") 工業(yè)互聯(lián)網(wǎng)時(shí)代:我們?yōu)槭裁葱枰獣r(shí)序數(shù)據(jù)庫(kù)之二
工業(yè)互聯(lián)網(wǎng)時(shí)代:我們?yōu)槭裁葱枰獣r(shí)序數(shù)據(jù)庫(kù)之二
在上周的格物匯文章中,我們給大家介紹過(guò),目前國(guó)內(nèi)外主流工業(yè)互聯(lián)網(wǎng)平臺(tái)幾乎都是采用時(shí)序數(shù)據(jù)庫(kù)來(lái)承接海量涌入的工業(yè)數(shù)據(jù)。那為什么強(qiáng)大的Oracle、PostgreSQL 等傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)搞不定時(shí)序數(shù)據(jù)?為什么不用HBase、MongoDB、Cassandra等先進(jìn)的分布式數(shù)據(jù)庫(kù)來(lái)解決工業(yè)數(shù)據(jù)問(wèn)題?
作為資深“杠精”,當(dāng)然需要先知道要“杠”的到底是什么?就時(shí)序數(shù)據(jù)庫(kù)而言,就是要“杠”兩個(gè)東西:1、“杠”數(shù)據(jù);2、“杠”數(shù)據(jù)庫(kù)。
先從數(shù)據(jù)“杠”起,數(shù)據(jù)可是一個(gè)高深莫測(cè)的東西。
想當(dāng)年圖靈用他深邃的眼睛,看穿了世間萬(wàn)物的計(jì)算本質(zhì):凡是可以計(jì)算的,通過(guò)迭代,最終都可以表示為0、1的邏輯判斷。圖靈機(jī)需要一個(gè)無(wú)限長(zhǎng)的紙帶來(lái)表征和記錄計(jì)算,這無(wú)限長(zhǎng)的紙帶上記錄的0、1的組合,就是數(shù)據(jù)最原始的抽象。圖靈機(jī)指出了數(shù)據(jù)的3個(gè)核心需求:1、數(shù)據(jù)存儲(chǔ);2、數(shù)據(jù)寫入;3、數(shù)據(jù)讀取。
可以說(shuō),目前所有數(shù)據(jù)庫(kù)、文件系統(tǒng)等等,都是為了以最佳性價(jià)比來(lái)滿足數(shù)據(jù)的這三個(gè)核心需求。對(duì)時(shí)序數(shù)據(jù)而言,其三個(gè)核心需求特征十分明顯:
數(shù)據(jù)寫入
時(shí)間是一個(gè)主坐標(biāo)軸,數(shù)據(jù)通常按照時(shí)間順序抵達(dá)
大多數(shù)測(cè)量是在觀察后的幾秒或幾分鐘內(nèi)寫入的,抵達(dá)的數(shù)據(jù)幾乎總是作為新條目被記錄
95%到99%的操作是寫入,有時(shí)更高
更新幾乎沒(méi)有
數(shù)據(jù)讀取
隨機(jī)位置的單個(gè)測(cè)量讀取、刪除操作幾乎沒(méi)有
讀取和刪除是批量的,從某時(shí)間點(diǎn)開(kāi)始的一段時(shí)間內(nèi)
時(shí)間段內(nèi)讀取的數(shù)據(jù)有可能非常巨大
數(shù)據(jù)存儲(chǔ)
數(shù)據(jù)結(jié)構(gòu)簡(jiǎn)單,價(jià)值隨時(shí)間推移迅速降低
