 卡內基梅隆大學的研究人員開發了一種機器學習模型
卡內基梅隆大學的研究人員開發了一種機器學習模型
AI可能很快就會成為盟友,以消除語音助手的喚醒詞。卡內基梅隆大學的研究人員開發了一種機器學習模型,該模型可以估計語音的發出方向,無需特殊的短語或手勢即可表明您的意圖。該方法依賴于聲音在房間周圍反彈時的固有特性。
系統認識到,第一個,最響亮和最清晰的聲音始終是直接針對給定對象的聲音。其他任何事情都傾向于安靜,延遲和悶悶不樂。該模型還知道,人類的語音頻率會根據您所面對的方向而變化。較低的頻率傾向于全向。
研究人員補充說,這種方法基于軟件“輕巧”,不需要將音頻數據發送到云。
盡管團隊已經公開發布了代碼和數據來幫助其他人繼續工作,但是您可能還需要一段時間才能看到使用的技術。至少很容易看出這可能導致什么。您可以告訴智能揚聲器播放音樂,而無需使用喚醒詞或引起大量其他連接設備的騷擾。它可能需要您的身體狀態,而無需使用注視檢測相機,從而有助于保護隱私。換句話說,它將更接近“星際迷航”中語音助手的愿景,后者始終會在您與他們交談時知道。
責任編輯:lq
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
代碼
+關注
關注
30文章
4779瀏覽量
68526 -
機器學習
+關注
關注
66文章
8407瀏覽量
132567 -
語音助手
+關注
關注
7文章
235瀏覽量
26799
發布評論請先 登錄
相關推薦
研究人員利用激光束開創量子計算新局面
演示設備 威特沃特斯蘭德大學(Wits)的物理學家利用激光束和日常顯示技術開發出了一種創新的計算系統,標志著在尋求更強大的量子計算解決方案方面取得了重大飛躍。 該大學結構光實驗室的
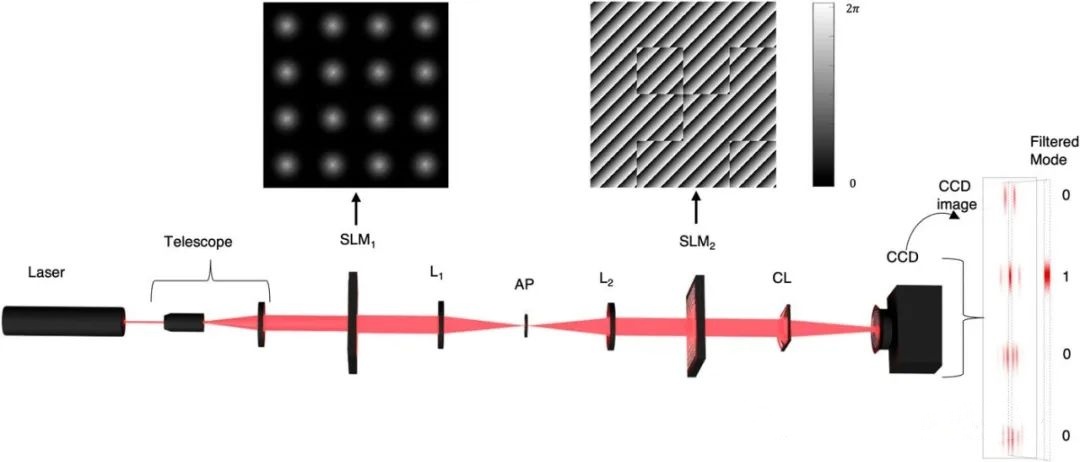
NaVILA:加州大學與英偉達聯合發布新型視覺語言模型
日前,加州大學的研究人員攜手英偉達,共同推出了一款創新的視覺語言模型——NaVILA。該模型在機器
一種信息引導的量化后LLM微調新算法IR-QLoRA
進行量化+LoRA的路線為例,有研究表明,現有方法會導致量化的LLM嚴重退化,甚至無法從LoRA微調中受益。 為了解決這一問題,來自蘇黎世聯邦理工學院、北京航空航天大學和字節跳動的研究人員

