 AI的下一次機遇在哪里
AI的下一次機遇在哪里
AI 的下一次機遇在哪里?
自 1956 年 AI 的概念首次被提出,至今已有 60 多年的發展史。如今,隨著相關理論和技術的不斷革新,AI 在數據、算力和算法“三要素”的支撐下越來越多地走進我們的日常生活。
但是,這一系列驚喜的背后,卻是大多數 AI 在語言理解、視覺場景理解、決策分析等方面的舉步維艱:這些技術依然主要集中在感知層面,即用 AI 模擬人類的聽覺、視覺等感知能力,卻無法解決推理、規劃、聯想、創作等復雜的認知智能化任務。
當前的 AI 缺少信息進入“大腦”后的加工、理解和思考等,做的只是相對簡單的比對和識別,僅僅停留在“感知”階段,而非“認知”,以感知智能技術為主的 AI 還與人類智能相差甚遠。
究其原因在于,AI 正面臨著制約其向前發展的瓶頸問題:大規模常識知識庫與基于認知的邏輯推理。而基于知識圖譜、認知推理、邏輯表達的認知圖譜,則被越來越多的國內外學者和產業領袖認為是“目前可以突破這一技術瓶頸的可行解決方案之一”。
唐教授簡單介紹了人工智能的三個時代:符號智能 —— 感知智能 —— 認知智能。提出現在需要探討的問題是:計算機有沒有認知?計算機能不能做推理?甚至計算機到未來有沒有意識能夠超過人類? 唐教授表示,當前認知 AI 還沒有實現,我們急需做的是一些基礎性的東西(AI 的基礎設施),比如知識圖譜的構建,知識圖譜的一些認知邏輯,包括認知的基礎設施等。 從 1950 年開始創建人工智能系統,到 1970 年開始深入的讓計算機去模仿人腦,再到 1990 年計算機學家意識到計算機是 “參考” 人腦而不是完全的 “模仿”。
現在我們更是處于一個計算機的變革時代,我們應該用更多的計算機思維來做計算機的思考,而不是人的思考。 現在人們需要思考的是:如何以計算機的方式做認知?唐教授談到,可以結合兩種方法去實現。 第一個從大數據的角度上做數據驅動,把所有的數據進行建模,并且學習數據之間的關聯關系,學習數據的記憶模型;第二個是要用知識渠道,構建知識圖譜。 不過,只這兩個方面還是遠遠不夠的。唐教授指出:真正的通用人工智能,我們希望它有持續學習的能力,能夠從已有的事實、從反饋中學習到新的東西,能夠完成一些更加復雜的任務。 唐教授從人的認知和意識中抽象出來了 9 個認知 AI 的準則:
適應與學習能力
定義與語境化能力
自我系統的準入能力
優先級與訪問控制能力
召集與控制能力
決策與執行能力
錯誤探測與編輯能力
反思與自我監控能力
條理與靈活性之間的能力
在這 9 個準則的基礎上,提出了一個全新的認知圖譜的概念,包括三個核心:
常識圖譜。比如說高精度知識圖譜的構建,領域制度的應用系統,超大規模城市知識圖譜的構建,還有基于知識圖譜的搜索和推薦等。
邏輯生成。與計算模型相關,需要超大規模的預訓練模型,并且能夠自動進行內容生成。
認知推理。即讓計算機有邏輯推理和思維能力,像人一樣思考。
唐教授表示,知識圖譜+深度學習+認知心理,打造知識和認知推理雙輪驅動的框架,將是接下來一個重要的研究方向。
目前,項目關鍵技術已經通過成果轉化孵化了北京智譜華章科技有限公司(簡稱智譜·AI),形成多個核心產品,在阿里巴巴、搜狗、華為、騰訊、點通、中國工程院等 30 余家企事業單位部署了超過 100 余套智能型云服務系統,應用前景極其廣闊。
