 Google氣球互聯網:用 AI 控制氣球導航,不怕 WiFi 被 “吹”出服務區
Google氣球互聯網:用 AI 控制氣球導航,不怕 WiFi 被 “吹”出服務區
更長的飛行時間,更少的能量消耗,更復雜的飛行動作。”這是 Google「氣球互聯網」項目 “Project Loon”交回的最新成績單。
Google 母公司 Alphabet 于 2013 年 6 月正式啟動 Project Loon 計劃,該計劃旨在將 AI 技術與超壓氣球相結合,為更多地區提供低價且高速的無線互聯網服務,尤其是與市中心相距甚遠的偏遠地區。
前段時間,Loon 順利完成了最新一輪飛行測試。
昨日,最新分析結果顯示,在飛躍太平洋的 39 天里,Loon 氣球表現出了比以往更好的性能——基于最新人工智能系統,它能夠更快地計算出氣球的最佳導航路徑;在目標區域上飛行的時間更長,消耗的能量更少,更關鍵的是,它還提出了研究團隊此前未曾想到過的新的導航動作。
而這一最新人工智能系統正是基于強化學習( Reinforcement-Learnin,RL)算法的 AI 系統。
研究人員稱,這是他們首次將 RL 系統應用到航空航天產品中。Loon 取得的成績,表明 RL 可以作為解決現實世界自主控制問題的有效解決方案。
目前,有關這項研究發現的論文成果已經登上了《Nature》雜志。
接下來,我們來具體聊一下:Google 為什么要開展「氣球互聯網」計劃,以及強化學習系統到底解決了哪些難題。
「氣球互聯網」計劃
你可能難以想象,在互聯網如此普及的當下,全球還有一半的以上的用戶無法享受到這項服務。
2013 年,為了讓 30 多億用戶所在的偏遠地區覆蓋互聯網,Alphabet 正式啟動了高空互聯網服務項目。之后幾年,陸續有不少科技公司也加入了這個隊伍,比如 SpaceX、OneWeb 等。
其中最值得一提的,是馬斯克的 “太空互聯網”計劃,他計劃向太空發射 42000 顆通信衛星,在地球低空軌道形成一個巨型星座來完成與地面的通信任務。目前他已經成功發射了近 900 顆衛星。
相比于馬斯克的「太空衛星」,Alpbet 則把通信業務的核心放在了「高空氣球」上。
具體來說,用「高空氣球」實現地面通信的過程如下:當氣球上升到高空平流層后(超過云層 12 英里高),利用 “太陽能技術”吸收能量以作為電力支持,然后通過 “算法系統控制( Algorithmic Control)”讓氣球上下飄動,并根據風向捕捉風流信號,將氣球穩定在一個固定區域。
最后通過 “網狀回路(Mesh Networking)技術”,將互聯網數據包從一個氣球傳輸至另一個氣球;從氣球傳輸至在屋頂建立天線的家庭和企業用戶;最后將這些用戶的數據傳輸出去。
這一過程中,如果氣球在平流層飛行的時間越長,意味著 Loon 越可以在較低成本下為目標區域提供更長久的連通性,這也意味著互聯網服務將不僅可以覆蓋到更偏遠的地區,而且它的價格也會更便宜。
在近幾年的飛行測試中,Loon 的平流層飛行時長不斷刷新著世界紀錄,目前最高成績已經達到 312 天,接近一整年。
這項最高飛行紀錄開始于 2019 年 5 月,Loon 從波多黎各(Puerto Rico)起飛,進入秘魯(Peru),然后在那里進行為期三個月的飛行測試。測試結束后,向南越過太平洋,于今年 3 月在墨西哥的巴哈(Baja)登錄。
