通過以下公式建模:
實例重加權和篩選過濾方法都旨在為模型學習選擇更可靠的樣本。他們用不同的方法達到這個目的。 實例重新加權是一種相對“軟”的方法,其所有實例均保留,只不過不同實例具有不同的重要程度。而實例篩選過濾是一種相對“硬”的方法,會直接丟棄一些樣本。還有一種思路是通過在對樣本重新加權之前對樣本進行過濾來將這兩種方法結合起來。
4
實驗結果
數據集介紹本文基于在線招聘平臺BOSS直聘的數據集進行相關實驗。該數據集包括三個領域類別,便于測試我們的模型在不同領域下的穩定性。 表1總結了處理后的數據統計信息,可以看到:(1)所有數據集都很稀疏,無論是達成匹配或拒絕;(2)不同領域下的數據稀疏程度有所不同。例如,技術類規模較大但較稀疏,而銷售相對稠密;(3)對于每個領域類別,發生顯示拒絕(即不匹配)的數量要比達成匹配的數量少得多。
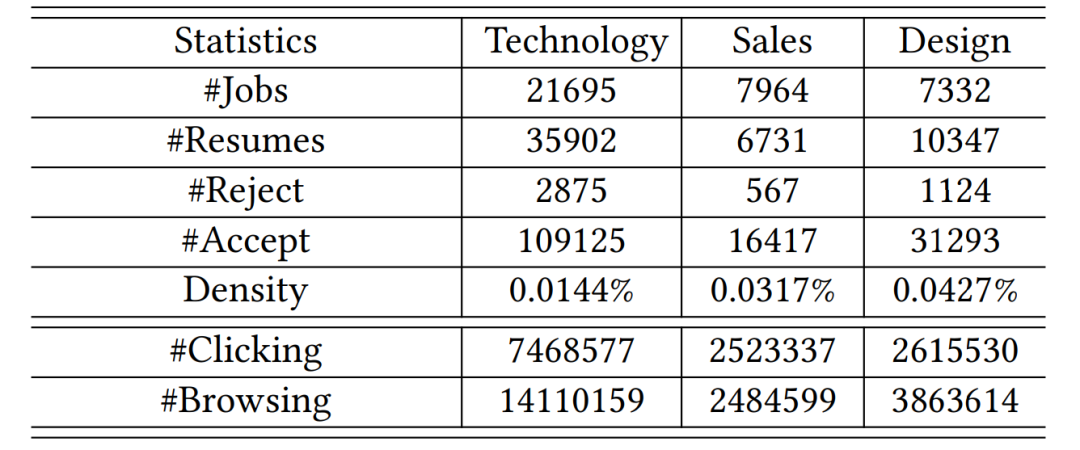
表1:數據集的統計信息
實驗結果對比方法1、DSSM [1]提出的深度結構語義匹配模型。 2、BPJFNN [2]提出的基于循環神經網絡的匹配模型。 3、PJFNN [3]提出的基于卷積神經網絡的匹配模型。 4、APJFNN [2]提出的基于層級注意力機制的匹配模型。 5、DGMN [4]提出的基于全局句子粒度交互的匹配模型。 6、JRMPM [5]提出的引入歷史交互作為記憶模塊的匹配模型。 7、UBD [6]用來解決噪聲數據帶來的影響,采用分歧的思想對分類器雙方產生不同結果的數據進行參數更新。 8、NFM [7]使用神經因子分解機來學習高階交互,使用文本和ID特征作為輸入。

表2:主實驗的結果 根據表2中的實驗結果,結論如下:1、首先,NFM很難在我們的任務上取得良好的效果。原因是該任務比傳統推薦場景數據更加稀疏;同時,DSSM在大多數情況下表現不佳,因為它無法捕獲文本信息中的時序信息;BPJFNN、PJFNN、APJFNN、JRMPM和DGMN之間的性能差異很小,并且針對不同指標或不同領域會有微小差別;此外,UBD是唯一訓練時解決噪聲問題的baseline,與其他baseline方法相比,該方法的效果有顯著提升,這也側面證實了該任務下處理噪聲數據的必要性。2、我們提出的模型在不同數據集的所有指標上均獲得了最佳性能。與其他方法相比,模型中的協作學習機制能夠識別更多信息量豐富且更可靠的樣本來學習參數,也更容易削弱噪聲數據帶來的影響,因此優于其他baseline方法。3、對比篩選過濾和重加權這兩種策略,我們發現后者在大多數情況下更優異。可能因為重新加權策略采用了“軟”降噪的方法,該方法在處理噪聲數據時會更魯棒。 除了上述主實驗結果分析外,我們也同時分析了不同模塊組件對最終效果的影響。 如表3所示,這里T代表文本匹配模塊、R代表關系匹配模塊、C代表協作學習網絡。 結果表明,所有這三個組件對提高人崗匹配的性能都有正向作用。尤其是文本匹配模塊和協作學習網絡給模型帶來的提升較大。 此外,一個有趣的觀察是,簡單地融合多視圖的數據可能不會導致良好的性能(即TR

