 Lattice sensAI再獲重大更新
Lattice sensAI再獲重大更新
從家庭控制中智能門鈴和安全攝像頭的存在檢測,到零售應用中用于庫存的對象計數,再到工業應用中物體和存在檢測,越來越多的網絡邊緣應用正在不斷推動新型AI解決方案面市。根據IHS Markit(現Omida)的預測,2018-2025年物聯網設備數量將達到400億,截至2022年,所有企業產生的數據中近50%會在傳統數據中心或云端以外的地方進行處理。
但與此同時,市場一方面要求設計人員開發出性能比以往更高的解決方案;另一方面,延遲、帶寬、隱私、功耗和成本問題又限制了他們依賴云的計算資源來執行分析。如何解決系統對于日益嚴格的功耗(毫瓦級)和小尺寸(5mm2到100mm2)要求?如何能夠快速獲得相應的硬件和軟件工具、參考設計、演示示例和設計服務?萊迪思公司為此做出了有益的嘗試。
圖1 sensAI架構框圖
Lattice sensAI再獲重大更新
作為萊迪思推出的業界第一款用于網絡邊緣設備端AI處理的完整解決方案集合,sensAITM提供了供開發人員評估、開發和部署基于FPGA的機器學習/人工智能解決方案所需的全部資源,包括模塊化硬件平臺、演示示例、參考設計、神經網絡IP核、軟件開發工具和定制化設計服務。
2019年上半年,sensAI通過更新迎來10倍性能提升,這是由多個優化促成的,包括通過更新CNN IP和神經網絡編譯器、新增8位激活量化、智能層合并以及雙DSP引擎等特性。而最令人感到興奮的是它新增并優化了用于快速實現網絡邊緣常見AI應用的參考設計,為關鍵詞檢測、人臉識別、人員偵測、人員計數等賦予了更強大的特性。
圖2 在訓練過程中支持8位量化可在神經網絡模型訓練過程中實現更高的精度
為了演示關鍵詞檢測系統的功能,工程師使用了搭載iCE40 UltraPlus FPGA的HiMax HM01B0 UPduino shield開發板。該開發板有兩個直連到FPGA的I2S麥克風、用于FPGA設計的外部閃存、權重激活存儲器、以及LED指示燈用以指示是否檢測到關鍵詞。用戶可以直接對麥克風說話,一旦檢測到關鍵詞,LED就會亮起。
圖3 關鍵詞檢測演示系統
圖4左側是針對低功耗運行進行優化、采用CMOS圖像傳感器的人員偵測演示,通過VGG8網絡提供64 x 64 x 3的分辨率,該系統以每秒5幀的速率運行,使用iCE40 UltraPlus FPGA功耗僅為7mW;右側是性能經優化的人員計數應用演示,同樣也使用CMOS圖像傳感器,通過VGG8網絡提供128 x 128 x 3的分辨率。該演示以每秒30幀的速率運行,使用ECP5-85K FPGA功耗為850mW。
圖4 這些參考設計展示了sensAI提供的功耗與性能可選方案
Lattice人員識別參考設計方案也應用于售賣機上檢測人員的出現,喚醒售賣機的內核。通過減少非人員靠近造成的誤觸發,或人員路過造成的誤觸發,達到減小功耗的目的。
2020年5月,sensAI又成功升級至3.0版本。
在此前支持ECP5/ECP5-5G和iCE40 UltraPlus 模塊化硬件平臺的基礎上,新推出的sensAI 3.0版本支持CrossLink-NX系列FPGA,運行sensAI軟件的CrossLink-NX FPGA比之前版本降低了一半的功耗,同時實現性能翻倍,從而為監控/安防、機器人、汽車和計算領域的智能視覺應用帶來功耗和性能上的再次突破。同時,它還擁有定制化卷積神經網絡CNN IP并新增支持MobileNet v2、SSD和ResNet模型,這些靈活的加速器IP可簡化常見CNN網絡的實現,經優化后可更加充分利用FPGA的并行處理能力,開發人員可輕松編譯經過訓練的神經網絡模型并將其下載到CrossLink-NX FPGA中。
