 AI 軟件TLDR:可用一句話概括文章
AI 軟件TLDR:可用一句話概括文章
摘要在一篇文章中有著至關重要的作用,它濃縮了整篇文章的精華,可以讓你快速了解該篇文章的研究背景、研究意義和研究亮點,進而決定了你是否會點開這篇文章仔細閱讀。
如果摘要太長或者邏輯混亂,就會失去它讓人快速瀏覽的意義,很有可能讓人忽略掉一篇正文內容還不錯的文章。那么,是否可以在摘要的基礎上進一步提煉,用一句話概括文章?
答案是:AI 可以做到。
近日,一款科學搜索引擎在其官網上就推出了這樣一款 AI 軟件——TLDR,即“太長了,沒有讀”(too long,didn’t read)的意思,該軟件可以自動生成研究論文的一句話總結。這款軟件的開發者認為,這樣可以幫助研究人員更快地瀏覽論文,減少閱讀摘要的時間。
TLDR 經常被用于網上關于科學論文的非正式討論(比如,Twitter 或 Reddit)。
本周,這款軟件在華盛頓州西雅圖的非營利性艾倫人工智能研究所(AI2)創建的搜索引擎 Semantic Scholar 的搜索結果中開始上線使用。目前,該軟件只為 Semantic Scholar 所覆蓋的 1000 萬篇計算機科學論文生成一句話摘要。
AI2 管理 Semantic Scholar 小組的 Dan Weld 表示,他們目前正在優化 TLDR,預計一個月左右的時間后,TLDR 將陸續涵蓋其他學科領域的論文。
圖 | TLDR 與普通總結的對比 (來源:Semantic Scholar)
初步測試表明,該工具可以幫助讀者比查看標題和摘要的方式更快地整理搜索結果,特別是在手機上。
圖 | TLDR 在手機上的效果(來源:Nature)
介紹該軟件的預印本于 4 月 1 日首次發表在 arXiv 預印本服務器上,并在 11 月舉行的自然語言處理會議上經過同行評審后被接收發表。研究人員免費提供了他們的代碼,以及一個測試 demo,任何人都可以嘗試使用。
圖 | 生成 TLDR 的測試 (來源:SCITDLR)
如何訓練 TLDR?
TLDR 本質上就是對科學論文的一種新的總結。Weld 創建 TLDR 軟件的靈感一部分來自于他的同事,其在 Twitter 上分享標記文章的活潑句子。與其他語言生成軟件一樣,該軟件是利用深度神經網絡,通過進行大量的訓練而生成。
圖 | TLDR 的介紹 (來源:arxiv)
為了訓練 TLDR,研究人員準備了 SCITLDR,這是一個多目標數據集,包含5411篇TLDR,覆蓋計算機科學領域的 3229 篇科學論文。
其中,訓練集包含 1992 篇論文,每篇論文都有一個“黃金”TLDR,也就是最佳 TLDR。開發集和測試集分別包含 619 篇和 618 篇論文,分別有 1452 個和 1967 個 TLDR。
通常情況下,總結數據集會假設一個給定文檔只有一個黃金總結,而 SCITLDR 與大多數現有的總結數據集不同。正如早期的摘要評估工作所證明的那樣,人類撰寫的摘要具有可變性。
將每篇論文只考慮一個黃金 TLDR 作為自動評估的基礎,可能會導致系統質量評估不準確,因為可能出現在 TLDR 中的內容可能具有很大的可變性。此外,為每份文件提供多個黃金摘要,可以進行更深入的分析和徹底的評估。
為了解決這個問題,SCITLDR 包含了從作者角度撰寫的 TLDR("TLDR-Auth")和從同行評審者角度撰寫的 TLDR("TLDR-PR")。
TLDR-Auth 可在各種在線平臺上獲得。在公開的科學評審平臺 OpenReview.org 上,作者提交其論文的 TLDR,為審稿人和其他感興趣的學者總結主要內容。學者們也會在Twitter 和 Reddit 等社交媒體平臺上分享 TLDR。
TLDR-PR 是將同行評審員已經仔細檢查了源論文后寫的評論中的總結重寫成 TLDR。為了完成這項任務,研究人員從華盛頓大學招募了 28 名計算機科學專業的本科生,他們有自我報告的閱讀科學論文的經驗。在接受一個小時的一對一寫作訓練并篩選后完成 TLDR 的寫作工作。