表3:消融實驗結果
5
總結
本文提出了一種基于多視圖協同教學網絡,該網絡能夠在交互行為數據稀疏且帶有噪聲這一場景下進行學習,以進行人崗匹配。我們考慮融合文本匹配模塊和關系匹配模塊進行的聯合表示學習,該方法能夠結合各自模塊的優勢來更好的學習匹配表示。同時我們設計了兩種特定訓練策略來更好地融合這兩個匹配模塊,即表示增強和數據增強。一方面,兩個模塊共享學習參數和表示,可以增強每個模塊初始的表示; 另一方面,我們采用了一種協作學習的機制來減少噪聲數據對訓練的影響。大量實驗表明,與以往的方法對比,該方法能夠從數據稀疏且帶有噪聲的交互數據中獲得更好的匹配效果。在本文中,我們聚焦于宏觀的交互行為,例如接受或拒絕面試邀請這樣的行為。然而一些微觀交互也會對匹配產生一定的影響,例如單擊或停留時間。未來我還將考慮將此類信息融入進來以設計一個更加全面的匹配模型。此外,我們還將考慮將我們的方法應用于更多的領域類別,研究不同類別之間的領域自適應問題。
參考文獻
[1]Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Conference on information and knowledge management, pages 2333–2338. ACM.
[2]Chuan Qin, Hengshu Zhu, Tong Xu, Chen Zhu, Liang Jiang, Enhong Chen, and Hui Xiong. 2018. Enhancing person-job fit for talent recruitment: An ability-aware neural network approach. In In Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR-2018) , Ann Arbor, Michigan, USA. [3]Chen Zhu, Hengshu Zhu, Hui Xiong, Chao Ma, Fang Xie, Pengliang Ding, and Pan Li. 2018. Person-job fit: Adapting the right talent for the right job with joint representation learning. ACM Transactions on Management Information Systems ACM TMIS. [4]Shuqing Bian, Wayne Xin Zhao, Yang Song, Tao Zhang, and Ji-Rong Wen. 2019. Domain Adaptation for Person-Job Fit with Transferable Deep Global Match Network. In EMNLP-IJCNLP 2019. 4809–4819. [5]Rui Yan, Ran Le, Yang Song, Tao Zhang, Xiangliang Zhang, and Dongyan Zhao. 2019. Interview Choice Reveals Your Preference on the Market: To Improve Job-Resume Matching through Profiling Memories. In KDD 2019. 914–922. [6]Eran Malach and Shai Shalev-Shwartz. 2017. Decoupling "when to update" from "how to update". In NeurIPS 2017. 960–970. [7]XiangnanHe and Tat-SengChua. 2017.Neural Factorization Machines for Sparse Predictive Analytics. In SIGIR 2017. 355–364.
責任編輯:xj
原文標題:【CIKM 2020】基于多視圖協作學習的人崗匹配研究
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
噪聲
+關注
關注
13文章
1140瀏覽量
48187 -
數據
+關注
關注
8文章
7259瀏覽量
92041 -
深度學習
+關注
關注
73文章
5562瀏覽量
122856 -
協作學習系統
+關注
關注
0文章
2瀏覽量
1662
原文標題:【CIKM 2020】基于多視圖協作學習的人崗匹配研究
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
機器學習賦能的智能光子學器件系統研究與應用

云知聲四篇論文入選自然語言處理頂會ACL 2025

基于LockAI視覺識別模塊:C++多模板匹配
基于LockAI視覺識別模塊:C++多模板匹配

SOLIDWORKS 2025教育版有效的數據管理與團隊協作
?多模態交互技術解析
美報告:中國芯片研究論文全球領先
OpenHarmony程序分析框架論文入選ICSE 2025
MVTRF:多視圖特征預測SSD故障

人員睡崗檢測 AI 算法攝像機

楊玉崗: 磁性元件行業如何尋找新出路?

協作機器人TM25S:高效人機協作改變傳統作業方式

經典圖神經網絡(GNNs)的基準分析研究

建筑物邊緣感知和邊緣融合的多視圖立體三維重建方法

使用語義線索增強局部特征匹配






 工商網監
工商網監

評論