

一、GBDT+LR簡介
協同過濾和矩陣分解存在的劣勢就是僅利用了用戶與物品相互行為信息進行推薦, 忽視了用戶自身特征, 物品自身特征以及上下文信息等,導致生成的結果往往會比較片面。而這次介紹的這個模型是2014年由Facebook提出的GBDT+LR模型, 該模型利用GBDT自動進行特征篩選和組合, 進而生成新的離散特征向量, 再把該特征向量當做LR模型的輸入, 來產生最后的預測結果, 該模型能夠綜合利用用戶、物品和上下文等多種不同的特征, 生成較為全面的推薦結果, 在CTR點擊率預估場景下使用較為廣泛。
下面首先會介紹邏輯回歸和GBDT模型各自的原理及優缺點, 然后介紹GBDT+LR模型的工作原理和細節。

二、邏輯回歸模型
邏輯回歸模型非常重要, 在推薦領域里面, 相比于傳統的協同過濾, 邏輯回歸模型能夠綜合利用用戶、物品、上下文等多種不同的特征生成較為“全面”的推薦結果, 關于邏輯回歸的更多細節, 可以參考下面給出的鏈接,這里只介紹比較重要的一些細節和在推薦中的應用。
邏輯回歸是在線性回歸的基礎上加了一個 Sigmoid 函數(非線形)映射,使得邏輯回歸成為了一個優秀的分類算法, 學習邏輯回歸模型, 首先應該記住一句話:邏輯回歸假設數據服從伯努利分布,通過極大化似然函數的方法,運用梯度下降來求解參數,來達到將數據二分類的目的。
相比于協同過濾和矩陣分解利用用戶的物品“相似度”進行推薦, 邏輯回歸模型將問題看成了一個分類問題, 通過預測正樣本的概率對物品進行排序。這里的正樣本可以是用戶“點擊”了某個商品或者“觀看”了某個視頻, 均是推薦系統希望用戶產生的“正反饋”行為, 因此邏輯回歸模型將推薦問題轉化成了一個點擊率預估問題。而點擊率預測就是一個典型的二分類, 正好適合邏輯回歸進行處理, 那么邏輯回歸是如何做推薦的呢?過程如下:
將用戶年齡、性別、物品屬性、物品描述、當前時間、當前地點等特征轉成數值型向量
確定邏輯回歸的優化目標,比如把點擊率預測轉換成二分類問題, 這樣就可以得到分類問題常用的損失作為目標, 訓練模型
在預測的時候, 將特征向量輸入模型產生預測, 得到用戶“點擊”物品的概率
利用點擊概率對候選物品排序, 得到推薦列表
推斷過程可以用下圖來表示:
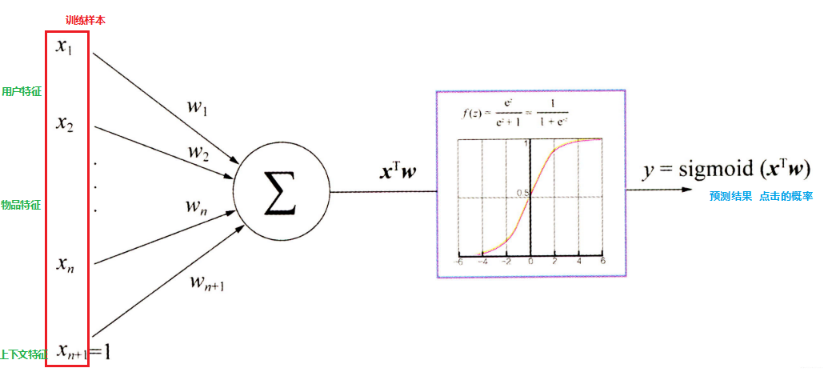
這里的關鍵就是每個特征的權重參數, 我們一般是使用梯度下降的方式, 首先會先隨機初始化參數, 然后將特征向量(也就是我們上面數值化出來的特征)輸入到模型, 就會通過計算得到模型的預測概率, 然后通過對目標函數求導得到每個的梯度, 然后進行更新
這里的目標函數長下面這樣:
求導之后的方式長這樣:
這樣通過若干次迭代, 就可以得到最終的了, 關于這些公式的推導,可以參考下面給出的文章鏈接, 下面我們分析一下邏輯回歸模型的優缺點。
優點:
LR模型形式簡單,可解釋性好,從特征的權重可以看到不同的特征對最后結果的影響。
