


視覺定位是自動駕駛和移動機器人領域的核心技術之一,旨在估計移動平臺當前的全局位姿,為環境感知和路徑規劃等其他環節提供參考和指導。國內知名互聯網公司-美團無人配送團隊長期在該方面進行深入探索,積累了大量創新性工作。不久前,視覺定位組提出的融合3D場景幾何信息的視覺定位算法被ICRA2020收錄,本文將對該方法進行介紹。
背景
1. 視覺定位算法介紹1.1 傳統視覺定位算法 傳統的視覺定位方法通常需要預先構建視覺地圖,然后在定位階段,根據當前圖像和地圖的匹配關系來估計相機的位姿(位置和方向)。在這種定位框架中,視覺地圖通常用帶有三維信息和特征描述子的稀疏關鍵點表示。然后,通過當前圖像與地圖之間的關鍵點匹配獲取2D-3D對應關系,利用PnP結合RANSAC的策略來估計相機位姿。其中,獲得準確的2D-3D對應關系對定位結果至關重要。近年來,許多工作為提高2D-3D的匹配精度進行了各方面的探索,但大多傳統方法[1,3,4]還是基于SIFT、SURF、ORB等底層特征,很難處理具有挑戰性(光照改變或季節改變)的情況。
1.2 深度學習視覺定位算法 最近幾年,融合神經網絡的視覺定位算法被廣泛研究,大家希望用神經網絡取代傳統方法中的部分模塊(例如關鍵點和描述子生成)或者直接端到端的估計相機位姿。本論文研究內容屬于對后面這種類型算法的優化。端到端視覺定位算法用神經網絡的權值來表征場景信息,網絡的訓練過程實現建圖,定位由網絡的推理過程實現。PoseNet[2]是第一個基于神經網絡的端到端視覺定位算法,它利用GoogLeNet的基礎架構直接對輸入的RGB圖像進行6DoF相機位姿回歸。在該思路的基礎上,后續的改進包括加深網絡結構、增加約束關系、融合時序信息和多任務聯合建模等,例如,[5]加入貝葉斯CNN來建模精度不確定性;[6]將網絡改為encoder-decoder結構;[7]和[8]引入了LSTM,利用視頻流的時間和運動平滑性約束網絡學習;[9]和[10]提出了多任務學習框架,聯合建模視覺定位、里程計估計和語義分割三個任務,以上的工作都取得了定位精度的提升。
1.3 研究目的及意義 在上述提到的優化方法中,雖然[9]和[10]在定位精度上表現的更有優勢,但是往往需要語義分割等大量的標注信息,在大規模的場景下代價太大。對于加深網絡結構的優化方法,又可能帶來訓練的難度,因此,我們認為合理利用容易獲取的信息來優化約束關系,具有更好的普適性和靈活性,這也是本研究的動機之一。一些其他研究者也在這方面開展了工作,例如受傳統方法的啟發,幾何一致性誤差、重投影誤差、相對變換誤差等被構建為正則化項加入損失函數中。這些改進比僅公式化預測位姿和真值位姿之間歐式距離的效果更好,并且不受網絡結構的約束,可以靈活的適用于各種網絡做進一步的性能提升。
在此基礎上,我們進一步探索以更好的方式用幾何信息來約束網絡權重的更新。在SLAM應用和無人車平臺中,深度信息是不可或缺的。例如,室內情況,利用現有的深度估計算法,可以直接從結構光相機、ToF相機或立體相機中獲取深度信息;室外環境,通常采用三維激光雷達來獲取深度/距離信息。因此,我們的改進也對深度信息加以利用。此外,我們使用了光度一致性的假設,也就是說,根據三維幾何知識,當在多個圖像中觀察三維場景中的同一個點時,我們認為其對應的像素強度應該是相同的,這也被用于許多視覺里程計或光流算法。受此啟發,我們構建了光度差損失項,并自然而然地搭配結構相似性(SSIM)損失項。前者為像素級約束,后者為圖像級約束,和常用的歐式距離一起作為網絡的損失函數,訓練過程中約束網絡權重的更新。我們優化后的損失函數融合了運動信息、3D場景幾何信息和圖像內容,幫助訓練過程更高效、定位效果更準確。