這項記錄刷新了當時 223 天的最高記錄,Loon 首席技術官 Sal Candido 在博客中表示,創紀錄的飛行成績是該公司努力發展技術,并以創新的方式推動硬件和軟件向不斷升級的結果。
當時 Loon 的軟件系統還并未引入 RL。
目前,Loon 已經在澳大利亞、昆士蘭、肯尼亞、新西蘭、加州中央峽谷以及巴西利亞東北部等多個地區提供了 Loon 測試服務。去年,因受到颶風襲擊的影響,美國電信運營商還利用 Project Loon 為超過 25 萬的災民提供了網絡連接。
不過,在以上服務過程中,Loon 的平流層導航問題依然面臨很大的挑戰。
此次,基于 RL 系統的提出為解決當前的挑戰提供了一種全新的解決方案,與原有的氣球導航系統相比,RL 算法改善了飛行過程中的決策時間問題。
谷歌加拿大公司的研究科學家、論文一作馬克 · 貝勒馬爾(Marc Bellemare)表示,
通過強化學習,我們可以根據數據決定該如何操作,AI 不僅可以做出決策,而且可以根據移動的時間做出實時決策。
Loon:強化學習飛行控制器
如果在一個區域提供完全的網絡覆蓋,Loon 一次至少要運行 5 到 10 個氣球。如果覆蓋范圍擴大,需要調用周圍的備用氣球,在空中組建一個更大的網狀網絡。
在這一過程中,氣球一般會出現以下狀況:一是因電池報廢等因素,導致氣球壽命縮短并自動降落。二是受颶風等惡劣天氣影響,氣球被吹出固定服務區;
三是最關鍵也是難度最高的氣球導航。
上文已經提到過,Loon 的氣球導航是通過球體上下移動,尋找合適的氣流來進行導航。
如下圖(a)氣球通過在不同高度的風之間移動來接近它的指定位置。(b)顯示了氣球的飛行線路,藍色圓直徑代表 50 公里,為氣球之間的最佳距離。
但氣流是不穩定的東西。靠風在天空中移動就像使用一個道路網,在那里街道會改變方向、車道數和速度限制,甚至在不可預知的時間完全消失。
因此要做到這一點就需要一套更復雜的算法—強化學習。通過訓練飛行控制器,RL 可以形成一套控制策略,以處理高維的、異質的輸入,并優化長期目標。比如,RL 已經在 Dota 2 等即時策略性游戲中多次戰勝人類頂級玩家,而且在長遠策略方面表現驚人。
而對于一個好的飛行控制器,需要確保三點:精準且豐富和數據集,最低負載消耗以及低計算成本。
在數據集方面,研究人員根據歐洲中期天氣預報中心(ECMWF)的全球再分析數據(ERA5)創建了可信的風數據集,并通過數據集的模型訓練重新解釋歷史天氣觀測的結果。(ERA5 提供了用程序噪聲修改的基準風,通過產生高分辨率風場改變驅動程序噪聲的隨機種子,可以提高控制器建模誤差的魯棒性。)
在最低負載消耗方面,研究人員將部署控制器的平均功率控制在了 StationSeeker 之下(之前的風控制系統),同時使用獎勵 r 對目標進行了編碼。當氣球距離保持在 50 公里范圍內時,r=1 為最大值。當然這種獎勵也與氣球的狀態有關,也就是說,它的響應隨時間 t 的變化而提供不同的指示(上升、下降或停留)
當系數小于 1 時,最優控制器將使未來回報的預測折現總和最大化,即 “回報”。
其中 E 表示期望值。Rs 表示飛行控制器從初始狀態形成的長期值。
最后,計算成本主要體現在風的測量上,研究人員使用高斯過程將氣球的測量結果與 ECMWF 的預報結果相結合,將風預報作為先驗平均值。后驗分布的方差量化了不同風估計的不確定性。作為控制器的輸入,對氣球正上方和下方的風大小和相對方位進行編碼,在 181 個氣壓等級下,范圍為 5 kPa 到 14 kPa。
