 了解光學字符識別技術識別票據原理
了解光學字符識別技術識別票據原理
本文翻譯自dzone 中Ivan Ozhiganov 所發文章Deep Dive Into OCR for Receipt Recognition 文中版權、圖像代碼等數據均歸作者所有。為了本土化,翻譯內容略作修改。
光學字符識別技術(OCR)目前被廣泛利用在手寫識別、打印識別及文本圖像識別等相關領域。小到文檔識別、銀行卡身份證識別,大到廣告、海報。因為OCR技術的發明,極大簡化了我們處理數據的方式。
同時,機器學習(ML)和卷積神經網絡(CNN)的快速發展也讓文本識別出現了巨大的飛躍!我們在本文的研究中也將使用卷積神經網絡CNN技術來識別零售店的紙質票據。為了方便演示,我們本次將僅采用俄語版的票據進行測試。
我們的目標是項目開發一個客戶端來識別來獲取相關文檔,在有服務器端去識別解析數據。準備好了嗎?讓我們一起去看看怎么做吧!
預處理
首先,我們需要接收圖像相關數據,使其水平豎直方向垂直,接下來使用算法進行檢測是否為票據,最終二值化方便識別。
旋轉圖像識別收據
我們有三種方案來識別票據,下文對這三種方案做了測試。
1. 高閾值的自適應二值化技術。2. 卷積神經網絡(CNN)。3. Haar特征分類器。
自適應二值化技術
首先,我們看到,圖中圖像上包含了完整的數據,同時票據又與背景有些差距。為了能更好識別相關數據,我們需要將圖片進行旋轉。使其水平沿豎直方向對齊。
我們使用Opencv中的自適應閾值化函數adaptive_threshold和scikit-image框架來調整收據數據。利用這兩項函數,我們可以在高梯度區域保留白色像素,低梯度區域保留黑色像素。這使得我們獲得了一個高反差的樣本圖片。這樣,通過裁剪,我們就能得到票據的相關信息了。
使用卷積神經網絡(CNN)
起初我們決定使用CNN來做相關位置檢測的接收點,就像我們之前做對象檢測項目一樣。我們使用判斷角度來拾取相關關鍵點。這種方案雖然好用,但是和高閾值對比檢測裁剪更差。
因為CNN只能找到文本的角度坐標,而文字的角度變化很大,這就意味著CNN模型不是很精準。詳情請參考下面CNN測試的結果。
使用Haar特征分類器來識別收據
作為第三種選擇,我們嘗試使用Haar特征分類器來做分類篩選。然而經過一周的分類訓練和改變相關參數,我們并沒有得到什么比較積極的結果,甚至發現CNN都比Haar表現好得多。
二值化
最終我們使用opencv中的adaptive_threshold方法進行二值化,經過二值化處理,我們得到了一個不錯的圖片。
文本檢測
接下來我們來介紹幾個不同的文本檢測組件。
通過鏈接組件檢測文本
首先,我們使用Opencv中的find Contours函數找到鏈接的文本組。大多數鏈接的組件是字符,但是也有二值化留下來嘈雜的文本,這里我們通過設置閾值的大小來過濾相關文本。
然后,我們執行合成算法來合成字符,如:Й和=。通過搜索最臨近的字符組合合成單詞。這種算法需要你找到每個相關字字母最臨近的字符,然后從若干字母中找到最佳選擇展示。
接下來文字形成文字行。我們通過判斷文字是否高度一致來判斷文本是否屬于同一行。
當然,這個方案的缺點是不能識別有噪聲的文本。
使用網格對文本進行檢測
我們發現幾乎所有票據都是相同寬度的文本,所以我們設法在收據上畫出一個網格,并利用網格分割每個字符:
網格一下子精簡了票據識別的難度。神經網絡可以精準識別每個網格內的字符。這樣就解決了文本嘈雜的情況。最終可以精確統計文本數量。
我們使用了以下算法來識別網格。
首先,我在二值化鏡像中使用這個連接組件算法。
然后我們發現圖中左下角有些是真,所喲我們通過二維周期函數來調整網格識別。
修正網格失真背后主要的思想是利用圖形峰值點找到非線性幾何失真,換句話說,我們必須找到這個函數的最大值的和。另外,我們還需要一個最佳失真值才行。
我們使用ScipyPython模塊中的RectBivariateSpline函數來參數化幾何失真。并用Scipy函數進行優化。得到如下結果:

總而言之,這個方法緩慢且不穩定,所以堅決不打算使用這個方案。
光學字符識別
我們通過組連接識別發現文本,并識別完整的單詞。
識別通過連接組發現的文本
對于文本識別,我們使用卷積神經網絡(CNN)接收相關字體進行培訓。輸出部分,我們通過對比來提升概率。我們那個幾個最初的幾個選項多對比,發現有99%的準確識別率后。又通過對比字典來提高準確度,并消除相關類似的字符,如"З" 和 "Э"造成的錯誤。
然而,當涉及嘈雜的文本時,該方法性能卻十分低下。
識別完整的單詞
當文本太嘈雜的時候,需要找到完整的單詞才能進行單個字母的識別。我們使用下面兩個方法來解決這個問題:
LSTM網絡
圖像非均勻分割技術
LSTM網絡
您可以閱讀這些文章,以更加深入了解使用卷積神經網絡識別序列中的文本 ,或我們可以使用神經網絡建立與語言無關的OCR嗎?為此,我們使用了OCRopus庫來進行識別。
我們使用了等寬的字體來作為人工識別樣本進行訓練。
訓練結束后,我們由利用其他數據來測試我們的神經網絡,當然,測試結果非常積極。這是我們得到的數據:
訓練好的神經網絡在簡單的例子上表現十分優秀。同樣,我們也識別到了網格不適合的復雜情況。
我們抽取的相關的訓練樣本,并讓他通過神經網絡進行訓練。
為了避免神經網絡過度擬合,我們多次停止并修正訓練結果,并不斷加入新數據作為訓練樣本。最后我們得到以下結果:

新的網絡擅長識別復雜的詞匯,但是簡單的文字識別卻并不好。
我們覺得這個卷積神經網絡可以細化識別單個字符來使文本識別更加優秀。
圖像非均勻分割技術
因為收據字體是等寬的字體,所以我們決定按照字符分割字體。首先,我們需要知道每個字母的寬度。因此,字符的寬度尤為重要,我們需要估計每個字母的長度,利用函數,我們得到下圖。選擇多種模式來選取特定的字母寬度。
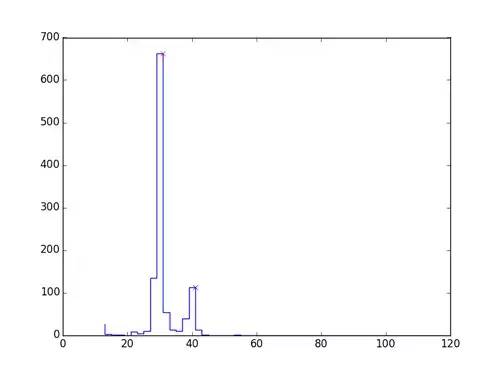
我們得到一個單詞的近似寬度,通過除以字符中的字母數,給出一個近似分類:
區分最佳的是:
這種分割方案的準確度是非常高的:
當然,也有識別不太好的情況:
分割后我們在使用CNN做識別處理。
從收據中提取含義
我們使用正則表達式來查找收據中購買情況。所有收據都有一個共通點:購買價格以XX.XX格式來撰寫。因此,可以通過提取購買的行來提取相關信息。個人納稅號碼是十位數,也可以通過正則表達式輕松獲取。同樣,也可以通過正則表達式找到NAME / SURNAME等信息。
總結
不論你選擇什么方法,LSTM或者其他更加復雜的方案,都沒有錯誤,有些方法很難用,但是有些方法卻很簡單,因識別樣本而異。
我們將繼續優化這個項目。目前來看,在沒有噪聲的情況下,系統性能更加優秀。
原文鏈接:https://dzone.com/articles/using-ocr-for-receipt-recognition
責任編輯:xj
原文標題:深入淺出了解OCR識別票據原理
文章出處:【微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
-
OCR
+關注
關注
0文章
145瀏覽量
16388 -
識別
+關注
關注
3文章
173瀏覽量
31979
原文標題:深入淺出了解OCR識別票據原理
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Litera Drafting:幫助改進發布文檔的方式(十)
語音識別技術的應用與發展
光學字符識別是什么的一種技術
光學識別技術的工作原理是什么?
光學識別字符是自動識別技術嗎
光學識別的過程包含哪些
光學識別輸入的基本原理是什么
人臉識別技術的原理介紹
智能手機充電頭OCR精準識別

AOI字符識別機器視覺系統方案

項目分享|基于ELF 1開發板的車牌識別系統







 工商網監
工商網監
評論