這家 AI 明星創業公司致力于打造可解釋、魯棒、安全可靠、具有推理能力的新一代認知引擎,用 AI 賦能科技創新。依托清華大學團隊十余年在知識智能方面的積累和人才優勢,智譜?AI如今已經構造了高質量大規模知識圖譜、研發了深度隱含關聯挖掘算法和認知圖譜等核心關鍵技術,擁有完全自主知識產權,服務于政府部門、企業和科研機構。 在 2020 年中國人工智能年度評選中,智譜?AI 也獲得 AI 明星創業公司 TOP10 及最佳解決方案 TOP10 兩個獎項。以下為唐教授演講實錄(稍有刪減): 為什么叫認知圖譜?首先來看一下人工智能發展的脈絡,從最早的符號智能,再到后面的感知智能,再到最近,所有人都在談認知智能。我們現在需要探討計算機有沒有認知,計算機能不能做認知,計算機能不能做推理,甚至計算機到未來有沒有意識,能夠超過人類。 人工智能發展到現在已經有三個浪潮,我們把人工智能叫做三個時代,三個時代分別是符號 AI、感知 AI 和認知 AI。認知 AI 到現在沒有實現,我們正在路上。
那現在急需的東西是什么?是一些基礎性的東西,比如說里面的認知圖譜怎么構建,里面認知的一些邏輯,包括認知的基礎設施怎么建,這是我們特別想做的一件事情。
做這個之前,我們首先回顧一下機器學習。提到機器學習,很多人立馬就說我知道機器學習有很多分類模型,比如說決策樹,這里最左邊列出了分類模型、序列模型、概率圖模型,再往右邊一點點就是最大化邊界,還有深度學習,甚至再往下循環智能,再往右就是強化學習,深度強化學習,以及最近我們大家提到更多的無監督學習,這是機器學習的一個檔位。那么,機器學習離我們的認知,到底還有多遠呢?我們要看一看這個認知以及人的思考,包括人的認知到底怎么回事。
于是,我看了很多諾貝爾獎和圖靈獎得主的資料,大概整理出了這樣一頁 PPT。下面是人的思考,在人的思考中得到所有的模型,上面是計算機圖靈獎跟認知相關的信息。在 1900 年初的時候,就有神經系統結構。后來到 1932 年左右有神經元突觸的一個諾獎,再到 60 年代有神經末梢傳遞機制,到 1975 年左右有了視覺系統,到近年也就是 20 年前才有了嗅覺系統,直到二零一幾年的時候我們才有了大腦怎么定位導航,以及大腦的機理是怎么回事,這是諾獎。 我們看一下計算機怎么思考的,即機器思考。
在 1950 年左右創立了人工智能系統,但是 1970 年左右大家開始拼命去模仿人腦,我們要做一個計算機,讓他跟人腦特別相同。但到 1990 年左右,計算機學家們突然發現我們沒有必要模仿,我們更多的是要參考人腦,參考腦系統,做一個讓計算機能做更多的機器思考,機器思維。所以我們在這個時代,可以說是一個計算機革命的一個變革,我們用更多的計算機思維來做計算,來做計算機的思考,而不是人的思考。 最后,我們出現了概率圖模型、概率與因果推理還有最近的深度學習。當然,有人會說,到最后你還在講機器學習,在講一個模型,這個離我們真正的是不是太遠了?
我舉另外一個例子,Open AI。我們要建造一個通用人工智能,讓計算機系統甚至能夠超越人,在過去幾年連我自己都不信,我覺得通用人工智能很難實現。Open AI 做了幾個場景,在受限場景下,比如游戲環境下已經打敗了人類。上面的幾個案例甚至開放了一些強化學習的一些框架,讓大家可以在框架中進行編程。 下面就是最近幾年最為震撼的。兩年前 Open AI 做了 GPT,很簡單,所有人就覺得是語言模型,并沒有做什么事情;去年做的 GPT-2,這時候做出來的參數模型也沒有那么大,幾十億的參數模型做出來的效果,我估計很多人都玩過,有一個 Demo,叫 talk to transformer,就是跟翻譯來對話,你可以輸入任何文本,transformer 幫你把文本補齊。
但是今年 6 月份的時候,Open AI 發布了一個 GPT-3,這個模型,參數規模一下子達到了 1750 億,數量級接近人類的神經元的數量,這個時候給我們一個震撼的結果,計算機的參數模型,至少它的表示能力已經接近人類了。有可能效果還不如,但是它的表示能力已經接近人類了,也就是說在某種理論證明下,如果我們能夠讓計算機的參數足夠好足夠充足的話,他可能就能跟人的這種智商表現差不多。 這時候給我們另外一個啟示,我們到底是不是可以直接通過計算機的結果,也就是計算的方法得到一個超越人類的通用人工智能?