訓練時便于并行化,在預測時只需要對特征進行線性加權,所以性能比較好,往往適合處理海量id類特征,用id類特征有一個很重要的好處,就是防止信息損失(相對于范化的 CTR 特征),對于頭部資源會有更細致的描述
資源占用小,尤其是內存。在實際的工程應用中只需要存儲權重比較大的特征及特征對應的權重。
方便輸出結果調整。邏輯回歸可以很方便的得到最后的分類結果,因為輸出的是每個樣本的概率分數,我們可以很容易的對這些概率分數進行cutoff,也就是劃分閾值(大于某個閾值的是一類,小于某個閾值的是一類)
當然, 邏輯回歸模型也有一定的局限性。
表達能力不強, 無法進行特征交叉, 特征篩選等一系列“高級“操作(這些工作都得人工來干, 這樣就需要一定的經驗, 否則會走一些彎路), 因此可能造成信息的損失
準確率并不是很高。因為這畢竟是一個線性模型加了個sigmoid, 形式非常的簡單(非常類似線性模型),很難去擬合數據的真實分布
處理非線性數據較麻煩。邏輯回歸在不引入其他方法的情況下,只能處理線性可分的數據, 如果想處理非線性, 首先對連續特征的處理需要先進行離散化(離散化的目的是為了引入非線性),如上文所說,人工分桶的方式會引入多種問題。
LR 需要進行人工特征組合,這就需要開發者有非常豐富的領域經驗,才能不走彎路。這樣的模型遷移起來比較困難,換一個領域又需要重新進行大量的特征工程。
所以如何自動發現有效的特征、特征組合,彌補人工經驗不足,縮短LR特征實驗周期,是亟需解決的問題, 而GBDT模型, 正好可以自動發現特征并進行有效組合。注:在Datawhale公眾號后臺回復【數據項目】可進項目專欄群,和作者等一起學習交流。
三、GBDT模型
GBDT全稱梯度提升決策樹,在傳統機器學習算法里面是對真實分布擬合的最好的幾種算法之一,在前幾年深度學習還沒有大行其道之前,gbdt在各種競賽是大放異彩。原因大概有幾個,一是效果確實挺不錯。二是即可以用于分類也可以用于回歸。三是可以篩選特征, 所以這個模型依然是一個非常重要的模型。
GBDT是通過采用加法模型(即基函數的線性組合),以及不斷減小訓練過程產生的誤差來達到將數據分類或者回歸的算法, 其訓練過程如下:
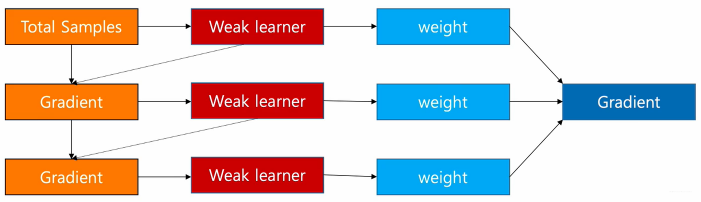
gbdt通過多輪迭代, 每輪迭代會產生一個弱分類器, 每個分類器在上一輪分類器的殘差基礎上進行訓練。gbdt對弱分類器的要求一般是足夠簡單, 并且低方差高偏差。因為訓練的過程是通過降低偏差來不斷提高最終分類器的精度。由于上述高偏差和簡單的要求,每個分類回歸樹的深度不會很深。最終的總分類器是將每輪訓練得到的弱分類器加權求和得到的(也就是加法模型)。
關于GBDT的詳細細節,依然是可以參考下面給出的鏈接。這里想分析一下GBDT如何來進行二分類的,因為我們要明確一點就是gbdt 每輪的訓練是在上一輪的訓練的殘差基礎之上進行訓練的, 而這里的殘差指的就是當前模型的負梯度值, 這個就要求每輪迭代的時候,弱分類器的輸出的結果相減是有意義的, 而gbdt 無論用于分類還是回歸一直都是使用的CART 回歸樹, 那么既然是回歸樹, 是如何進行二分類問題的呢?