通過(guò)壓縮、移動(dòng)、刪除等手段降低存儲(chǔ)成本
而關(guān)系數(shù)據(jù)庫(kù)主要應(yīng)對(duì)的數(shù)據(jù)特點(diǎn):
(1)數(shù)據(jù)寫入:大多數(shù)操作都是DML操作,插入、更新、刪除等;
(2)數(shù)據(jù)讀取:讀取邏輯一般都比較復(fù)雜;
(3)數(shù)據(jù)存儲(chǔ):很少壓縮,一般也不設(shè)置數(shù)據(jù)生命周期管理。
因此,從數(shù)據(jù)本質(zhì)的角度而言,時(shí)序數(shù)據(jù)庫(kù)(不變性, 唯一性以及可排序性)和關(guān)系型數(shù)據(jù)庫(kù)的服務(wù)需求完全不同。
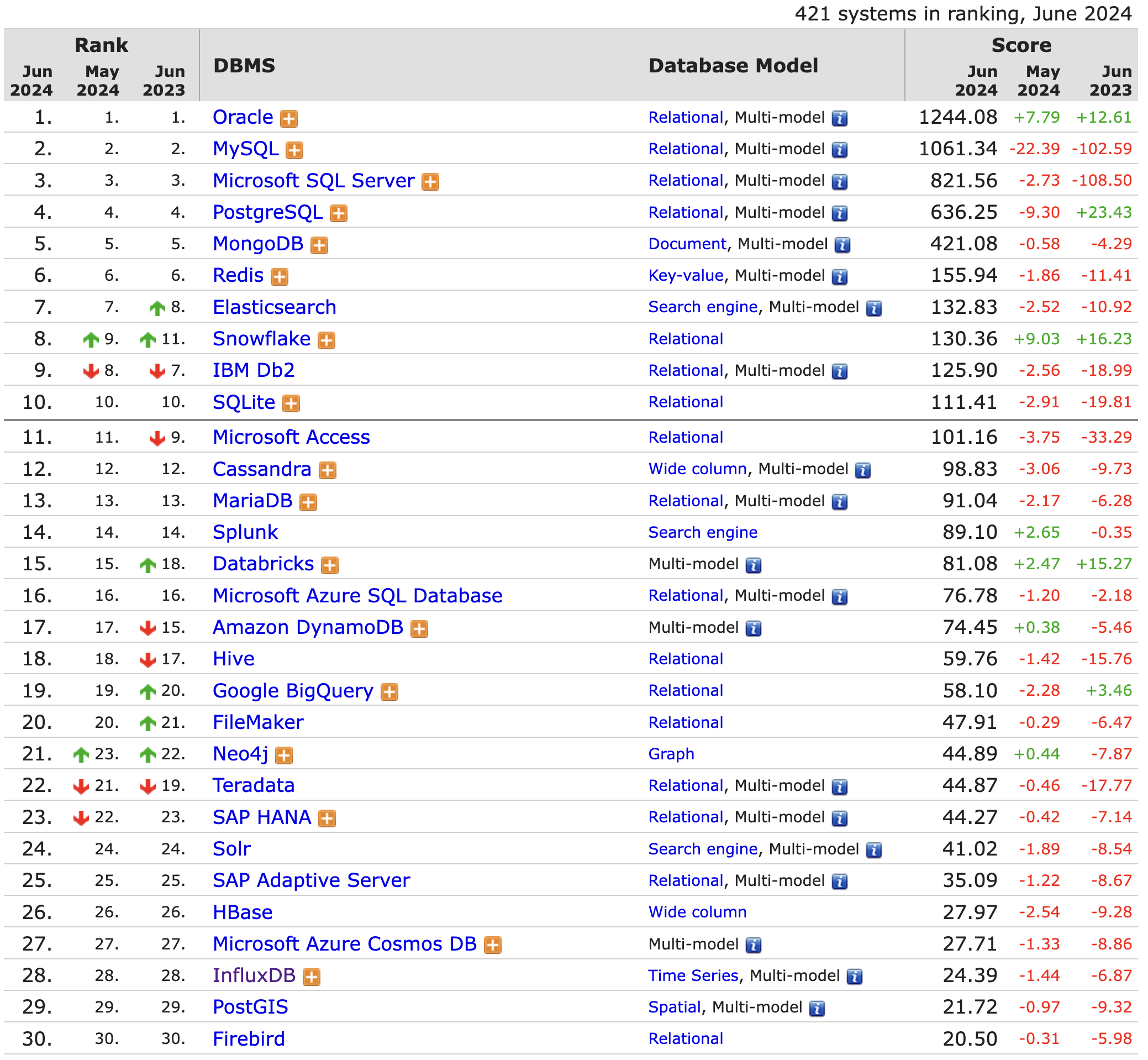
再說(shuō)說(shuō)數(shù)據(jù)庫(kù)。數(shù)據(jù)庫(kù)系統(tǒng)的發(fā)展從20世紀(jì)60年代中期開(kāi)始到現(xiàn)在,經(jīng)歷若干代演變,造就了C.W. Bachman(巴克曼)、E.F.Codd(考特)和J. Gray(格雷)三位圖靈獎(jiǎng)得主,發(fā)展了以數(shù)據(jù)科學(xué)、數(shù)據(jù)建模和數(shù)據(jù)庫(kù)管理系統(tǒng)(DBMS)等為核心理論、技術(shù)和產(chǎn)品的一個(gè)巨大的軟件產(chǎn)業(yè)(詳見(jiàn)下圖)。
從上圖可以得出一個(gè)結(jié)論,針對(duì)不同的數(shù)據(jù)需求,應(yīng)該有不同的數(shù)據(jù)庫(kù)系統(tǒng)應(yīng)對(duì)之。否則,也沒(méi)有必要出現(xiàn)這么多種的數(shù)據(jù)庫(kù)系統(tǒng)了。
時(shí)間序列數(shù)據(jù)跟關(guān)系型數(shù)據(jù)庫(kù)有太多不同,但是很多公司并不想放棄關(guān)系型數(shù)據(jù)庫(kù)。于是就產(chǎn)生了一些特殊的用法,比如:用 MySQL 的 VividCortex, 用 Postgres 的 TimescaleDB;當(dāng)然,還有人依賴K-V、NoSQL數(shù)據(jù)庫(kù)或者列式數(shù)據(jù)庫(kù)的,比如:OpenTSDB的HBase,而Druid則是一個(gè)不折不扣的列式存儲(chǔ)系統(tǒng);更多人覺(jué)得特殊的問(wèn)題需要特殊的解決方法,于是很多時(shí)間序列數(shù)據(jù)庫(kù)從頭寫起,不依賴任何現(xiàn)有的數(shù)據(jù)庫(kù), 比如: Graphite,InfluxDB。
對(duì)選擇數(shù)據(jù)庫(kù)的開(kāi)發(fā)者和使用者而言,針對(duì)時(shí)序數(shù)據(jù)庫(kù)和關(guān)系型數(shù)據(jù)庫(kù)之間選擇,也主要考慮以下幾個(gè)因素:
性能