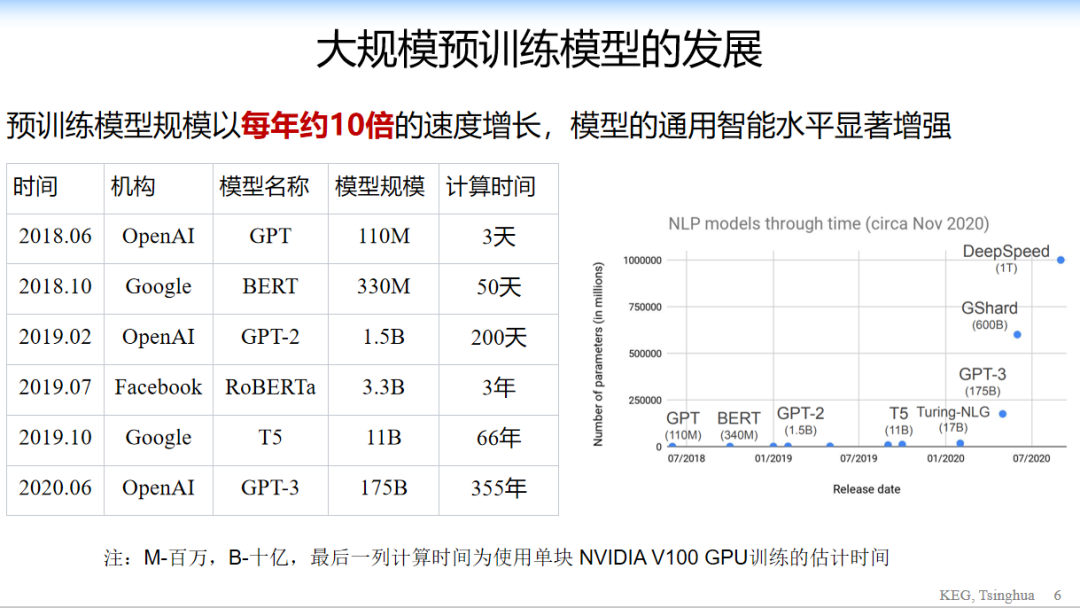
我們來看一下,這是整個模型過去幾年發展的結果。幾乎每年參數規模是 10 倍左右的增長,右邊的圖給出了自然語言處理中最近幾年的快速變化,幾乎是一個指數級的變化,可以看到,前幾年變化相對比較小,今年出了 GPT-3,谷歌到了 6000 億的產出規模,明年可能還會到萬億級別。所以這是一個非常快速的增長。 現在給我們另外一個問題,我們到底能不能用這種大規模、大算力的方法,大計算的方法,來實現真正的人工智能呢?
這是一個問題。 當然另外一方面,大家看到也是另外一個痛點,所有訓練的結果,大家看一下,GPT-3 如果用單卡的訓練需要 355 年,整個訓練的成本達到幾億的人民幣,一般的公司也做不起來。現在另外一個問題就是,就算是有美團這樣的大公司做了這個模型,是不是大家都可以用了,是不是就夠了? 這是一個例子,左邊是模型,右邊是結果。第一個是長頸鹿有幾個眼睛?GPT-3 說有兩個眼睛,沒有問題。第二個,我的腳有幾個眼睛?結果是也有兩個眼睛,這就錯了。第三個是蜘蛛有幾個眼睛?
8 個眼睛。第四個太陽有幾個眼睛?一個眼睛。最后一個呢,一根草有幾個眼睛?一個眼睛。 可以看到,GPT-3 很聰明,可以生成所有的結果,這個結果是生成的,自動生成出來的,但是它有一個阿喀琉斯之踵,它其實沒有常識。 我們需要一個常識的知識圖譜。 2012 年的時候谷歌發出了一個 Knowledge Graph,就是知識圖譜,當時概念就是,我們利用大量的數據能不能建一個圖譜?