太平洋高空測試
基于以上 RL 控制器,研究人員在太平洋上空進行了為期 39 天的氣球導航測試。
從 2019 年 12 月 17 日—2020 年 1 月 25 日,Loon 累計飛行了約 2884 小時。這些數據被劃分為 851 個三小時時間,每個時間段作為一個獨立樣本。最終測試結果顯示,
RL 控制器在平流層內飛行的時間更長(TWR50 79% 對 72%;U=850, 410.5,P《10-4);高度控制使用的功率更少(29w 對 33w,U=1048,814,P》10-4)。
與 StationSeeker 相比,在 50 公里射程內,RL 控制器根據風況使用不同的策略,可以使其在 25-50km 射程內花費更多的時間(圖 4b);通過主動移動以返回目標區域,縮短了偏移時間(圖 4c)。同時也讓它節省了更多能耗(圖 d)最后,RL 控制器利用海拔高度將電池容量過剩的太陽能轉化為了勢能(圖 4e)。
這些結果表明,強化學習是解決現實世界中自主控制問題的有效解決方案,在傳統控制方法(StationSeeker)無法滿足要求的情況下,需要創建與真實動態環境持續交互的人工智能體。更長的飛行時間,更少的能量消耗,更復雜的飛行動作。
這是 Google「氣球互聯網」項目“Project Loon”交回的最新成績單。
Google 母公司 Alphabet 于 2013 年 6 月正式啟動 Project Loon 計劃,該計劃旨在將 AI 技術與超壓氣球相結合,為更多地區提供低價且高速的無線互聯網服務,尤其是與市中心相距甚遠的偏遠地區。
前段時間,Loon 順利完成了最新一輪飛行測試。
昨日,最新分析結果顯示,在飛躍太平洋的 39 天里,Loon 氣球表現出了比以往更好的性能——基于最新人工智能系統,它能夠更快地計算出氣球的最佳導航路徑;在目標區域上飛行的時間更長,消耗的能量更少,更關鍵的是,它還提出了研究團隊此前未曾想到過的新的導航動作。
而這一最新人工智能系統正是基于強化學習( Reinforcement-Learnin,RL)算法的 AI 系統。
研究人員稱,這是他們首次將 RL 系統應用到航空航天產品中。Loon 取得的成績,表明 RL 可以作為解決現實世界自主控制問題的有效解決方案。
目前,有關這項研究發現的論文成果已經登上了《Nature》雜志。
接下來,我們來具體聊一下:Google 為什么要開展「氣球互聯網」計劃,以及強化學習系統到底解決了哪些難題。
「氣球互聯網」計劃
你可能難以想象,在互聯網如此普及的當下,全球還有一半的以上的用戶無法享受到這項服務。
2013 年,為了讓 30 多億用戶所在的偏遠地區覆蓋互聯網,Alphabet 正式啟動了高空互聯網服務項目。之后幾年,陸續有不少科技公司也加入了這個隊伍,比如 SpaceX、OneWeb 等。
其中最值得一提的,是馬斯克的“太空互聯網”計劃,他計劃向太空發射 42000 顆通信衛星,在地球低空軌道形成一個巨型星座來完成與地面的通信任務。目前他已經成功發射了近 900 顆衛星。
相比于馬斯克的「太空衛星」,Alpbet 則把通信業務的核心放在了「高空氣球」上。