GBDT 來解決二分類問題和解決回歸問題的本質是一樣的,都是通過不斷構建決策樹的方式,使預測結果一步步的接近目標值, 但是二分類問題和回歸問題的損失函數是不同的, 關于GBDT在回歸問題上的樹的生成過程, 損失函數和迭代原理可以參考給出的鏈接, 回歸問題中一般使用的是平方損失, 而二分類問題中, GBDT和邏輯回歸一樣, 使用的下面這個:
其中,是第個樣本的觀測值, 取值要么是0要么是1, 而是第個樣本的預測值, 取值是0-1之間的概率,由于我們知道GBDT擬合的殘差是當前模型的負梯度, 那么我們就需要求出這個模型的導數, 即, 對于某個特定的樣本, 求導的話就可以只考慮它本身, 去掉加和號, 那么就變成了, 其中如下:
如果對邏輯回歸非常熟悉的話, 一定不會陌生吧, 這就是對幾率比取了個對數, 并且在邏輯回歸里面這個式子會等于, 所以才推出了的那個形式。這里令, 即, 則上面這個式子變成了:
這時候,我們對求導, 得
這樣, 我們就得到了某個訓練樣本在當前模型的梯度值了, 那么殘差就是。GBDT二分類的這個思想,其實和邏輯回歸的思想一樣,邏輯回歸是用一個線性模型去擬合這個事件的對數幾率, GBDT二分類也是如此, 用一系列的梯度提升樹去擬合這個對數幾率, 其分類模型可以表達為:
下面我們具體來看GBDT的生成過程, 構建分類GBDT的步驟有兩個:
1. 初始化GBDT
和回歸問題一樣, 分類 GBDT 的初始狀態也只有一個葉子節點,該節點為所有樣本的初始預測值,如下:
上式里面,代表GBDT模型,是模型的初識狀態, 該式子的意思是找到一個,使所有樣本的 Loss 最小,在這里及下文中,都表示節點的輸出,即葉子節點, 且它是一個形式的值(回歸值),在初始狀態,。
下面看例子(該例子來自下面的第二個鏈接), 假設我們有下面3條樣本:
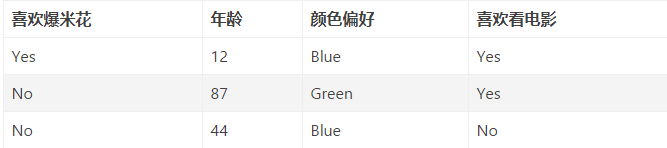
我們希望構建 GBDT 分類樹,它能通過「喜歡爆米花」、「年齡」和「顏色偏好」這 3 個特征來預測某一個樣本是否喜歡看電影。我們把數據代入上面的公式中求Loss: 為了令其最小, 我們求導, 且讓導數為0, 則:
于是, 就得到了初始值, 模型的初識狀態
2. 循環生成決策樹
這里回憶一下回歸樹的生成步驟, 其實有4小步, 第一就是計算負梯度值得到殘差, 第二步是用回歸樹擬合殘差, 第三步是計算葉子節點的輸出值, 第四步是更新模型。下面我們一一來看:
計算負梯度得到殘差:
此處使用棵樹的模型, 計算每個樣本的殘差, 就是上面的, 于是例子中, 每個樣本的殘差:
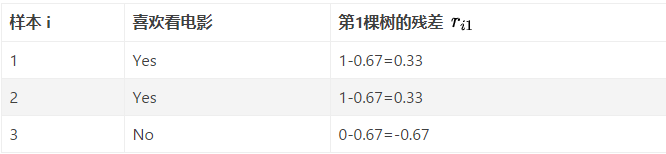
使用回歸樹來擬合, 這里的表示樣本哈,回歸樹的建立過程可以參考下面的鏈接文章,簡單的說就是遍歷每個特征, 每個特征下遍歷每個取值, 計算分裂后兩組數據的平方損失, 找到最小的那個劃分節點。假如我們產生的第2棵決策樹如下:
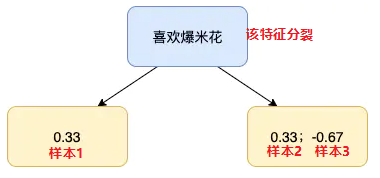
對于每個葉子節點, 計算最佳殘差擬合值
意思是, 在剛構建的樹中, 找到每個節點的輸出, 能使得該節點的loss最小。那么我們看一下這個的求解方式, 這里非常的巧妙。首先, 我們把損失函數寫出來, 對于左邊的第一個樣本, 有
這個式子就是上面推導的, 因為我們要用回歸樹做分類, 所以這里把分類的預測概率轉換成了對數幾率回歸的形式, 即, 這個就是模型的回歸輸出值。而如果求這個損失的最小值, 我們要求導, 解出令損失最小的。但是上面這個式子求導會很麻煩, 所以這里介紹了一個技巧就是使用二階泰勒公式來近似表示該式, 再求導, 還記得偉大的泰勒嗎?