于是在未來的搜索中,我們自動把搜索結果結構化,自動結構化的數據反饋出來。知識圖譜不僅可以包括搜索引擎,另外一方面可以給我們計算帶來一些常識性的知識,能不能通過這個方法幫助我們未來的計算呢,這給我們引出了另外一個問題。 其實知識圖譜在很多年前就已經發展,從第一代人工智能,就是符號 AI 的時候就開始在做,當時就在定義知識圖譜,就在定義這個符號 AI 的邏輯表示,70 年代叫知識工程,但是為什么到現在知識圖譜還沒有大規模的發展起來? 第一,構建的成本非常的高,如果你想構建得很準的話,人工成本非常高。
你看 CYC 在 90 年代發展起來的,定義一個知識斷言的成本,就是一個 ABC 三元組,A 就是主體,B 就是關系,C 是受體,比如說人有手,人就是主體,有就是關系,手就是受體,就是這么簡單的一個問題,當時的成本就是 5.7 美元。另外一個項目,用互聯網完全自動方法的生成出來,錯誤率一下提高的 10 倍,這兩個項目目前基本上處于半停滯狀態。 那怎么辦呢?我們現在就在思考,從計算角度上看認知,究竟應該怎么做?如果還用計算做認知,該怎么實現?如果把剛才兩個東西結合起來應該有這么一個模型。
第一,從大數據的角度,做數據驅動,我們用深度學習舉十反一的方法,把所有的數據進行建模,并且學習數據之間的關聯關系,學習數據的記憶模型。 第二,我們要用知識驅動,構建一個知識圖譜,用知識驅動整個事情。我們把兩者結合起來,這也許是我們解決未來認知 AI 的一個關鍵。 那夠不夠呢?答案是不夠,我們的未來是需要構建一個真正能夠超越原來的,超越已有模型的一個認知模型。這樣的認知模型,它首先要超越 GPT-3 這樣的預設模型,我們需要一個全新的架構框架,也需要一個全新的目標函數,這時候我們才有可能超過這樣的預訓練模型,否則我們就是在跟隨。

舉幾個例子,這是我們最近嘗試做的一件事情。這兩個,大家覺得哪個是人做的?哪個是機器做的?其實這兩個都是機器做出來的,這是我學生做出來的一個來給大家娛樂的。其實下面這個結果都不大對,內容也是不對的,上面這個結果也是完全由機器生成出來的。但是你看一下邏輯基本上可行,就是目前我們需要做的是,讓機器有一定的創造能力,光文本還不夠,我們希望創造出真正的圖片,它是創造,不是查詢。
這里有一篇文字,我們希望通過這篇文字能夠把原來的原圖自動生成新的圖片,這個圖片是生成出來的,我們希望這個機器有創造能力。當然,光創造還不夠,我們離真正通用的人工智能還有多遠?我們希望真正的通用人工智能能有持續學習的能力,能夠從已有的事實,從反饋中學習到新的東西,能夠完成一些更加復雜的任務。
這時候一個問題來了,什么叫認知?只要做出可持續學習就是認知嗎?如果這樣的話 GPT-3 也有這種學習的能力,知識圖譜也有學習的能力,因為它在不停的更新。如果能完成一些復雜任務就是認知嗎?也不是,我們有些系統已經可以完成非常復雜的問題。什么是認知呢?于是我們最近通過我們的一些思考,我們定義了認知 AI 的九準則。這九個準則是我從人的認知和意識中抽象出來的九個準則。
第一個,叫適應與學習能力,當一個機器在特定的環境下,比如說我們今天的 MEET 大會,這個機器人自動的學習,它能知道我們在這種模型下,在這個場景下應該做什么事情。
第二個,叫定義與語境能力,這個模型它能夠在這個環境下感知上下文,能做這樣的一個環境的感知。
第三個,叫自我系統的準入能力,我們描述的是這個機器它能夠自定義什么是我,什么是非我,這叫人設。如果這個機器能知道自己的人設是什么,那么我們認為它有一定的認知能力。
第四個,優先級與訪問控制能力,在一定的特定場景下它有選擇的能力。我們人都可以在雙十一選擇購物,如果機器在雙十一的時候能選擇我今天想買點東西,明天后悔了,不應該買,這時候這個機器有一定的優先級和訪問控制。
第五個,召集與控制能力,這個機器應該有統計和決策的能力。
第六個,決策與執行能力,這個機器人在感知到所有的數據以后它可以做決策。
第七個,錯誤探測與編輯能力,這個非常重要,人類的很多知識,其實是在試錯中發現的,比如我們現在學的很多知識,我們并不知道什么知識是最好的,我們在不停的試錯,也許我們今天學到了 1+1 等于 2 是很好,但是你嘗試1+1 等于 3,1+1 等于 0,是不是也可以呢?你嘗試完了發現都不對,這叫做錯誤探測與編輯,讓機器具有這個能力,非常地重要。