2. 相關工作介紹2.1 幾何一致性約束 幾何一致性約束最近被用來幫助提高位姿回歸的準確性,并被證明比單獨使用歐氏距離約束更有效。[9]和[10]通過懲罰與相對運動相矛盾的位姿預測,將幾何一致性引入到損失函數中。[11]利用圖像對之間的相對運動一致性來約束絕對位姿的預測。[12]引入了重投影誤差,使用真值和預測位姿分別將3D點投影到2D圖像平面上,將像素點位置的偏差作為約束項。這些方法都被認為是當時使用幾何一致性損失的最先進方法。在本研究中,我們探索了一個3D場景幾何約束即光度差約束,通過聚合三維場景幾何結構信息,使得網絡不僅能將預測的位姿與相機運動對齊,還能利用圖像內容的光度一致性。
2.2 光度差約束 光度差約束通常用于處理帶監督或無監督學習的相對位姿回歸、光流估計和深度預測。例如,[13]研究了視頻序列的時間關系,為深度補全網絡提供額外的監督。[14]利用無監督學習的稠密深度和帶有光度差損失的相機位姿構建了神經網絡,以學習場景級一致性運動。[15]提出了一種多任務無監督學習稠密深度、光流和ego-motion的方法,其中光度差約束對不同任務之間的一致性起著重要作用。由于光度差約束在相對位姿回歸和深度預測中被證明是有效的,我們引入并驗證了它在絕對位姿預測中的有效性。 與上述工作相比,我們的研究擴展了以下幾點工作:
搭建了一個深度神經網絡模型,可以直接從輸入圖像估計相應的相機絕對位姿。
利用深度傳感器信息,構建了 3D 場景幾何約束來提高位姿預測精度。并且,稀疏深度信息足以獲得顯著的定位精度提升,這意味著我們的方法可以適用于任何類型的深度傳感器(稀疏或稠密)。
在室內和室外數據集上進行了廣泛的實驗評估,證明了加入 3D 場景幾何約束后,可以提高網絡的定位精度,并且這一約束可以靈活地加入到其他網絡中,幫助進一步提高算法性能。
算法介紹
1. 算法框架
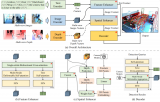
本研究提出的算法框架和數據流如圖a所示,藍色部分是算法中的神經網絡部分(圖b),綠色部分是warping計算過程,黃色部分是網絡的損失函數項,只有藍色部分包含可訓練的權重。 藍色部分的網絡模型采用主流的ResNet-50網絡,保留原來的block設置,并在最后一個block后加入3個全連接層,分別預測3維的translation(x)和3維的rotation(q)。網絡的訓練過程需要輸入兩張連續的有共視的圖像以及其中一張圖像的深度圖,建立真值位姿和預測位姿之間的歐式距離約束作為損失項。大部分先前文獻中的工作僅以這個損失項作為損失函數,我們的工作則進一步融入了3D場景幾何信息,通過利用比較容易獲取的深度信息將這個約束公式化為光度差和SSIM。相比之下,3D場景幾何約束是像素級的,可以利用更多的信息包括相機運動,場景的三維結構信息和圖像內容相關的光度信息,從而使網絡的學習更加高效,更好地朝著全局極小值的方向收斂。