這里就相當于把當做常量,作為變量, 將二階展開:
這時候再求導就簡單了
Loss最小的時候, 上面的式子等于0, 就可以得到:
因為分子就是殘差(上述已經求到了), 分母可以通過對殘差求導,得到原損失函數的二階導:
這時候, 就可以算出該節點的輸出:
這里的下面表示第棵樹的第個葉子節點。接下來是右邊節點的輸出, 包含樣本2和樣本3, 同樣使用二階泰勒公式展開:
求導, 令其結果為0,就會得到, 第1棵樹的第2個葉子節點的輸出:
可以看出, 對于任意葉子節點, 我們可以直接計算其輸出值:
最后,更新模型:
這樣, 通過多次循環迭代, 就可以得到一個比較強的學習器。
下面分析一下GBDT的優缺點:
我們可以把樹的生成過程理解成自動進行多維度的特征組合的過程,從根結點到葉子節點上的整個路徑(多個特征值判斷),才能最終決定一棵樹的預測值, 另外,對于連續型特征的處理,GBDT 可以拆分出一個臨界閾值,比如大于 0.027 走左子樹,小于等于 0.027(或者 default 值)走右子樹,這樣很好的規避了人工離散化的問題。這樣就非常輕松的解決了邏輯回歸那里自動發現特征并進行有效組合的問題, 這也是GBDT的優勢所在。
但是GBDT也會有一些局限性, 對于海量的 id 類特征,GBDT 由于樹的深度和棵樹限制(防止過擬合),不能有效的存儲;另外海量特征在也會存在性能瓶頸,當 GBDT 的 one hot 特征大于 10 萬維時,就必須做分布式的訓練才能保證不爆內存。所以 GBDT 通常配合少量的反饋 CTR 特征來表達,這樣雖然具有一定的范化能力,但是同時會有信息損失,對于頭部資源不能有效的表達。
所以, 我們發現其實GBDT和LR的優缺點可以進行互補。
四、GBDT+LR模型
2014年, Facebook提出了一種利用GBDT自動進行特征篩選和組合, 進而生成新的離散特征向量, 再把該特征向量當做LR模型的輸入, 來產生最后的預測結果, 這就是著名的GBDT+LR模型了。GBDT+LR 使用最廣泛的場景是CTR點擊率預估,即預測當給用戶推送的廣告會不會被用戶點擊。
有了上面的鋪墊, 這個模型解釋起來就比較容易了, 模型的總體結構長下面這樣:
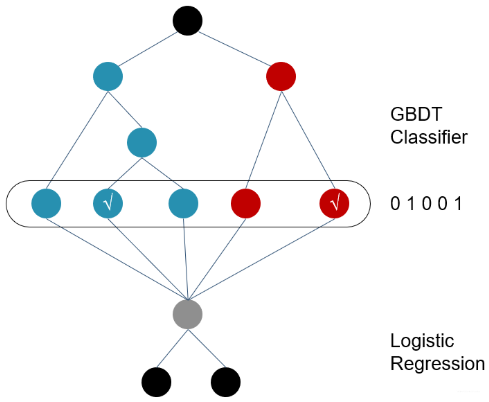
訓練時,GBDT 建樹的過程相當于自動進行的特征組合和離散化,然后從根結點到葉子節點的這條路徑就可以看成是不同特征進行的特征組合,用葉子節點可以唯一的表示這條路徑,并作為一個離散特征傳入 LR 進行二次訓練。
比如上圖中, 有兩棵樹,x為一條輸入樣本,遍歷兩棵樹后,x樣本分別落到兩顆樹的葉子節點上,每個葉子節點對應LR一維特征,那么通過遍歷樹,就得到了該樣本對應的所有LR特征。構造的新特征向量是取值0/1的。比如左樹有三個葉子節點,右樹有兩個葉子節點,最終的特征即為五維的向量。對于輸入x,假設他落在左樹第二個節點,編碼[0,1,0],落在右樹第二個節點則編碼[0,1],所以整體的編碼為[0,1,0,0,1],這類編碼作為特征,輸入到線性分類模型(LR or FM)中進行分類。
預測時,會先走 GBDT 的每棵樹,得到某個葉子節點對應的一個離散特征(即一組特征組合),然后把該特征以 one-hot 形式傳入 LR 進行線性加權預測。
這個方案應該比較簡單了, 下面有幾個關鍵的點我們需要了解:
通過GBDT進行特征組合之后得到的離散向量是和訓練數據的原特征一塊作為邏輯回歸的輸入, 而不僅僅全是這種離散特征
建樹的時候用ensemble建樹的原因就是一棵樹的表達能力很弱,不足以表達多個有區分性的特征組合,多棵樹的表達能力更強一些。GBDT每棵樹都在學習前面棵樹尚存的不足,迭代多少次就會生成多少棵樹。