研究過(guò)Oracle的存儲(chǔ)結(jié)構(gòu)和索引結(jié)構(gòu)的都知道Oracle的ACID強(qiáng)一致性和B-Tree,保證強(qiáng)一致性導(dǎo)致數(shù)據(jù)持久化、可靠性、可用性實(shí)現(xiàn)的邏輯復(fù)雜,而加速數(shù)據(jù)訪問(wèn),則需要Oracle 數(shù)據(jù)庫(kù)使用 B-Tree 存儲(chǔ)索引。
B-Tree 結(jié)構(gòu)的有很多優(yōu)勢(shì):在索引中從任何地方檢索任何記錄都大約花費(fèi)相同的時(shí)間;B-Tree對(duì)大范圍查詢提供優(yōu)秀的檢索性能,包括精確匹配和訪問(wèn)查詢;插入、更新和刪除操作有效,維護(hù)鍵的順序,以便快速檢索;B-Tree性能對(duì)小表和大表都很好,不會(huì)隨著表的增長(zhǎng)而降低。從Tree這個(gè)名字就可以看出,這種B-Tree就是為了解決隨機(jī)讀寫問(wèn)題的。
而時(shí)序數(shù)據(jù)庫(kù),核心問(wèn)題去解決批量讀寫,對(duì)于 95% 以上場(chǎng)景都是寫入的時(shí)序數(shù)據(jù)庫(kù),B-Tree 很明顯是不合適的,業(yè)界主流都是采用 LSM Tree(Log Structured Merge Tree)或者LSM的“升級(jí)版”TSM(Time Sort Merge Tree) 替換 B-Tree,比如 Hbase、Cassandra、InfluxDB等。LSM Tree 核心思想就是通過(guò)內(nèi)存寫和后續(xù)磁盤的順序?qū)懭氆@得更高的寫入性能,避免了隨機(jī)寫入。
LSM Tree 簡(jiǎn)單操作流程如下:
數(shù)據(jù)寫入和更新時(shí)首先寫入位于內(nèi)存里的數(shù)據(jù)結(jié)構(gòu)。同時(shí),為了避免數(shù)據(jù)丟失也會(huì)先寫到磁盤文件中。
內(nèi)存里的數(shù)據(jù)結(jié)構(gòu)會(huì)定時(shí)或者達(dá)到固定大小會(huì)刷到磁盤。
隨著磁盤上積累的文件越來(lái)越多,會(huì)定時(shí)的進(jìn)行合并操作,減少文件數(shù)量。
在內(nèi)存or文件中,對(duì)數(shù)據(jù)進(jìn)行壓縮、去重等操作。
還有一個(gè)提升性能的關(guān)鍵點(diǎn),即:分布式處理。這里以InfluxDB為例來(lái)說(shuō)明。(順便吐槽一下:InfluxDB單機(jī)版開(kāi)源,集群版收費(fèi)……,扔個(gè)魚(yú)餌,“吃相”難看呀。)
上圖是InfluxDB的邏輯存儲(chǔ)架構(gòu)圖,通過(guò)RP、ShardGroup、Shard的逐層分解,寫入數(shù)據(jù)被盡可能的分布攤平。最后,每個(gè)Shard的TSM引擎負(fù)責(zé)對(duì)數(shù)據(jù)進(jìn)行處理。Shard Group實(shí)現(xiàn)了數(shù)據(jù)分區(qū),但是Shard才是InfluxDB中真正存儲(chǔ)數(shù)據(jù)以及提供讀寫服務(wù)的服務(wù)。Shard是InfluxDB的TSM Engine,負(fù)責(zé)數(shù)據(jù)的編碼存儲(chǔ)、讀寫服務(wù)等。