2.Warping計算 綠色部分的warping計算利用連續兩張圖像之間的相對位姿變換和其中一張圖像的深度圖,將本張圖像上的像素投影到另一張圖像的視角上,生成視warping后的圖像,計算公式如下所示。

在warping計算中,從二維圖像像素重建三維結構需要深度信息,實際應用中我們可以從深度傳感器(結構光相機、ToF相機和三維激光雷達)獲取深度信息或通過相關算法回歸深度,例如從兩個重疊的圖像中提取匹配點的三角測量方法。為了不引入誤差,我們更傾向于選擇來自深度傳感器的比較魯棒的深度信息。為了方便反向傳播的梯度計算,我們采用雙線性插值作為采樣機制,生成與當前圖像格式相同的合成圖像。此外,這部分計算不含可訓練的參數,并且inference過程不需要進行這部分的計算,因此不會帶來額外的時間或者資源開銷。 3. 損失函數 在訓練過程中,應用了三個約束條件來幫助訓練收斂:一個經典的歐式距離損失項來約束預測位姿和真值位姿的距離,歐式距離損失項此處不再贅述,直接給出公式如下:
 ? 當視角變化較小且環境光不變時,同一個三維點在不同圖像中的光強應該相同。這種光度一致性用于解決許多問題,如光流估計、深度估計、視覺里程計等。在這里,我們使用它來進行絕對位姿估計,并光度差損失項公式化為warping計算后的圖像與原始圖像對應像素點的光度差值: ?
? 當視角變化較小且環境光不變時,同一個三維點在不同圖像中的光強應該相同。這種光度一致性用于解決許多問題,如光流估計、深度估計、視覺里程計等。在這里,我們使用它來進行絕對位姿估計,并光度差損失項公式化為warping計算后的圖像與原始圖像對應像素點的光度差值: ?
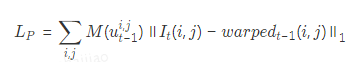
其中,M是用來過濾沒有深度信息或者不服從光度一致性的像素。在我們的實驗中,主要用它來屏蔽兩種類型的像素:移動目標對應的像素和帶有無效深度信息的像素。光度差損失項會約束預測的位姿離真值位姿不遠,以保證在相鄰圖像間進行warping計算后重建的圖像與原始圖像對應像素的光度值一致。考慮到warping計算后,獲得了視角重建后的圖像,自然而然的引入結構相似性約束作為損失項。這個約束反映了場景結構的一致性,計算公式如下所示:
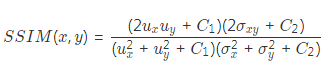

網絡的損失函數定義為三個損失項的加權和,用三個加權系數進行尺度均衡。 
實驗結果
為了驗證我們提出的算法的性能,進行了以下實驗: 1. 與其他算法定位結果對比 在7Scene數據集中,除了MapNet[11]在chess場景中的表現稍好之外,我們的方法在其他場景都取得了最優的結果(見table 1)。在所需的訓練時間上,MapNet 需要300個epochs和PoseNet[2]需要多于120個epochs,我們的方法只需要50個epochs。同時,在室外的Oxford robotcar數據集上,我們的方法也取得了較大的定位精度提升。Figure2顯示了在7Scene中隨機挑選的場景的測試結果。很明顯,PoseNet的預測位姿噪聲較大,MapNet表現的更穩定,但預測精度欠佳,我們的定位結果更為精確。
2. 損失項的消融實驗 為了充分驗證我們提出的光度差損失和SSIM損失對視覺定位算法性能提升的貢獻,分別進行兩個訓練:在PoseNet網絡的損失函數中加入光度差損失和SSIM損失后訓練網絡。在我們的算法中去掉這兩項損失項,只在歐式距離的約束下訓練網絡。結果表明加入光度差和SSIM損失項總是能提高網絡的定位性能(詳細結果見論文)。同時,也表明新的損失項可以靈活的加入其他網絡,用于進一步提高定位精度。
3. 深度稀疏實驗 實際視覺定位應用中,并不總是有可靠的稠密深度可用,如果我們的算法在稀疏深度上依然可以表現的很好,則可以證明我們的方法具有較廣泛的適用性。我們把可用的深度隨機稀疏至原來的20%和60%后,重新訓練網絡,最終的結果如Table3所示,定位精度并沒有被嚴重惡化。
4. 自監督方法的實驗 在進行warping計算時,我們用了輸入兩幀圖像的位姿預測結果來計算相對位姿變換,進而做warping計算,單就光度差和SSIM損失項來說,這是一種自監督的學習方法,那么,也可以一幀圖像用預測結果,另一幀用真值來計算相對位姿變換。通過實驗對比這兩種方法,實驗結果(詳細結果見論文)表明,自監督策略的結果更優。除了網絡被訓練的次數更多這一原因外,它有助于網絡以一種更自然的方式學習相機位姿的連續性和一致性,因為對于共視的圖像,其相應的位姿應該是高度相關的。