CrossLink-NX FPGA采用28nm FD-SOI工藝制造,與同類FPGA競品相比,功耗可降低75%。在CrossLink-NX FPGA上運行解決方案時,sensAI可提供多達2.5Mb的分布式內存、RAM塊以及額外的DSP資源,MIPI I/O提供瞬時啟動的性能可在不到3ms的時間內完成自我配置,而整個器件的配置也只需8ms。在基于CrossLink-NX的對象計數演示中,——基于VGG的對象計數演示擁有10幀/秒的性能,功耗僅為200mW。
圖6sensAI支持多種AI算法模型
當AI遇見超低功耗FPGA
擁有5K LUT的iCE40 UltraPlus FPGA可實現網絡邊緣實時在線的智能應用所需的神經網絡模式匹配。其擁有5280個4輸入LUT、自定義I/O、多達80Kb和1Mb的嵌入式存儲器,睡眠電流低至75uA,工作電流僅為1-10mA,功耗低至1mW,硬件平臺尺寸小至5.5mm2。為了滿足各類應用的需求,還采用了包括從專為電子消費品和IoT設備優化的超小尺寸2.15 mm x 2.50 mm x 0.45 mm WLCSP封裝,到低成本應用的0.5mm間距7x7mm QFN封裝在內的多種封裝選項。
功耗優化遙遙領先的原因,得益于其采用的分布式異構處理(Distributed Heterogenous Processing,DHP)架構。由于不使用云端執行算法,而是使用內置的數字信號處理器(DSP)執行重復的數字處理任務,因此大幅減少了功耗極大的應用處理器(AP)的計算負載,從而實現更長時間的睡眠模式以延長電池使用時間。另一方面,內置的神經網絡軟IP和編譯器實現了靈活的機器學習/人工智能應用,消除了云端智能應用帶來的延遲,降低了整個系統解決方案的成本。
圖7 iCE40 UltraPlus采用的分布式異構處理(DHP)架構
圖8和圖9描述了不同FPGA之間存在的資源差異如何影響到人臉檢測和人員檢測應用的性能和功耗。圖8左側的32x32輸入示例中,橙色部分代表卷積層上運行的周期。在四個示例中,UltraPlus的乘法器數量最少,其他三片ECP5 FPGA的乘法器數量依次遞增。隨著乘法器數量的增加,卷積層所需的周期數減少;右側的90x90輸入示例中,在每個柱形圖的底部有大面積的藍色區域。這是由于設計更為復雜,需要占用外部DRAM,性能就有所折中。
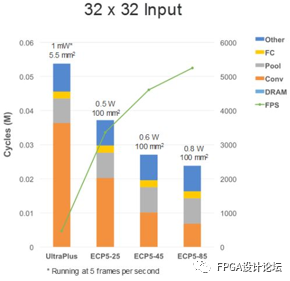
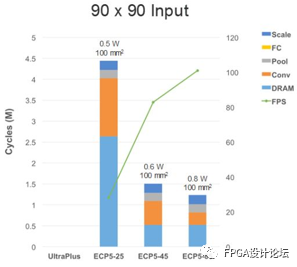
圖8 在UltraPlus和ECP5 FPGA上實現入門級和提高級人臉檢測時的性能、功耗和占用面積
人員偵測應用的情況類似,兩組分別采用了64x64輸入和128x128輸入的情況。同樣,較多的乘法器會減少卷積層的負擔,而依賴DRAM則會影響性能。
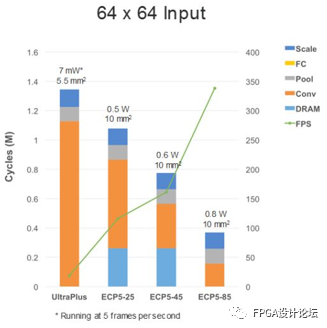
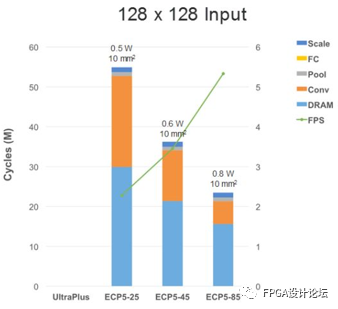
圖9 在UltraPlus和ECP5 FPGA上實現簡單和復雜人員檢測時的性能、功耗和占用面積
