") GPU的原理和渲染流程詳細說明
GPU的原理和渲染流程詳細說明
GPU是每臺電腦不可缺少的組件,缺少GPU,我們的筆記本將無法正常顯示圖像。即便我們每天都在運用GPU,但是大家真的了解GPU的原理嗎?了解GPU渲染流程嗎?如果你對GPU以及GPU相關(guān)知識具有興趣,不妨繼續(xù)往下閱讀哦。
GPU渲染流水線,是硬件真正體現(xiàn)渲染概念的操作過程,也是最終將圖元畫到2D屏幕上的階段。GPU管線涵蓋了渲染流程的幾何階段和光柵化階段,但對開發(fā)者而言,只有對頂點和片段著色器有可編程控制權(quán),其他一律不可編程。如下圖:
簡單總結(jié)GPU管線,這階段中主要是對圖元進行操作。首先,將由應(yīng)用階段加載到顯存中的頂點數(shù)據(jù)(由drawCall指定后)作為輸入傳遞給頂點著色器。接著,頂點著色器首先對圖元的每個頂點設(shè)置模型視圖變換及投影變換(即右乘MVP矩陣),然后將變換后的頂點按照攝像機視椎體定義(即透視投影,或正投影)進行裁剪,將不在視野內(nèi)的頂點去掉并剔除某些三角面片。最后到幾何階段的屏幕映射,負責把修改過的圖元的坐標轉(zhuǎn)換到屏幕坐標系中(即投影到屏幕上)。
到光柵化階段,這一階段主要目的是將每個圖元轉(zhuǎn)換為多個片段,并生成多個片段的位置,由片段著色器負責計算每個片段的顏色值。同時,在這階段片段著色器通常會要求輸入紋理,從而對每個片段進行著色貼圖。每個片段在被發(fā)送到幀緩沖區(qū)之前,還會經(jīng)歷一些操作,這些操作可能會修改片段的顏色值,其中包括深度測試,模板測試,像素所有權(quán)測試,與當前緩沖區(qū)相同位置顏色混合等等。
最后,幀緩沖區(qū)內(nèi)容被交換到屏幕進行顯示。
下面會對各個階段每個知識點進行詳細的分析理解。
一、頂點著色器
頂點著色器是一段類似C語言的程序(即OpenGL的GLSL,或只支持微軟的HLSL,或Unity的Cg),由程序員提供并在GPU上執(zhí)行,對每個頂點都執(zhí)行一次運算。頂點著色器可以使用頂點數(shù)據(jù)來計算改頂點的坐標,顏色,光照和紋理坐標等。在渲染管線中,每個頂點都獨立的被執(zhí)行。原因在于頂點著色器本身不能創(chuàng)建或刪除頂點,也無法得到頂點與頂點之間的關(guān)系,如無法知道兩個頂點是否屬于同一個三角網(wǎng)格。正因這獨立性,GPU可以并行化處理每一個頂點,提高處理速度。
頂點著色器最重要的功能是執(zhí)行頂點的坐標變換和逐頂點光照。坐標變換是改變頂點的位置,把頂點坐標從模型空間轉(zhuǎn)換到齊次裁剪空間(即將本地坐標系轉(zhuǎn)換為裁剪坐標系)。通過改變頂點位置可以實現(xiàn)很多酷炫的shader效果,如模擬水面,布料等等,這里后面添加實例學習例子再詳細說明。頂點著色器的另一功能是向后續(xù)階段的片段著色器提供一組易變(Varying)變量,用于插值計算。
二、圖元裝配
在頂點著色器程序輸出頂點坐標之后,各個頂點按照繪制命令(DrawArrays或DrawElements)中的圖元類型參數(shù)和頂點索引數(shù)組被組裝成一個個圖元,并對其進行如下圖的圖元操作:
注意一點,透視裁剪是比較影響性能的過程,因為每個圖元都需要和6個裁剪面進行相交計算并產(chǎn)生新圖元。所以一般在x軸,y軸超出屏幕(由glViewPort定義)的部分,這些頂點在視口變換的時候被更高效的直接丟棄,無須產(chǎn)生新圖元。
視椎體在OpenGL中可以通過gluPerspecTIve來定義對應(yīng)的大小結(jié)構(gòu),在Cocos2dx引擎中,Director類的setProjecTIon方法就定義了cocos的渲染用到的視椎體,大家可以閱讀對應(yīng)的代碼了解學習下。
經(jīng)過視椎體裁剪后的頂點坐標經(jīng)過透視分離(指由硬件做透視除法),得到范圍是[0,1]的歸一化的設(shè)備坐標,最后映射到屏幕或者視口上。
三、片段著色器
【先補充一點,其實在光柵化之前,要判斷圖元的朝向,是面向還是背對觀察者,以決定是否需要丟棄圖元。在OpenGL可通過glFrontFace指令來決定哪個方向為正,并通過glCullFace決定需要保留哪一面(別忘了要先打開剔除狀態(tài)設(shè)置才可以調(diào)用指令 glEnable(GL_CULL_FACE);)。這樣設(shè)計的好處是能減少一些不必要的繪制,并減少對GPU的浪費。】
回到正題,片段著色器同上述的頂點著色器,只是它作用的對象是每一片段,對其進行著色貼圖。片元著色器的輸入是根據(jù)那些從頂點著色器中輸出的數(shù)據(jù)插值得到的,其中最重要的渲染技術(shù)之一是紋理采樣。在頂點著色器階段輸出每一頂點對應(yīng)的紋理坐標,然后經(jīng)過光柵化階段對三角網(wǎng)格的3個頂點各自紋理坐標進行插值運算后便得到其覆蓋片元的紋理坐標,從而在片元著色器中進行紋理采樣。如下圖:
四、逐片元操作
這里篇幅原因不一一分析每種測試操作,大家可以通過看書了解對應(yīng)的用途。下面舉混合操作來分析一下。下圖是簡化流程圖:
對于不透明的物體,可以直接關(guān)閉混合Blend操作,這樣片元著色器計算得到的顏色值直接覆蓋更新緩沖區(qū)的顏色值。但對于半透明物體就必須開啟使用混合操作從而讓物體看起來是透明的。開發(fā)過程中無法得到透明效果的原因,往往有可能是沒有開啟混合功能的原因。
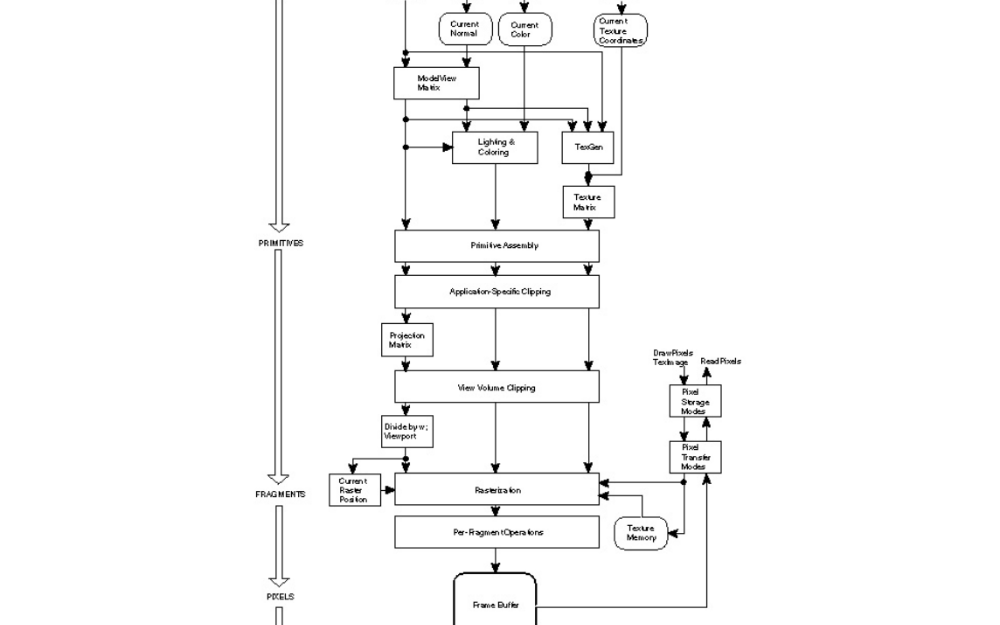
由于計算機圖形的性質(zhì),圖形管線已構(gòu)造為計算狀態(tài)與數(shù)據(jù)流動作為它們之間的數(shù)據(jù)流。每個階段工作在一組元素,如頂點,三角形或像素。下圖1[ Shr99 ]給出了典型的OpenGL固定管道。
人們很容易看到這種體系結(jié)構(gòu)如何類似于中描述的流計算模型上一節(jié)。這種類型的固定結(jié)構(gòu)的是,直到最近,計算機圖形卡制造商的標準可循。雖然類似流計算模式,它提供了很少或沒有編程的用戶,因此,它是不可用于比處理圖形指令的其他任何任務(wù)。2000年[ Owe05 ],GPU 小號允許管道的關(guān)鍵部位的可編程性一定程度。
當前GPU 小號允許用戶在形式的圖形流水線的兩個階段幾乎任何類型的功能進行編程頂點程序和片段的方案。這些允許用戶分別寫在頂點和片段數(shù)據(jù)的程序。下圖示出了更近的映射的OpenGL可編程管線到流模型。