結論與展望
本文提出了一種新的視覺定位算法,搭建一個新的網絡框架端到端的估計相機位姿,在對網絡約束關系的優化中,通過融合3D場景幾何結構、相機運動和圖像信息,引入了3D場景幾何約束,幫助監督網絡訓練,提高網絡的定位精度。實驗結果表明,我們的方法優于以往的同類型工作。并且,在不同的網絡中加入新的約束關系后可以進一步提高定位精度。
基于深度學習的視覺定位算法正在被廣泛而又深入的研究,無論是提升算法的精度還是增強實際場景的適用性,各方面的嘗試和努力都是迫切需要的。希望在未來的工作中,能夠通過融入語義信息或者采用從粗到精多階段級連的方法,在室內外場景上實現更高精度更加魯棒的位姿估計,更多細節見論文.
論文原文:3D Scene Geometry-Aware Constraint for Camera Localization with Deep Learning 鏈接:https://arxiv.org/abs/2005.06147 參考文獻 [1] Ke, Yan and R. Sukthankar. “PCA-SIFT: a more distinctive representation for local image descriptors.” Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2004. [2] A. Kendall, M. Grimes, and R. Cipolla, “Posenet: A convolutional network for real-time 6-dof camera relocalization,” in ICCV, 2015. [3] Bay, Herbert, et al. “Speeded-up robust features (SURF).” Computer vision and image understanding 110.3 (2008): 346-359.
[4] Rublee, Ethan, et al. “ORB:An efficient alternative to SIFT or SURF.” ICCV. Vol. 11. No. 1. 2011. [5] A. Kendall and R. Cipolla,“Modelling uncertainty in deep learning for camera relocalization,” ICRA, 2016. [6] I. Melekhov, J. Ylioinas, J. Kannala, and E. Rahtu, “Image-based localization using hourglass networks,” arXiv:1703.07971, 2017. [7] F. Walch, C. Hazirbas, et al.,“Image-based localization using lstms for structured feature correlation,” in ICCV, 2017. [8] Xue, Fei, et al. “Beyond Tracking: Selecting Memory and RefiningPoses for Deep Visual Odometry.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019
[9] A. Valada, N. Radwan, and W. Burgard, “Deep auxiliary learning for visual localization and odometry,” in ICRA, 2018. [10] N. Radwan, A. Valada, W. Burgard, “VLocNet++: Deep MultitaskLearning for Semantic Visual Localization and Odometry”, IEEE Robotics and Automation Letters (RA-L), 3(4): 4407-4414, 2018. [11] Brahmbhatt, Samarth, et al. “Geometry-aware learning of maps for camera localization.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. [12] A. Kendall and R. Cipolla, “Geometric loss functions for camera pose regression with deep learning,” CVPR, 2017. [13] Ma, Fang chang, Guilherme Venturelli Cavalheiro, and Sertac Karaman.“Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera.” 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019. [14] Zhou, Tinghui, et al. “Unsupervised Learning of Depth and Ego-Motion from Video.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017. [15] Yin, Zhichao, and Jianping Shi. “Geonet: Unsupervised learning of dense depth, optical flow and camera pose.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
責任編輯:xj
原文標題:機器視覺干貨 | 場景幾何約束在視覺定位中的探索
文章出處:【微信公眾號:機器人創新生態】歡迎添加關注!文章轉載請注明出處。
-
機器人
+關注
關注
213文章
29691瀏覽量
212578 -
機器視覺
+關注
關注
163文章
4532瀏覽量
122791 -
視覺定位
+關注
關注
5文章
55瀏覽量
12700
原文標題:機器視覺干貨 | 場景幾何約束在視覺定位中的探索
文章出處:【微信號:robotplaces,微信公眾號:機器人創新生態】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
人形機器人 3D 視覺路線之爭:激光雷達、雙目和 3D - ToF 誰更勝一籌?
海伯森3D閃測傳感器,工業檢測領域的高精度利器

黑芝麻智能視覺與4D毫米波雷達前融合算法介紹
一種以圖像為中心的3D感知模型BIP3D
對于結構光測量、3D視覺的應用,使用100%offset的lightcrafter是否能用于點云生成的應用?
英倫科技裸眼3D便攜屏有哪些特點?

從2D走向3D的視覺傳感器

3D 視覺定位技術:汽車零部件制造的智能變革引擎
一種全新開源SfM框架MASt3R

3D可視化賦能智慧園區安防管理,開啟園區管理新篇章!
紫光展銳助力全球首款AI裸眼3D手機發布






 工商網監
工商網監

評論