研究人員提出一種電磁微鏡驅動系統
領域。MEMS微鏡作為一種微光機電系統(MOEMS),已廣泛應用于醫療、汽車、消費和軍事電子等眾多領域。當前,業界對具有廣闊前景的小型激光雷達的需求不斷增長。之前,已有研究開發了大量使用電熱、靜電、壓電和電磁驅動的微鏡。其
一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
了深度神經網絡在計算機視覺任務中的有效性,并為開發更強大、更復雜的神經網絡架構鋪平了道路。
ResNet-50是一種深度神經網絡架構,由研究人員Kaiming He、XiangyuZhang
發表于 05-11 20:01
一種可實現穩定壓力傳感的新型可拉伸電子皮膚
現有的電子皮膚會隨材料拉伸而降低傳感精度。美國得克薩斯大學奧斯汀分校研究人員開發出一種新型可拉伸電子皮膚,解決了這項新興技術的一個主要難題。
研究人員利用定制光控制二維材料的量子特性
的發展鋪平了道路。 由美國能源部SLAC國家加速器實驗室和斯坦福大學研究人員領導的研究小組將這種方法應用于一種名為六方氮化硼(hBN)的材料,這種材料由單層原子以蜂窩狀排列而成,其特性
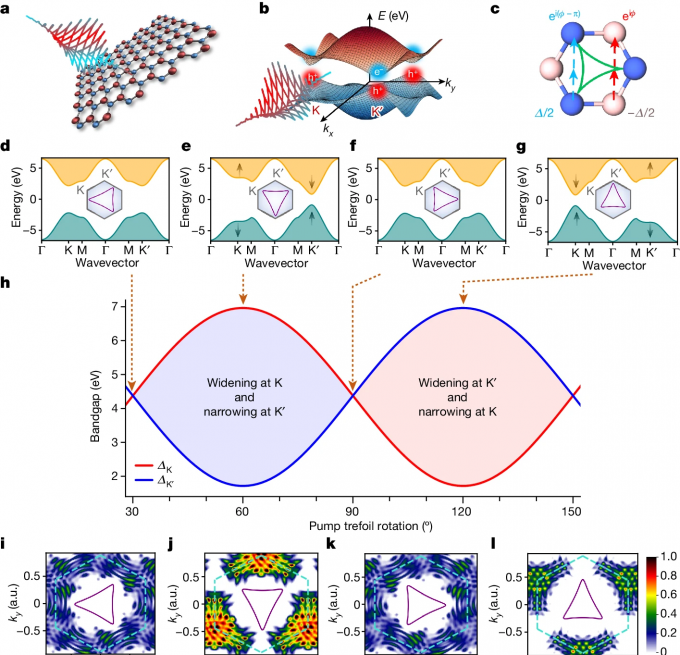
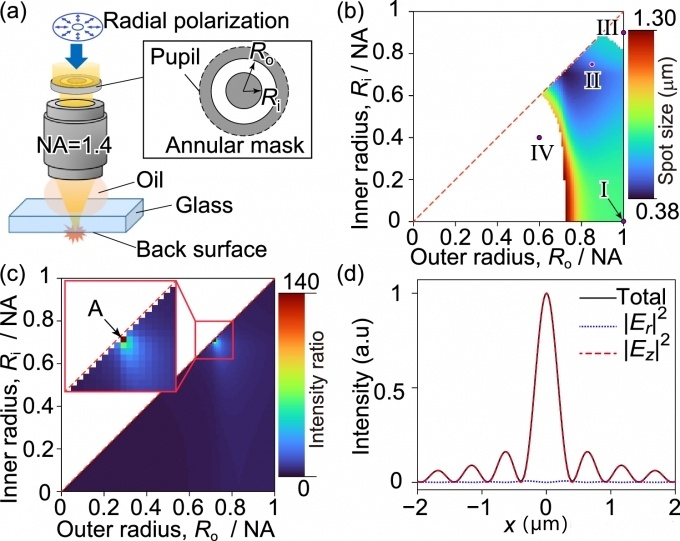
研究人員發現提高激光加工分辨率的新方法
通過透明玻璃聚焦定制激光束可以在材料內部形成一個小光斑。東北大學的研究人員研發了一種利用這種小光斑改進激光材料加工、提高加工分辨率的方法。
研究人員開發出新型AI輔助發音系統,讓人沒有聲帶也能說話
電子發燒友網報道(文/李彎彎)近日,加州大學洛杉磯分校生物工程系助理教授陳俊及其團隊,開發了一種可以在機器學習輔助下將喉部肌肉運動轉化為語音
一種基于單像素光電探測器的高光譜視頻成像系統設計
日前,北京理工大學光電學院王涌天教授、劉越教授團隊成員徐怡博教授與來自谷歌公司和美國萊斯大學研究人員合作,開發了一種具有優異壓縮比和吞吐量的

TikTok引入前谷歌VideoPoet負責人蔣路,發力AI視頻生成
獨家獲悉,谷歌高級科學家、卡內基梅隆大學(CMU)計算機學院兼職教授蔣路,已經加入TikTok。
研究人員開發出一種新型太赫茲成像系統
系統使用的輻射探測器。 由加州大學洛杉磯分校Samueli工程學院電氣和計算機工程教授Mona Jarrahi和Aydogan Ozcan領導的研究團隊發明了一種新的太赫茲焦平面陣列來解決這個問題。 帶PSR的等離子體光電導TH





 工商網監
工商網監
評論