該頂點處理器
頂點處理器輸入的頂點值和其相關(guān)的數(shù)據(jù)進行操作。它的目的是執(zhí)行傳統(tǒng)的圖形操作,如:頂點變換,正常轉(zhuǎn)化和規(guī)范化,紋理坐標生成和改造,照明和顏色計算[ Ros04。因為頂點處理器是能夠改變輸入的頂點數(shù)據(jù)的位置,從而影響最終圖像的要繪制。由于圖像是,在本質(zhì)上,的存儲器陣列,頂點處理器能夠分散狀操作。另外,最近的處理器能夠從紋理存儲器讀出,從而產(chǎn)生一種特殊的延遲收集動作。我們稱之為延遲,因為頂點不能直接從其他頂點元件讀取的信息,但它可以讀取的任何數(shù)據(jù)從先前的計算結(jié)果,如果它是在紋理存儲器編碼。在后面的章節(jié)中,我們將看到如何利用這一點來執(zhí)行簡單的計算。
頂點處理器可以在SIMD(單指令多數(shù)據(jù))或MIMD(多指令多數(shù)據(jù))模式下運行; 因此,允許兩個,一個處理器單元中的指令和任務(wù)并行。由于現(xiàn)代GPU 小號包含多個頂點處理器(最新的NVIDIA 和ATI卡有多達六個),我們可以開始欣賞并行這些體系結(jié)構(gòu)上實現(xiàn)的水平。
該碎片處理器
該片段處理器上的片段和它們相關(guān)聯(lián)的數(shù)據(jù)進行操作。一些傳統(tǒng)上與片段著色器相關(guān)聯(lián)的操作是:質(zhì)地接入和應(yīng)用,霧,顏色和與上內(nèi)插值一般操作。如同頂點著色器,片段著色器可用于在GPU上執(zhí)行幾乎任何種類的計算。因為片段處理器可以訪問紋理存儲器的隨機這是很容易的片段程序內(nèi)執(zhí)行聚集操作。實際上,這是很常見的使用紋理信息進行依賴于其他紋理查找窗口; 功能移植算法的流計算模型時來真的很方便。
雖然在目前的GPU架構(gòu)碎片處理器可以在SIMD模式下運行,是非常嚴格的那種,他們允許我們將看到,他們還是很容易執(zhí)行一般的計算操作。加,由于片段的處理片段的處理器數(shù)量的計算頻率比頂點處理器的數(shù)目越高。當前頂級的線卡有十六歲左右的片段處理器。
-
存儲器
+關(guān)注
關(guān)注
38文章
7484瀏覽量
163765 -
gpu
+關(guān)注
關(guān)注
28文章
4729瀏覽量
128890 -
C語言
+關(guān)注
關(guān)注
180文章
7604瀏覽量
136692
發(fā)布評論請先 登錄
相關(guān)推薦
什么是強制gpu渲染_強制渲染gpu有什么用
GPU原理 GPU渲染流程

如何使用串口工具連接OneNET上報數(shù)據(jù)AT命令流程的代碼詳細說明

發(fā)那科機器人示教手冊DeviceNet配置流程詳細說明

GPU的原理渲染流程詳細說明
FPGA設(shè)計的全部流程詳細說明
LTE簇優(yōu)化流程和案例介紹詳細說明





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論