 sklearn的API參數解析:sklearn.linear_model.LinearRegression
sklearn的API參數解析:sklearn.linear_model.LinearRegression
sklearn.linear_model.LinearRegression
調用
sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)
Parameters
fit_intercept
釋義:是否計算該模型的截距。
設置:bool型,可選,默認True,如果使用中心化的數據,可以考慮設置為False,不考慮截距。
normalize
釋義:是否對數據進行標準化處理
設置:bool型,可選,默認False,建議將標準化的工作放在訓練模型之前,通過設置sklearn.preprocessing.StandardScaler來實現,而在此處設置為false
當fit_intercept設置為false的時候,這個參數會被自動忽略。
如果為True,回歸器會標準化輸入參數:減去平均值,并且除以相應的二范數
copy_X
釋義:是否對X復制
設置:bool型、可選、默認True,如為false,則即經過中心化,標準化后,把新數據覆蓋到原數據上
n_jobs
釋義:計算時設置的任務個數,這一參數的對于目標個數>1(n_targets>1)且足夠大規模的問題有加速作用
設置:int or None, optional, 默認None,如果選擇-1則代表使用所有的CPU。
Attributes
coef_
釋義:對于線性回歸問題計算得到的feature的系數
輸出:如果輸入的是多目標問題,則返回一個二維數組(n_targets, n_features);
如果是單目標問題,返回一個一維數組 (n_features,)
rank_
釋義:矩陣X的秩,僅在X為密集矩陣時有效
輸出:矩陣X的秩
singular_
釋義:矩陣X的奇異值,僅在X為密集矩陣時有效
輸出:array of shape (min(X, y),)
intercept_
釋義:截距,線性模型中的獨立項
輸出:如果fit_intercept = False,則intercept_為0.0
Methods
fit(self, X, y[, sample_weight])
訓練模型,,sample_weight為每個樣本權重值,默認None
get_params(self[, deep])
deep默認為True,返回一個字典,鍵為參數名,值為估計器參數值
predict(self, X)
模型預測,返回預測值
score(self, X, y[, sample_weight])
模型評估,返回R^2系數,最優值為1,說明所有數據都預測正確
set_params(self, **params)
設置估計器的參數,可以修改參數重新訓練
本文由博客一文多發平臺 OpenWrite 發布!
審核編輯:符乾江
-
機器學習
+關注
關注
66文章
8422瀏覽量
132743 -
深度學習
+關注
關注
73文章
5504瀏覽量
121248
發布評論請先 登錄
相關推薦
芯盾時代入選《API安全技術應用指南(2024版)》API安全十大代表性廠商
IP風險畫像詳細接入規范、API參數(Ipdatacloud)

api驅動的云服務是什么意思?
使用OpenVINO Model Server在哪吒開發板上部署模型
API :軟件程序間溝通的橋梁
請問Scene Server Model的state值應該怎樣設置?
兩種集成方案靈活搭建遠控方案,向日葵API集成方案解析
華為云發布 CodeArts API,為 API 護航

OpenAI API Key獲取與充值教程:助開發者解鎖GPT-4.0 API
API安全風險顯現,F5助API實現可信訪問
特斯拉Model 3用了哪些芯片?
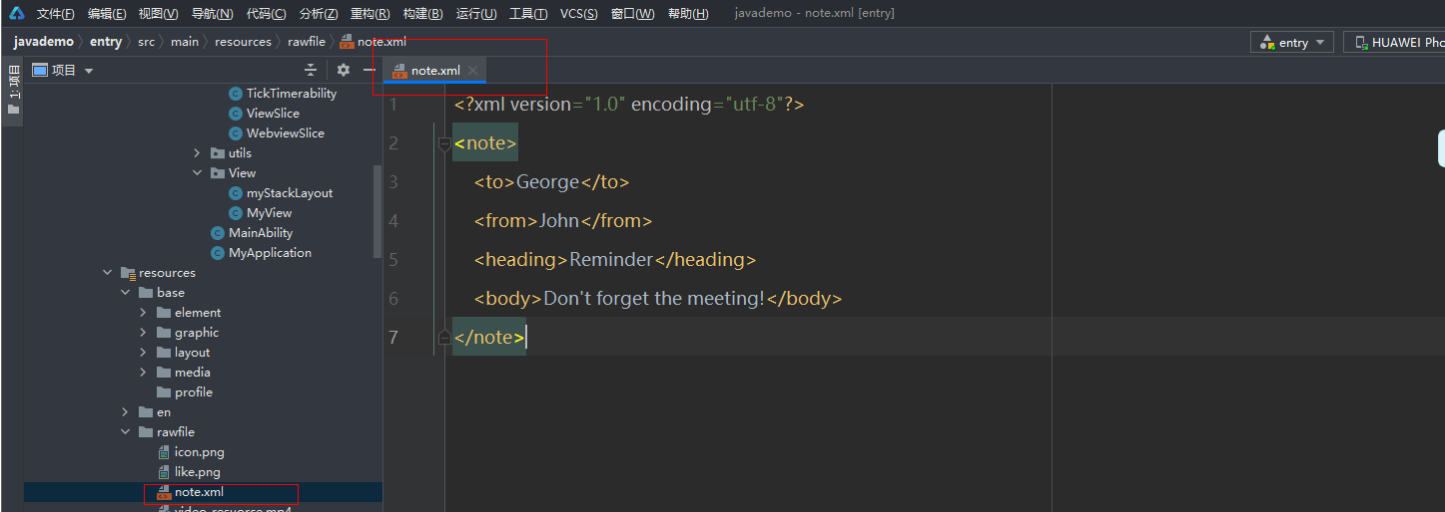
【JAVA UI】【HarmonyOS】【Demo】 鴻蒙如何進行 xml 解析
Kubernetes Gateway API攻略教程





 工商網監
工商網監
評論