 語義分割方法發展過程
語義分割方法發展過程
語義分割
目的:給定一張圖像,我們要對這張圖像上的每個pixel逐一進行分類,結果展示如下圖:
上圖中的實例分割是語義分割的延伸,要區別出相同類別的不同個體。
應用場景:無人駕駛、輔助醫療等。
語義分割方法發展過程:
1.灰度分割(Gray Level Segmentation)
語義分割的最簡單形式是對一個區域設定必須滿足的硬編碼規則或屬性,進而指定特定類別標簽. 編碼規則可以根據像素的屬性來構建,如灰度級強度(gray level intensity). 基于該技術的一種分割方法是 Split and Merge 算法. 該算法是通過遞歸地將圖像分割為子區域,直到可以分配標簽;然后再合并具有相同標簽的相鄰子區域。
這種方法的問題是規則必須是硬編碼的. 而且,僅使用灰度級信息是很難表示比如人類等復雜類別的. 因此,需要特征提取和優化技術來正確地學習復雜類別的特征表示。
2.條件隨機場(Conditional Random Fields)
CRFs 是一類用于結構化預測的統計建模方法. 不同于分類算法,CRFs 在進行預測前,會考慮像素的鄰近信息(neighboring context),如像素間的關系. 這使得 CRFs 成為語義分割的理想候選者. 這里介紹下 CRFs 在語義分割中的應用.
圖像中的每個像素都是與有限的可能狀態集相關. 在語義分割中,target 類別標簽就是可能狀態集. 將一個狀態(或,label u) 分配給的單個像素 x 的成本(cost) 被稱為一元成本(unary cost). 為了對像素間的關系進行建模, 還進一步考慮將一對標簽(labels (u, v)) 分配給一對像素 (x, y),其被成為成對成本(pairwise cost). 可以采用直接相鄰的像素對作為像素對(Grid CRF);也可以采用圖像中所有的像素構建像素對(Denser CRF)。
圖像中所有 unary cost 和 pairwise cost 的相加和作為 CRF 的能量函數(或損失函數,loss). 求解最小化即可得到較好的分割輸出。
深度學習極大地簡化了語義分割的流程(pipeline),并得到了較高質量的分割結果
3.FCN
FCN方法的提出成功的將深度學習方法成功的引入到了語義分割領域,由于要預測的圖像是一個二維的表示,因此提出了全卷積網絡用來抽取圖像中的特征,將得到的高級語義特征上采樣到指定的維度,從而得到了最終的預測結果,從而自然的形成了Encoder-Decoder框架,這也成為了語義分割領域中通用框架之一。
具體的模型圖如下:
由于在Encoder中獲取到圖像的高級語義,但是其并不是最終分割的結果,因此作者采用轉置卷積的方法將該高級特征上采樣到指定的維度,從而得到最終的分割結果。由于直接上采樣之后的結果并不好,因此在改論文中引入了跳躍模型就是將不同卷積層下獲取到的特征相融合,從而改善模型的效果,其具體結構如下所示:
4.U-NET, SegNet 等
為了改善FCN中的弊端,隨后提出了很多模型最經典的是U-Net,SegNet,但是他們的本質上并沒有改變Encoder-Decoder模型的架構。
5.DeepLab系列
DeepLab的出現帶來了一個新的方法就是擴展卷積(空洞卷積)方法,卷積層引入了一個稱為 “擴張率(dilation rate)”的新參數,該參數定義了卷積核處理數據時各值的間距。其目的是為了擴大模型的感受野,使其能夠感受到更大范圍下的特征信息。具體的體現如下所示:
擴展卷積方法的提出讓人們可以去除Encoder-Decoder框架的限制。隨后deeplab算法的改進也提出了例如多尺度學習的通則紅描述方法(ASPP等)
6.NOW
面對監督式方法---最近的方法大家更注重于實時的語義分割任務,也就是輕量級的語義分割網絡的設計。當然還有一些其他的方法,例如針對不同的領域設計不同的語義分割網絡、改進上采樣方法等。