其實,設計AI模型的最常見做法就是使用處理器,可能是GPU或者DSP,也有可能是微控制器(MCU)。不過,低端MCU可能連簡單的AI模型也無法處理,高性能處理器又可能會違反設備的功耗和成本要求,但這正是低功耗FPGA發揮作用的地方。與增強處理器來處理算法的方式不同,萊迪思iCE40 UltraPlus FPGA可以作為MCU的協處理器,處理MCU無法解決的復雜任務之余,將功耗保持在要求范圍內。
另一種思路是將低功耗FPGA作為單獨運行的、完整的AI引擎,此時FPGA中的DSP就起到了關鍵作用。即便網絡邊緣設備沒有其他的計算資源,也可以在不超出功耗、成本或電路板尺寸預算的情況下添加AI功能,更何況它們還擁有支持快速演進算法所需的靈活性和可擴展性。
無論采取哪種方法,都意味著設計人員可以采用萊迪思sensAI以及一片低功耗的iCE40 UltraPlus FPGA對傳感器數據進行預處理,從而最大程度地降低了向SoC或云端傳輸數據進行分析的成本。例如,如果是用在智能門鈴上,sensAI會初步讀取來自圖像傳感器的數據。如果判斷為不是人,比如說是一只貓,那么系統就不會喚醒SoC或連接到云端作進一步處理。因此,這種方法可以最大程度降低數據傳輸成本和功耗。如果預處理系統判斷門口的對象是人,則喚醒SoC作進一步處理。這能極大減少系統需要處理的數據量,同時降低功耗要求,這對于實時在線的網絡邊緣應用來說至關重要。
圖10 基于iCE40 UltraPlus FPGA的sensAI會預處理傳感器數據以判斷該數據是否需要發送到SoC作進一步處理
結語:
萊迪思的FPGA具有獨特的優勢,可以滿足網絡邊緣設備快速變化的市場需求。設計人員可以在不依賴云端的情況下,快速為網絡邊緣設備提供更多計算資源的其中一個方法是使用FPGA中本身的并行處理能力來加速神經網絡性能。此外,通過使用針對低功耗運行而優化的低密度、小尺寸封裝FPGA,設計人員可以滿足新的消費和工業應用對功耗和尺寸的嚴格限制。
責任編輯:lq
-
FPGA
+關注
關注
1629文章
21731瀏覽量
603064 -
探測系統
+關注
關注
0文章
58瀏覽量
11265 -
機器學習
+關注
關注
66文章
8408瀏覽量
132581
原文標題:當AI遇到FPGA,低功耗智能探測系統不再是難題
文章出處:【微信號:gh_9d70b445f494,微信公眾號:FPGA設計論壇】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ADS6245EVM和Lattice ECP2/M接口演示用戶指南

Android 16發布計劃曝光,谷歌將同步更新AOSP與Pixel設備
PerfXCloud 重大更新 端側多模態模型 MiniCPM-Llama3-V 2.5 閃亮上架

Lattice MachXO3 Family默認IO上下拉配置
微軟推出Windows 11重大更新:強化Bug修復,全面升級功能體驗
微軟推出Windows 11的重大更新KB5040529
理想汽車推出其年度重大軟件更新OTA 6.0版本
xAI加速人工智能步伐,Grok系列大模型即將迎來重大更新
Lattice Avant-G FPGA的電源解決方案
日月光投控再獲蘋果重大訂單
特斯拉FSD頻繁更新,預計將實現78項重大改進
特斯拉FSD v12.3更新搭載全新神經網絡,實現重大突破
【基于Lattice MXO2的小腳丫FPGA核心板】02ModelSim仿真
持續為玩家帶來驚喜,英特爾銳炫再迎重大驅動更新






 工商網監
工商網監
評論