通常分布式數(shù)據(jù)庫(kù)一般有兩種Sharding策略:Range Sharding和Hash Sharding,前者對(duì)于基于主鍵的范圍掃描比較高效;后者對(duì)于離散大規(guī)模寫入以及隨即讀取相對(duì)比較友好。
InfluxDB的Sharding策略是典型的兩層Sharding,上層使用Range Sharding,下層使用Hash Sharding。對(duì)于時(shí)序數(shù)據(jù)庫(kù)來(lái)說(shuō),基于時(shí)間的Range Sharding是最合理的考慮,但如果僅僅使用Time Range Sharding,會(huì)存在一個(gè)很嚴(yán)重的問(wèn)題,即寫入會(huì)存在熱點(diǎn),基于TimeRange Sharding的時(shí)序數(shù)據(jù)庫(kù)寫入必然會(huì)落到最新的Shard上,其他老Shard不會(huì)接收寫入請(qǐng)求。對(duì)寫入性能要求很高的時(shí)序數(shù)據(jù)庫(kù)來(lái)說(shuō),熱點(diǎn)寫入肯定不是最優(yōu)的方案。解決這個(gè)問(wèn)題最自然的思路就是再使用Hash進(jìn)行一次分區(qū),基于Key的Hash分區(qū)方案可以通過(guò)散列很好地解決熱點(diǎn)寫入的問(wèn)題。
Shard分區(qū)好了,就可以采用分布式集群架構(gòu)予以支撐,分?jǐn)倝毫Γ岣卟⑿卸取?/p>
成本和功能
很多時(shí)間序列數(shù)據(jù)都沒(méi)有多大用處,特別是當(dāng)系統(tǒng)長(zhǎng)時(shí)間正常運(yùn)行時(shí),完整的歷史數(shù)據(jù)意義并不大。而這些低價(jià)值數(shù)據(jù),占據(jù)大量高價(jià)值存儲(chǔ)空間,會(huì)讓企業(yè)“抓狂”。因此,一些共通的對(duì)時(shí)間序列數(shù)據(jù)分析的功能和操作:數(shù)據(jù)壓縮、數(shù)據(jù)保留策略、連續(xù)查詢、靈活的時(shí)間聚合等,都是為了解決時(shí)序數(shù)據(jù)庫(kù)的性價(jià)比問(wèn)題的。同時(shí),有些數(shù)據(jù)庫(kù)比如 RDDTool 和 Graphite 會(huì)自動(dòng)刪除高精度的數(shù)據(jù),只保留低精度的。而這些“功能”對(duì)關(guān)系型數(shù)據(jù)庫(kù)而言,簡(jiǎn)直是不可想象的。
還有一些成本很多人會(huì)忘記考慮,比如:License,用需要License的關(guān)系型數(shù)據(jù)庫(kù)來(lái)存儲(chǔ)時(shí)序數(shù)據(jù),成本根本沒(méi)法承受。