面對弱監督方法---目前出現了很多弱監督方法,就是通過學習圖像分類的數據集(image-level tag)中的信息,來完成語義分割這種密度預測的任務。當然還有使用框架注釋來標注數據(bounding-boxes tag)的。
語義分割領域中困難的地方:
1、數據問題:分割不像檢測等任務,只需要標注一個類別就可以拿來使用,分割需要精確的像素級標注,包括每一個目標的輪廓等信息,因此使得制作數據集成本過高;
2、計算資源問題:現在想要得到較高的精度的語義分割模型就需要使用類似于ResNet101等深網絡。同時,分割預測了每一個像素,這就要求feature map的分辨率盡可能的高,這都說明了計算資源的問題,雖然也有一些輕量級的網絡,但精度還是太低了;
3、精細分割:目前的方法中對于圖像中的大體積的東西能夠很好的分類,但是對于細小的類別,由于其輪廓太小,從而無法精確的定位輪廓,造成精度較低;
4、上下文信息:分割中上下文信息很重要,否則會造成一個目標被分成多個part,或者不同類別目標分類成相同類別;
評價指標:
1、執行時間:速度或運行時間是一個非常有價值的度量,因為大多數系統需要保證推理時間可以滿足硬實時的需求。然而在通常的實驗中其影響是很不明顯的,并且該指標非常依賴硬件設備及后臺實現,致使一些比較是無用的。
2、內存占用:在運行時間相同的情況下,記錄系統運行狀態下內存占用的極值和均值是及其有價值的。
3、精確度:這里指的是逐像素標記的精度測量,假設共有k個類(從l0到lk其中有一個類別是屬于背景的。),Pij表示本屬于i類但是被預測為j類的像素個數,Pii表示為真正分對類的數量,而Pij與Pji分別被稱為假正樣本和假負樣本。
1)Pixel Accuracy(PA,像素精度):標記正確的像素占總像素的比例
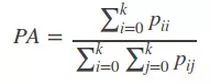
2)Mean Pixel Accuracy(MPA,平均像素精度):計算每個類內被正確分類像素數比例,之后求所有類的平均數。
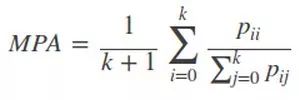
3)Mean Intersection over Union(MIoU,均交并比):為語義分割的標準度量,其計算兩個集合的交集和并集之比,這兩個集合分別為ground truth 與predicted segmentation,在每個類上計算IoU,之后將其求平均。
-----IoU即真正樣本數量/(真正樣本數量+假正樣本數量+假負樣本數量)
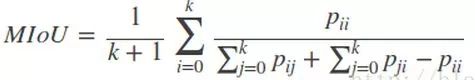
4)Frequency weighted Intersection over Union(FWIoU,頻權交并):是MIoU的一種提升,這種方法根據每個類出現的頻率為期設置權重。
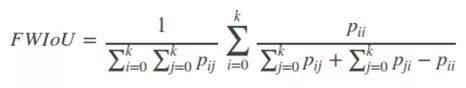
責任編輯:lq
-
圖像
+關注
關注
2文章
1083瀏覽量
40449 -
函數
+關注
關注
3文章
4327瀏覽量
62573 -
分割
+關注
關注
0文章
17瀏覽量
11895
原文標題:語義分割入門的總結
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
利用VLM和MLLMs實現SLAM語義增強

語義分割25種損失函數綜述和展望

圖像語義分割的實用性是什么
圖像分割和語義分割的區別與聯系
圖像分割與目標檢測的區別是什么
機器學習中的數據分割方法
圖像分割與語義分割中的CNN模型綜述
機器人視覺技術中常見的圖像分割方法
人工智能的定義和發展過程
陶瓷電熔爐啟動過程中升溫停止問題的原因及解決辦法分析
助力移動機器人下游任務!Mobile-Seed用于聯合語義分割和邊界檢測


改進棉花根系圖像分割方法
PCB信號跨分割線需要怎么處理?





 工商網監
工商網監
評論