") 提高數(shù)據(jù)分析的科學(xué)性與透明度,用統(tǒng)計(jì)學(xué)“反轉(zhuǎn)”中心法則
提高數(shù)據(jù)分析的科學(xué)性與透明度,用統(tǒng)計(jì)學(xué)“反轉(zhuǎn)”中心法則
“對(duì)我而言,回答了自己心中的問(wèn)題或者做出一個(gè)新的發(fā)現(xiàn),這種成就感要遠(yuǎn)高于生活中的其他快樂(lè)。”李婧翌對(duì)《麻省理工科技評(píng)論》中國(guó)這樣說(shuō)道。
而她的研究?jī)?nèi)容在很多人眼里或許稍顯枯燥:針對(duì)前沿的生物學(xué)問(wèn)題開發(fā)新的統(tǒng)計(jì)學(xué)方法,尤其著重于對(duì)大規(guī)模基因組和轉(zhuǎn)錄組數(shù)據(jù)進(jìn)行分析方法的開發(fā)。
由于高通量實(shí)驗(yàn)技術(shù)的發(fā)展,生命科學(xué)從一個(gè)靠觀察實(shí)驗(yàn)為主的學(xué)科逐漸變得更加需要定量化,而這些大規(guī)模數(shù)據(jù)的產(chǎn)生也需要算法才能夠進(jìn)行分析,從而總結(jié)出數(shù)學(xué)規(guī)律并用規(guī)律來(lái)刻畫事物的本質(zhì)。
加州大學(xué)洛杉磯分校(UCLA)統(tǒng)計(jì)系(已獲得終身教職)副教授和博士生導(dǎo)師,生物統(tǒng)計(jì)系、人類遺傳學(xué)系和計(jì)算醫(yī)學(xué)系博士生導(dǎo)師李婧翌認(rèn)為,生命科學(xué)作為一個(gè)“宏科學(xué)”,盡管問(wèn)題的本質(zhì)與生命強(qiáng)相關(guān),但研究手段需要各個(gè)學(xué)科一起合作,計(jì)算則是其中非常重要的一部分,大數(shù)據(jù)也需要有非常適合的挖掘工具,這對(duì)于從小對(duì)數(shù)學(xué)與科學(xué)有強(qiáng)烈興趣、并在本科與博士階段分別接受了生命科學(xué)與生物統(tǒng)計(jì)學(xué)系統(tǒng)教育的李婧翌有強(qiáng)大的吸引。
李婧翌的研究專注于統(tǒng)計(jì)學(xué)與生命科學(xué)的交叉問(wèn)題,她首創(chuàng)性地使用嚴(yán)格的統(tǒng)計(jì)學(xué)來(lái)分析已發(fā)表的轉(zhuǎn)錄組學(xué)和蛋白組學(xué)數(shù)據(jù),發(fā)現(xiàn)在過(guò)往研究中,由于研究人員對(duì)測(cè)量誤差的忽略,轉(zhuǎn)錄的重要性被嚴(yán)重低估,該分析挑戰(zhàn)了“翻譯比轉(zhuǎn)錄重要”的觀點(diǎn)卻支持了之前大量在 mRNA 轉(zhuǎn)錄水平的科學(xué)發(fā)現(xiàn)。因其重要性,李婧翌的研究結(jié)果被發(fā)表在 Science 雜志并收錄于本科教材 Molecular Cell Biology 中。
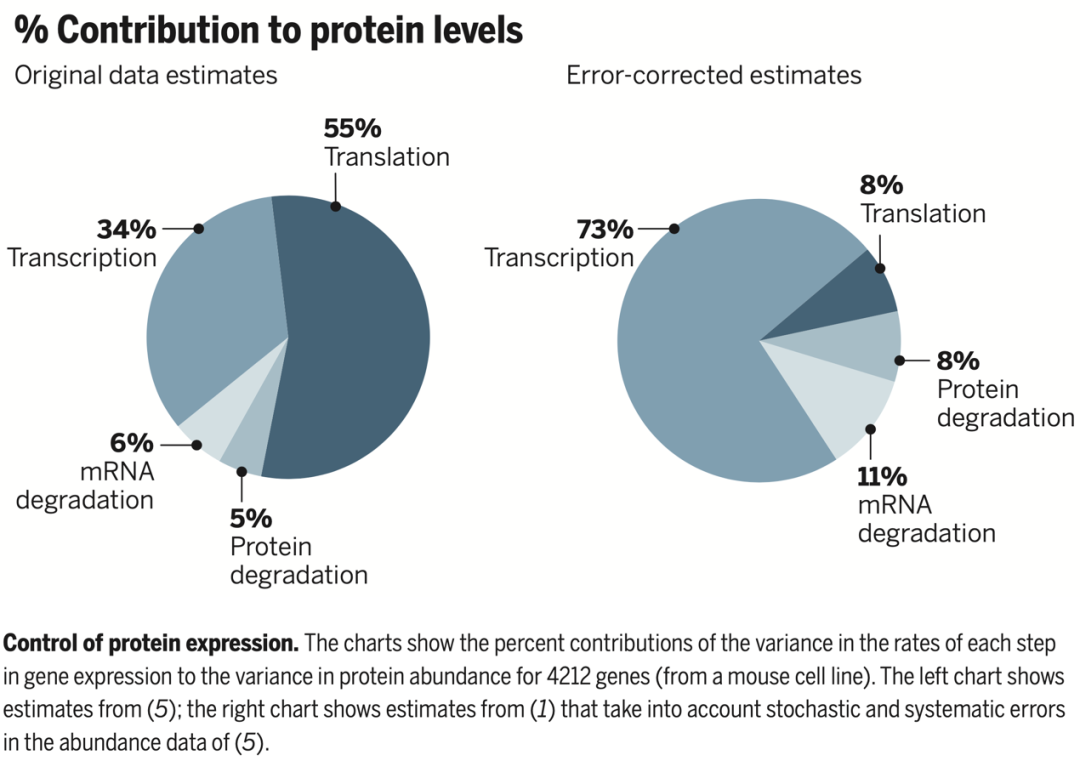
圖 | 左圖是論文 B.Schwanh?usseretal.,Nature473,337(2011) 中在不考慮實(shí)驗(yàn)數(shù)據(jù)誤差的情況下對(duì)轉(zhuǎn)錄、翻譯、mRNA 降解和蛋白質(zhì)降解這四個(gè)步驟對(duì)于蛋白質(zhì)含量的貢獻(xiàn)的估計(jì);右圖是在校正了實(shí)驗(yàn)數(shù)據(jù)誤差之后的估計(jì)。(來(lái)源:李婧翌的論文 Li et al. (2015). Statistics requantitates the central dogma. Science347(6226):1066-1067.)