至此,我們得出的結(jié)論就一個(gè):選擇到底用什么數(shù)據(jù)庫(kù)來(lái)支持時(shí)序數(shù)據(jù),還是需要對(duì)時(shí)序數(shù)據(jù)的需求進(jìn)行透徹的分析,然后根據(jù)時(shí)序數(shù)據(jù)的特點(diǎn),來(lái)選擇適合的數(shù)據(jù)庫(kù)。
啟用名言作為本文結(jié)尾:適合的,就是最好的。
本文作者:格創(chuàng)東智首席架構(gòu)師王錦博士。格創(chuàng)東智是由智能產(chǎn)品制造及互聯(lián)網(wǎng)應(yīng)用服務(wù)領(lǐng)軍企業(yè)TCL孵化的創(chuàng)新型科技公司,致力于深度融合人工智能(AI)、大數(shù)據(jù)、云計(jì)算等前沿技術(shù)與制造行業(yè)經(jīng)驗(yàn),打造行業(yè)領(lǐng)先的“制造x”工業(yè)互聯(lián)網(wǎng)平臺(tái),同時(shí)為各類制造業(yè)企業(yè)提供優(yōu)質(zhì)、安全、高效的管理IT服務(wù),助力傳統(tǒng)制造業(yè)智能化轉(zhuǎn)型升級(jí)。(轉(zhuǎn)載請(qǐng)注明作者及來(lái)源)
-
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8884瀏覽量
137409 -
工業(yè)互聯(lián)網(wǎng)
+關(guān)注
關(guān)注
28文章
4320瀏覽量
94099
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
有云服務(wù)器還需要租用數(shù)據(jù)庫(kù)嗎?
科技云報(bào)到:大模型時(shí)代下,向量數(shù)據(jù)庫(kù)的野望
工業(yè)互聯(lián)網(wǎng)遠(yuǎn)程監(jiān)控平臺(tái)是什么
工業(yè)互聯(lián)網(wǎng)系統(tǒng)的組成
數(shù)字化時(shí)代的數(shù)據(jù)管理:多樣化數(shù)據(jù)庫(kù)選型指南
工業(yè)互聯(lián)網(wǎng)數(shù)據(jù)中臺(tái)是什么
工業(yè)互聯(lián)網(wǎng)平臺(tái)中什么是關(guān)鍵
工業(yè)互聯(lián)網(wǎng)三大體系是什么?
傳感器的工業(yè)互聯(lián)網(wǎng)時(shí)代
工業(yè)互聯(lián)網(wǎng)和ERP的關(guān)系
時(shí)序數(shù)據(jù)庫(kù)是什么?時(shí)序數(shù)據(jù)庫(kù)的特點(diǎn)
工業(yè)路由器:連接工業(yè)互聯(lián)網(wǎng)的工具
工業(yè)互聯(lián)網(wǎng)平臺(tái)是什么
工業(yè)互聯(lián)網(wǎng)實(shí)訓(xùn)是什么?工業(yè)互聯(lián)網(wǎng)實(shí)訓(xùn)包括哪些?
工業(yè)互聯(lián)網(wǎng)發(fā)展進(jìn)路:反思與建議





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論