 Hinton的那篇Capsule論文終于揭下了神秘的面紗
Hinton的那篇Capsule論文終于揭下了神秘的面紗
近日,Hinton的那篇Capsule論文終于揭下了神秘的面紗,也因為該篇論文,他被刊進了各大媒體的頭版頭條。
在論文中,Capsule被Hinton大神定義為這樣一組神經元:其活動向量所表示的是特定實體類型的實例化參數。
他的實驗表明,鑒別式訓練的多層Capsule系統,在MNIST手寫數據集上表現出目前最先進的性能,并且在識別高度重疊數字的效果要遠好于CNN。
該論文無疑將是今年12月初NIPS大會的重頭戲。
不過,對于這篇論文的預熱,Hinton大神可是早有準備。
一個月前,在多倫多接受媒體采訪時,Hinton大神斷然宣稱要放棄反向傳播,讓整個人工智能從頭再造。不明就里的媒體們頓時蒙圈不少。
8月份的時候,Hinton大神還用一場“卷積神經網絡都有哪些問題?”的演講來介紹他手中的Capsule研究,他認為“CNN的特征提取層與次抽樣層交叉存取,將相同類型的相鄰特征檢測器的輸出匯集到一起”是大有問題的。
當時的演講中,Hinton大神可沒少提CNN之父Yann LeCun的不同觀點。畢竟,當前的CNN一味追求識別率,對于圖像內容的“理解”幫助有限。
而要進一步推進人工智能,讓它能像人腦一樣理解圖像內容、構建抽象邏輯,僅僅是認出像素的排序肯定是不夠的,必須要找到方法來對其中的內容進行良好的表示……這就意味著新的方法和技術。
而當前的深度學習理論,自從Hinton大神在2007年(先以受限玻爾茲曼機進行訓練、再用有監督的反向傳播算法進行調優)確立起來后,除了神經網絡結構上的小修小改,很多進展都集中在梯度流上。
正如知乎大V“SIY.Z”在《淺析Hinton最近提出的Capsule計劃》時所舉的例子。 (https://zhuanlan.zhihu.com/p/29435406)
sigmoid會飽和,造成梯度消失。于是有了ReLU。
ReLU負半軸是死區,造成梯度變0。于是有了LeakyReLU,PReLU。
強調梯度和權值分布的穩定性,由此有了ELU,以及較新的SELU。
太深了,梯度傳不下去,于是有了highway。
干脆連highway的參數都不要,直接變殘差,于是有了ResNet。
強行穩定參數的均值和方差,于是有了BatchNorm。
在梯度流中增加噪聲,于是有了 Dropout。
RNN梯度不穩定,于是加幾個通路和門控,于是有了LSTM。
LSTM簡化一下,有了GRU。
GAN的JS散度有問題,會導致梯度消失或無效,于是有了WGAN。
WGAN對梯度的clip有問題,于是有了WGAN-GP。
而本質上的變革,特別是針對當前CNN所無力解決的動態視覺內容、三維視覺等難題……進行更為基礎的研究,或許真有可能另辟蹊徑。
這當然是苦力活,Hinton大神親自操刀的話,成功了會毀掉自己賴以成名的反向傳播算法和深度學習理論,失敗了則將重蹈愛因斯坦晚年“宇宙常數”的覆轍。
所以,李飛飛對他在這里的勇氣大為贊賞:
如今Capsule的論文剛剛出來,深度學習的各路大神并沒有貿然對其下評論,深夜中的外媒亦尚未就此發稿,甚至就連技術圈內一向口水不斷的Hacker News,今天也是靜悄悄地一片。
不過,可以肯定的一點是,一個月后的NIPS大會,Capsule更進一步的效果必定會有所顯現。
至于Hinton此舉對于深度學習和整個人工智能界的后續影響,包括Yann LeCun在內的各路大神恐怕都不敢冒下結論,咱們還是靜等時間來驗證Hinton大神的苦心孤詣到底值不值得吧。
這正如Hinton大神在接受吳恩達采訪時所說的:
如果你的直覺很準,那你就應該堅持,最終必能有所成就;反過來你直覺不好,那堅不堅持也就無所謂了。反正你從直覺里也找不到堅持它們的理由。
當然,營長肯定是相信Hinton大神的直覺的,更是期待人工智能能在當前的水平上更進一步。
盡管意義不同,Hinton大神此舉卻讓營長想到了同在古稀之年的開爾文勛爵,他1900年那場關于物理學“兩朵烏云”的演講可是“預言”得賊準:
“紫外災難”讓年近不惑的普朗克為量子力學開創了先河,“以太漂移”讓剛剛畢業的愛因斯坦開始思考狹義相對論,經典物理學的大廈就此崩塌。
那么,人工智能上空所飄蕩的到底是一朵“烏云”呢?還是一個新的時代?讓我們拭目以待。
責任編輯:lq
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100857 -
神經元
+關注
關注
1文章
363瀏覽量
18466 -
cnn
+關注
關注
3文章
352瀏覽量
22238
原文標題:70歲Hinton還在努力推翻自己積累了30年的學術成果,他讓我知道了什么叫做生命力
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
揭開觸控技術的神秘面紗
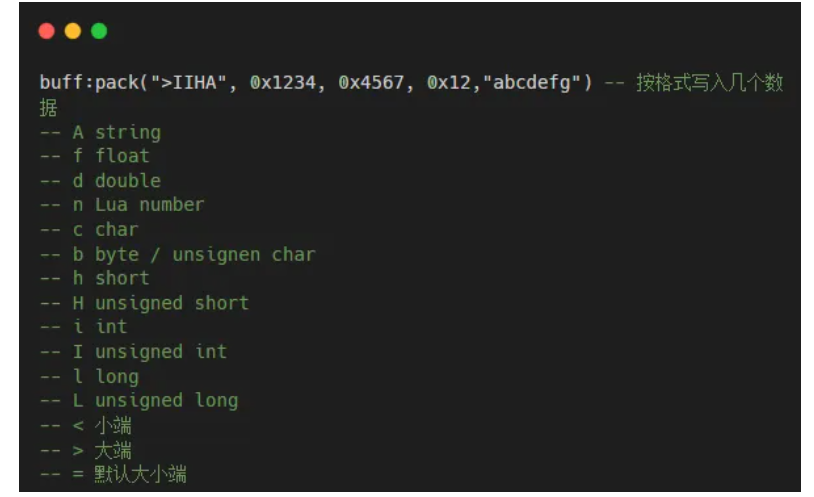
12條PCB設計規則
艾畢勝電子全自動跟拍智能云臺驅動板方案的神秘面紗


北斗衛星時鐘——揭開“授時”的神秘面紗
深入分析:常說的3H原則在PCB設計中的應用

xAI公司將在八月揭開其新Grok-2大語言模型的神秘面紗
揭開Pluto XZU20的神秘面紗—探尋未來緊湊而強大的FPGA解決方案

揭開快充芯片的神秘面紗
UFP芯片-揭開快充芯片的神秘面紗







 工商網監
工商網監
評論