圖 | TLDR-Auth 和 TLDR-PR的對比(來源:arxiv)
圖 | TLDR-Auth 和 TLDR-PR的對比(來源:arxiv)
TLDR-Auth 和 TLDR-PR 即使包含相同的信息內容,也會有很大的差異。總的來說,TLDR-PR 總結的更為抽象。
引入 CATTS 對 TLDR 進行優化
CATTS(Controlled Abstraction for TLDRs with Title Scaffolding),這是一種簡單而有效的學習生成 TLDR 的方法,它可以在以上介紹的數據集訓練的基礎上進行補充訓練。該方法解決了兩個主要挑戰:(1) 訓練數據的大小是有限的;(2) 為了編寫高質量的黃金 TLDR,需要領域知識。
為了解決這些挑戰,研究人員提出使用科學論文的標題作為額外的生成目標。由于標題通常包含有關論文的關鍵信息,假設訓練模型生成標題將允許它學習如何定位論文中的突出信息,這些信息對生成 TLDR 也很有用。
通過多任務學習納入輔助腳手架任務之前已經研究過,用于改進跨度標注和文本分類 。與多任務學習類似,在帶有控制代碼注釋的異質數據上進行訓練已經被證明可以改善自回歸語言模型中的控制生成。
為了讓標題生成完成輔助 TLDR 生成的任務,研究人員提出用標題生成數據集洗牌 SCITLDR,然后分別用控制代碼 <|TLDR|> 和 <|TITLE|> 附加每個源。這使得模型的參數可以學習生成 TLDR 和標題。在生成時,適當的控制代碼被附加到源中。此外,上采樣特定任務可以被視為應用特定任務的權重,類似于多任務學習設置中的權重損失。
圖 | CATTS引入可視化(來源:arxiv)
對 TLDR 未來的期待
"我預測,在不久的將來,這種工具將成為學術搜索的標準功能。事實上,考慮到科研人員實際的需求,我很驚訝等了這么長時間才看到它的實際應用。" 西雅圖華盛頓大學的信息科學家杰文 - 韋斯特(Jevin West)說,他應《自然》雜志的要求測試了該工具。"雖然它并不完美,但它絕對是朝著正確方向邁出的重要一步。" 他說。
Weld 指出,TLDR 軟件并不是唯一的科學總結工具:自 2018 年以來,網站 Paper Digest 也一直提供論文摘要,但它似乎是從文本中提取關鍵句子,而不是生成新句子。
TLDR 可以從論文的摘要、引言和結論中生成一句話。它的摘要往往是根據文章文本中的關鍵短語建立起來的,所以它的受眾人群是已經了解論文行話的專業的科研人員。對于普通人來說,閱讀起來依舊存在一些難度。但 Weld 表示,該團隊正在努力為非專家受眾提供更為簡單易懂的升級版產品。
研究人員還計劃將該技術授權給出版商,并將其服務擴展到提供個性化的研究簡報,總結某個領域的關鍵論文。"我們只是到了人工智能可以以人們可以接受的水平生成新穎的摘要的階段,"Weld 說。
責任編輯:xj
-
軟件
+關注
關注
69文章
4968瀏覽量
87701 -
AI
+關注
關注
87文章
31098瀏覽量
269435
發布評論請先 登錄
相關推薦
OpenAI又打出王炸!一句話生成60秒視頻,馬斯克:人類認輸吧

使用ADS1220設計一款電路用來采集一個電阻橋式傳感器,使用內部的2.048V基準作為基準電壓?

開關電源布線 一句話:要運行最穩定、波形最漂亮、電磁兼容性最好

求助,關于TLE2141的供電問題求解
想把差分信號轉為單端信號,不是音頻信號,OPA365是否還可以使用呢?
知網狀告AI搜索:搜到我家論文題目和摘要,你侵權了!
esp32c3 vdd_spi如何作為gpio11使用?
一句話讓你理解線程和進程

AI推理,和訓練有什么不同?

請問AD2428 TX crossbar是個什么功能?
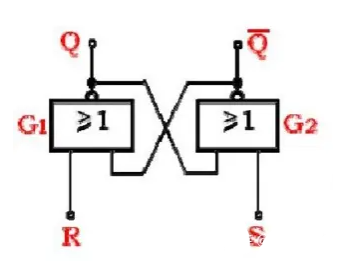
RS觸發器邏輯門組成和邏輯功能表





 工商網監
工商網監
評論