具體來說,用「高空氣球」實現地面通信的過程如下:當氣球上升到高空平流層后(超過云層 12 英里高),利用“太陽能技術”吸收能量以作為電力支持,然后通過“算法系統控制( Algorithmic Control)”讓氣球上下飄動,并根據風向捕捉風流信號,將氣球穩定在一個固定區域。
最后通過“網狀回路(Mesh Networking)技術”,將互聯網數據包從一個氣球傳輸至另一個氣球;從氣球傳輸至在屋頂建立天線的家庭和企業用戶;最后將這些用戶的數據傳輸出去。
這一過程中,如果氣球在平流層飛行的時間越長,意味著 Loon 越可以在較低成本下為目標區域提供更長久的連通性,這也意味著互聯網服務將不僅可以覆蓋到更偏遠的地區,而且它的價格也會更便宜。
在近幾年的飛行測試中,Loon 的平流層飛行時長不斷刷新著世界紀錄,目前最高成績已經達到 312 天,接近一整年。
這項最高飛行紀錄開始于 2019 年 5 月,Loon 從波多黎各(Puerto Rico)起飛,進入秘魯(Peru),然后在那里進行為期三個月的飛行測試。測試結束后,向南越過太平洋,于今年 3 月在墨西哥的巴哈(Baja)登錄。
這項記錄刷新了當時 223 天的最高記錄,Loon 首席技術官 Sal Candido 在博客中表示,創紀錄的飛行成績是該公司努力發展技術,并以創新的方式推動硬件和軟件向不斷升級的結果。
當時 Loon 的軟件系統還并未引入 RL。
目前,Loon 已經在澳大利亞、昆士蘭、肯尼亞、新西蘭、加州中央峽谷以及巴西利亞東北部等多個地區提供了 Loon 測試服務。去年,因受到颶風襲擊的影響,美國電信運營商還利用 Project Loon 為超過 25 萬的災民提供了網絡連接。
不過,在以上服務過程中,Loon 的平流層導航問題依然面臨很大的挑戰。
此次,基于 RL 系統的提出為解決當前的挑戰提供了一種全新的解決方案,與原有的氣球導航系統相比,RL 算法改善了飛行過程中的決策時間問題。
谷歌加拿大公司的研究科學家、論文一作馬克·貝勒馬爾(Marc Bellemare)表示,
通過強化學習,我們可以根據數據決定該如何操作,AI 不僅可以做出決策,而且可以根據移動的時間做出實時決策。
Loon:強化學習飛行控制器
如果在一個區域提供完全的網絡覆蓋,Loon 一次至少要運行 5 到 10 個氣球。如果覆蓋范圍擴大,需要調用周圍的備用氣球,在空中組建一個更大的網狀網絡。
在這一過程中,氣球一般會出現以下狀況:一是因電池報廢等因素,導致氣球壽命縮短并自動降落。二是受颶風等惡劣天氣影響,氣球被吹出固定服務區;
三是最關鍵也是難度最高的氣球導航。
上文已經提到過,Loon 的氣球導航是通過球體上下移動,尋找合適的氣流來進行導航。
如下圖(a)氣球通過在不同高度的風之間移動來接近它的指定位置。(b)顯示了氣球的飛行線路,藍色圓直徑代表 50 公里,為氣球之間的最佳距離。
但氣流是不穩定的東西。靠風在天空中移動就像使用一個道路網,在那里街道會改變方向、車道數和速度限制,甚至在不可預知的時間完全消失。
因此要做到這一點就需要一套更復雜的算法—強化學習。通過訓練飛行控制器,RL 可以形成一套控制策略,以處理高維的、異質的輸入,并優化長期目標。比如,RL 已經在 Dota 2 等即時策略性游戲中多次戰勝人類頂級玩家,而且在長遠策略方面表現驚人。
而對于一個好的飛行控制器,需要確保三點:精準且豐富和數據集,最低負載消耗以及低計算成本。