RF也是多棵樹,但從效果上有實踐證明不如GBDT。且GBDT前面的樹,特征分裂主要體現對多數樣本有區分度的特征;后面的樹,主要體現的是經過前N顆樹,殘差仍然較大的少數樣本。優先選用在整體上有區分度的特征,再選用針對少數樣本有區分度的特征,思路更加合理,這應該也是用GBDT的原因。
在CRT預估中, GBDT一般會建立兩類樹(非ID特征建一類, ID類特征建一類), AD,ID類特征在CTR預估中是非常重要的特征,直接將AD,ID作為feature進行建樹不可行,故考慮為每個AD,ID建GBDT樹。
非ID類樹:不以細粒度的ID建樹,此類樹作為base,即便曝光少的廣告、廣告主,仍可以通過此類樹得到有區分性的特征、特征組合
ID類樹:以細粒度 的ID建一類樹,用于發現曝光充分的ID對應有區分性的特征、特征組合。
五、編程實踐
下面我們通過kaggle上的一個ctr預測的比賽來看一下GBDT+LR模型部分的編程實踐, 數據來源:https://github.com/zhongqiangwu960812/AI-RecommenderSystem/tree/master/GBDT%2BLR/data
我們回顧一下上面的模型架構, 首先是要訓練GBDT模型, GBDT的實現一般可以使用xgboost, 或者lightgbm。訓練完了GBDT模型之后, 我們需要預測出每個樣本落在了哪棵樹上的哪個節點上, 然后通過one-hot就會得到一些新的離散特征, 這和原來的特征進行合并組成新的數據集, 然后作為邏輯回歸的輸入,最后通過邏輯回歸模型得到結果。
根據上面的步驟, 我們看看代碼如何實現:
假設我們已經有了處理好的數據x_train, y_train。
1. 訓練GBDT模型
GBDT模型的搭建我們可以通過XGBOOST, lightgbm等進行構建。比如:


2. 特征轉換并構建新的數據集
通過上面我們建立好了一個gbdt模型, 我們接下來要用它來預測出樣本會落在每棵樹的哪個葉子節點上, 為后面的離散特征構建做準備, 由于不是用gbdt預測結果而是預測訓練數據在每棵樹上的具體位置, 就需要用到下面的語句:


3. 離散特征的獨熱編碼,并劃分數據集

4. 訓練邏輯回歸模型作最后的預測

上面我們就完成了GBDT+LR模型的基本訓練步驟, 具體詳細的代碼可以參考鏈接。
六、課后思考
為什么使用集成的決策樹?為什么使用GBDT構建決策樹而不是隨機森林?
面對高維稀疏類特征的時候(比如ID類特征), 邏輯回歸一般要比GBDT這種非線性模型好, 為什么?
參考資料
王喆 - 《深度學習推薦系統》
決策樹之 GBDT 算法 - 分類部分
深入理解GBDT二分類算法
邏輯回歸、優化算法和正則化的幕后細節補充
梯度提升樹GBDT的理論學習與細節補充
推薦系統遇上深度學習(十)--GBDT+LR融合方案實戰
CTR預估中GBDT與LR融合方案
GBDT+LR算法解析及Python實現
常見計算廣告點擊率預估算法總結
GBDT--分類篇
論文
http://quinonero.net/Publications/predicting-clicks-facebook.pdf
Predicting Clicks: Estimating the Click-Through Rate for New Ads
Greedy Fun tion Approximation : A Gradient Boosting
責任編輯:xj
原文標題:邏輯回歸 + GBDT模型融合實戰!
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
LR
+關注
關注
1文章
8瀏覽量
10144 -
GBDT
+關注
關注
0文章
13瀏覽量
4017
原文標題:邏輯回歸 + GBDT模型融合實戰!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監

評論