第八個,反思與自我控制、自我監控,如果這個機器人在跟你聊天的過程中,聊了很久,說“不好意思我昨天跟你說的一句話說錯了,我今天糾正了。”這時候機器具有反思能力。
最后,這個機器一定要有條理和理性。
我們把這些叫做認知 AI 的九準則。在九個準則的基礎上,我們提出一個全新的認知圖譜的概念。
常識圖譜有三個核心的要素。第一,常識圖譜,比如說高精度知識圖譜的構建、領域知識圖譜的應用系統、超大規模知識圖譜的構建,還有基于知識圖譜的搜索和推薦,這是傳統的一些東西。 第二,跟我們計算模型非常相關,我們叫邏輯生成,這時候需要超大規模的預訓練模型,并且能夠自動進行內容生成。同時我們在未來可以構建一個數字人的系統,它能夠自動的在系統中,能夠生成相關的東西,能夠做得像人一樣的數字人。 第三,需要認知推理,需要有認知推理的能力,讓計算機有推理、有邏輯的能力。
說起來比較虛,大家會問什么叫推理邏輯?人的認知有兩個系統,一個叫系統 1,一個叫系統 2,系統 1 就是計算機做的匹配,你說清華大學在哪,它立刻匹配出來在北京,但是你說清華大學在全球計算機里面到底排在第幾?以及為什么排在第幾?這時候就需要一些邏輯推理,這時候計算機就回答不了,這時候需要做邏輯推理,我們要思考優勢在哪,人思考的時候叫系統 2,慢系統,里面要做更多復雜的邏輯思考。我們當前所有的深度學習都是做系統 1,解決了系統 1 問題,是直覺認知,而不是邏輯認知。我們未來要做更多的就是系統 2 的事情。
我們從腦科學來看,相對現在做的事情有兩個最大的不同,第一,就是記憶,第二就是推理。記憶是通過海馬體實現,認知是前額葉來實現,這兩個系統非常關鍵,怎么實現呢?我們看記憶模型,巴德利記憶模型分三層,短期記憶就是一個超級大的大數據模型,在大數據模型中,我們怎么把大數據模型中有些信息變成一個長期記憶,變成我們知識,這就是記憶模型要做的事情。 當然從邏輯推理下,還有更多的事情要做,那我們現在怎么辦?認知圖譜核心的東西就變成我們需要知識圖譜,也需要深度學習,我們還要把認知心理的一些東西結合進來,來構造一個新的模型。
于是,最后一頁,我們構建了這樣一個框架,這個框架左邊是一個查詢接口,這是輸入,你可以說用戶端,中間是一個超大規模的預訓練模型,一個記憶模型,記憶模型通過試錯、蒸餾,把一些信息變成一個長期記憶存在長期記憶模型中,長期記憶模型中會做無意識的探測,也會做很多自我定義和條例的邏輯,并且做一些認知的推理。在這樣的基礎上我們構建一個平臺,目標是打造一個知識和認知推理雙輪驅動的一個框架。底層是分布式的存儲和管理,中間是推理、決策、預測,再上面是提供各式各樣的 API。
責任編輯:xj
原文標題:【峰咖】清華大學唐杰教授:認知圖譜是人工智能的下一個瑰寶
文章出處:【微信公眾號:機器人峰會】歡迎添加關注!文章轉載請注明出處。
-
AI
+關注
關注
87文章
30728瀏覽量
268892 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238266
原文標題:【峰咖】清華大學唐杰教授:認知圖譜是人工智能的下一個瑰寶
文章出處:【微信號:robotop2025,微信公眾號:每日機器人峰匯】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ADS1256第一次上電的時候,采集的ADC信號是實際值的一半,為什么?

AI崛起背景下,MEMS傳感器的出路在哪里
一次電源與二次電源有什么不同
一次電池分類以及應用場景詳解


labview如何做到一次觸發采集一次
ESP8266如何進行OTA更新,但無需重新啟動?
一次消諧器的構造
STM32F407 PWM輸出時一次中斷未執行完下一次中斷就進入,導致PWM波形輸出紊亂怎么解決?
基波是一次諧波么 基波與一次諧波的區別
基于百度AI大模型生態支持,極越汽車機器人迎來一次全新進化






 工商網監
工商網監
評論