在數據集方面,研究人員根據歐洲中期天氣預報中心(ECMWF)的全球再分析數據(ERA5)創建了可信的風數據集,并通過數據集的模型訓練重新解釋歷史天氣觀測的結果。(ERA5 提供了用程序噪聲修改的基準風,通過產生高分辨率風場改變驅動程序噪聲的隨機種子,可以提高控制器建模誤差的魯棒性。)
在最低負載消耗方面,研究人員將部署控制器的平均功率控制在了 StationSeeker 之下(之前的風控制系統),同時使用獎勵r對目標進行了編碼。當氣球距離保持在 50 公里范圍內時,r=1 為最大值。當然這種獎勵也與氣球的狀態有關,也就是說,它的響應隨時間t的變化而提供不同的指示(上升、下降或停留)
當系數小于 1 時,最優控制器將使未來回報的預測折現總和最大化,即“回報”。
其中E表示期望值。Rs表示飛行控制器從初始狀態形成的長期值。
最后,計算成本主要體現在風的測量上,研究人員使用高斯過程將氣球的測量結果與 ECMWF 的預報結果相結合,將風預報作為先驗平均值。后驗分布的方差量化了不同風估計的不確定性。作為控制器的輸入,對氣球正上方和下方的風大小和相對方位進行編碼,在 181 個氣壓等級下,范圍為 5 kPa 到 14 kPa。
太平洋高空測試
基于以上 RL 控制器,研究人員在太平洋上空進行了為期 39 天的氣球導航測試。
從 2019 年 12 月 17 日—2020 年 1 月 25 日,Loon 累計飛行了約 2884 小時。這些數據被劃分為 851 個三小時時間,每個時間段作為一個獨立樣本。最終測試結果顯示,
RL 控制器在平流層內飛行的時間更長(TWR50 79% 對 72%;U=850, 410.5,P《10-4);高度控制使用的功率更少(29w 對 33w,U=1048,814,P《10-4)。
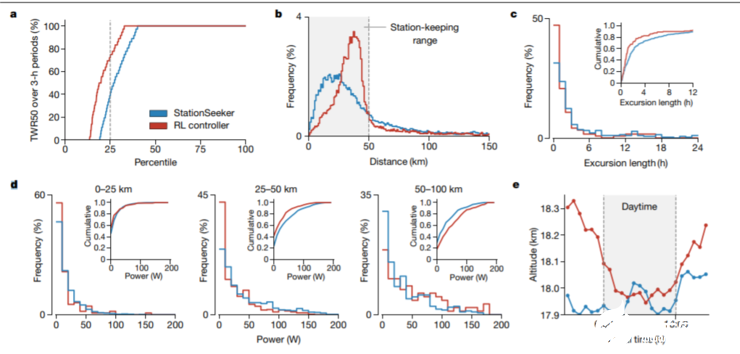
與 StationSeeker 相比,在 50 公里射程內,RL 控制器根據風況使用不同的策略,可以使其在 25-50km 射程內花費更多的時間(圖 4b);通過主動移動以返回目標區域,縮短了偏移時間(圖 4c)。同時也讓它節省了更多能耗(圖d)最后,RL 控制器利用海拔高度將電池容量過剩的太陽能轉化為了勢能(圖 4e)。
這些結果表明,強化學習是解決現實世界中自主控制問題的有效解決方案,在傳統控制方法(StationSeeker)無法滿足要求的情況下,需要創建與真實動態環境持續交互的人工智能體。
責任編輯:PSY
-
Google
+關注
關注
5文章
1766瀏覽量
57616 -
互聯網
+關注
關注
54文章
11166瀏覽量
103460 -
AI
+關注
關注
87文章
31097瀏覽量
269431
發布評論請先 登錄
相關推薦
云互聯網是什么意思
高速服務區充電樁遠程監控運維管理系統方案
高速服務區供水泵站智能管理系統方案
Cloudflare發布2024年度互聯網流量趨勢報告
Coremail亮相世界互聯網大會“互聯網之光”博覽會

淺談高速公路服務區光儲充電站運行解決方案

中國高速服務區加油站應用觸摸屏查詢一體機智慧便民

ESP8266無法連接到互聯網是怎么回事?
【HZHY-AI300G智能盒試用連載體驗】+ 智能工業互聯網網關
esp8266已連接到Wifi但無法連接到互聯網,為什么?
工業互聯網平臺中什么是關鍵
什么是衛星互聯網?衛星互聯網的組成






 工商網監
工商網監
評論