 將機器學習轉移到網絡邊緣變得引人注目
將機器學習轉移到網絡邊緣變得引人注目
離網絡邊緣更近一步
機器學習介紹
機器學習是大多數AI應用的核心,負責教計算機學會識別數據中的模式。更具體地來說,其目標就是創建訓練有素的模型。這可以通過監督學習來完成,這種學習方式向計算機提供學習實例。另外,這個過程也可以不受監督——計算機只是在數據中尋找其關心的模式。還有涉及連續學習或持續學習的技術,這些技術可以使計算機從錯誤中吸取教訓,但這些不在本文討論范圍之內。
運行您的ML模型
一旦建成了ML模型,便可以將其應用于手頭的工作。 模型可用于預測未來事件、識別異常,以及進行圖像或語音識別。 幾乎在所有情況下,模型都依賴于大型深層樹狀結構,并且需要大量的算力才能運行。 對于通常基于人工神經網絡進行圖像和語音識別的模型而言尤其如此。 神經網絡創建稠密網格,因此需要在高度并行化的硬件(通常基于GPU)上運行。 直到最近,也只有AWS或Azure等云服務提供商才有實力提供此類功能。
為了讓您對所需的算力有個概念,表1列示了AWS P3實例的規格,這是一個針對ML應用進行了優化的處理平臺:
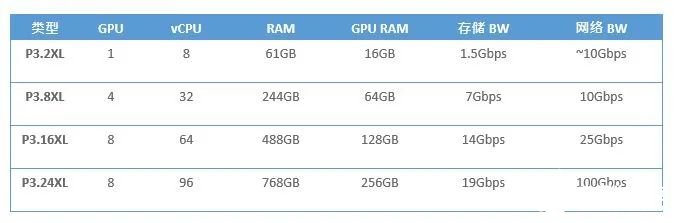
表1:AWS P3實例規格
這些都是頂配機型。它們具備大容量RAM,以及極快的網絡和存儲訪問權限。最重要的是,它們具有強大的CPU和GPU處理能力,正是這一要求使ML模型在網絡邊緣運行成為了真正的挑戰。
集中式AI的缺點
目前為止,由于ML模型難以在網絡邊緣運行,因此大多數最著名的AI應用都依賴于云。但是,這種對云計算的依賴給AI的使用帶來了一些限制。下面列出了集中式AI在運行方面的一些缺陷。
有些應用無法在云端運行
為了在云端運行AI,需要有容量足夠的可靠網絡連接。如果沒有這種條件,則可能由于缺乏基礎設施,有些AI應用不得不在本地運行。換言之,只有能夠在邊緣運行ML模型,這些應用才能正常工作。
以自動駕駛汽車為例。它需要完成許多依賴于機器學習的任務。這些任務中最重要的是探測和規避物體。這要求ML模型要有相當大的算力。但是,即使是聯網汽車也只有較低的連接帶寬,這些連接還并不一致(盡管5G可能會改善這一點)。
在為采礦和其他重工業創建智能物聯網監控系統時,同樣存在這種限制。通常在本地會有快速網絡,但是互聯網連接可能會依賴于衛星上行鏈路。
延遲是關鍵
許多ML應用需要實時工作。上面提到的自動駕駛汽車就是此類應用,另外還有實時面部識別等應用。它們可以用于門禁系統或安保措施。例如,警察經常使用這項技術監視體育賽事和其他活動中的人群,以找出已知的鬧事者。
AI也越來越多地用于打造智能醫療設備。其中一些需要實時工作才能發揮真正的作用,但是連接到數據中心的平均往返時間約在10到100毫秒之間。因此,如果不將ML模型轉移到網絡邊緣,就很難實現實時應用。
安全性可能會成為問題
許多ML應用會處理安全數據或敏感數據。顯然,這類數據可以通過網絡發送,并被安全存儲到云端。但是,當地政策通常禁止這樣做。健康數據尤其敏感,許多國家對發送到云服務器這一做法有著嚴格的法規要求。總之,確保僅連接到本地網絡的設備的安全性永遠更加容易。
成本
訂購ML優化的云實例可能會非常昂貴—表1中所示的最低規格實例每小時花費約3美元。許多云提供商會收取額外的費用,例如用于存儲和網絡訪問的費用,這筆費用也要考慮在內。實際上,運行一個AI應用每月可能要花費高達3,000美元。
結論
實現成功的機器學習通常需要具有強大算力的基于云或服務器的資源。但是,隨著應用的發展和新用例的出現,將機器學習轉移到網絡邊緣變得更加引人注目,尤其是在需要優先考慮延遲、安全性和實現成本等因素的情況下。
責任編輯:haq
-
AI
+關注
關注
87文章
31000瀏覽量
269340 -
ML
+關注
關注
0文章
149瀏覽量
34667 -
機器學習
+關注
關注
66文章
8422瀏覽量
132743
發布評論請先 登錄
相關推薦
在邊緣設備上設計和部署深度神經網絡的實用框架
物聯網邊緣計算的概念
今日看點丨谷歌明年將把Tensor G5生產轉移到臺積電;京東方推出新型OLED面板原型

海康機器人推出全新一代潛伏叉取式機器人
今日看點丨谷歌將Tensor G5芯片的代工合作伙伴從三星轉移到臺積電;傳極星汽車裁員約 30%,成都工廠關停
邊緣計算與智能化網絡的結合可以實現以下哪些優勢
如何將PSoC4000部件的設計過渡到PSoC4000T部件?
如何用加載分散法將軟件中部分變量從內部RAM轉移到外部RAM?
馬斯克訪華:將討論FSD在華落地并爭取數據轉移許可
英偉達發布人形機器人基礎模型
優必選工業版人形機器人Walker S在新能源汽車工廠首次實訓
邊緣計算的應用場景介紹(邊緣計算在哪些領域能得到應用)






 工商網監
工商網監
評論