此外,李婧翌團(tuán)隊(duì)還開發(fā)了大量生物信息學(xué)工具在組織和單細(xì)胞水平上對(duì) mRNA 分子進(jìn)行全系統(tǒng)測(cè)量,并正在開發(fā)一項(xiàng)能夠?qū)ふ业饺巳簛喰椭泻图膊∠嚓P(guān)的基因變異的新的統(tǒng)計(jì)度量。
憑借上述優(yōu)異的研究成果,李婧翌成功入選 《麻省理工科技評(píng)論》“35 歲以下科技創(chuàng)新 35 人”(Innovators Under 35)2020 年中國(guó)區(qū)榜單。
圖 |《麻省理工科技評(píng)論》“35 歲以下科技創(chuàng)新 35 人”2020 年中國(guó)區(qū)榜單入選者李婧翌
無(wú)心插柳,卻顛覆固有認(rèn)知
早在 1958 年,中心轉(zhuǎn)錄法則便被提出,它指的是遺傳信息被編碼在 DNA 中,通過(guò)轉(zhuǎn)錄會(huì)變成 mRNA,再通過(guò)翻譯的過(guò)程變成蛋白質(zhì),這是所有有細(xì)胞結(jié)構(gòu)的生物所遵循的法則。 在這個(gè)過(guò)程中,除了轉(zhuǎn)錄和翻譯生成了 mRNA 和蛋白質(zhì)這兩個(gè)步驟,還存在 mRNA 和蛋白質(zhì)的降解,這四個(gè)步驟共同決定了每一個(gè)基因所對(duì)應(yīng)的蛋白質(zhì)到底在我們細(xì)胞中存在多少量。不過(guò),此前中心轉(zhuǎn)錄法則是一個(gè)定性表述,“沒有人知道每一步的速率是多少,也沒有人知道對(duì)最后蛋白質(zhì)含量的影響有多少。” 在李婧翌博士即將畢業(yè)之時(shí),她與合作者 Mark Biggin 博士共同研究中心轉(zhuǎn)錄法則的定量工作。偶然的一次機(jī)會(huì),李婧翌和合作者發(fā)現(xiàn),2011 年發(fā)表在Nature上的一篇文章首次在小鼠的全基因組的基因中進(jìn)行了 4 項(xiàng)步驟的測(cè)量,其得出的結(jié)論是每個(gè)基因的 mRNA 的含量對(duì)于蛋白質(zhì)含量的預(yù)測(cè)效果比較差,也就是說(shuō)一個(gè)基因內(nèi) mRNA 的高或低并不太能代表它的蛋白質(zhì)含量的高或低。 “這在當(dāng)時(shí)是個(gè)非常讓人震驚的結(jié)論。因?yàn)槲覀冇泻芏鄬?shí)驗(yàn)手段可以用來(lái)研究 mRNA,但是研究蛋白質(zhì)相對(duì)困難很多,所以大量生物學(xué)的發(fā)現(xiàn)成果都圍繞 mRNA 的含量水平。如果這篇文章的結(jié)果為真,那么之前很多 mRNA 的結(jié)果可能都沒有什么意義了。”李婧翌解釋道。 當(dāng)李婧翌與合作伙伴看到這篇文章時(shí),他們觀察到這項(xiàng)工作是將高通量質(zhì)譜轉(zhuǎn)化為蛋白質(zhì)含量,但在轉(zhuǎn)化過(guò)程中,它的標(biāo)準(zhǔn)實(shí)際上只基于高表達(dá)蛋白,并假設(shè)同樣的轉(zhuǎn)換方式也適用于低表達(dá)蛋白,由此導(dǎo)致了研究里面很多低表達(dá)蛋白的表達(dá)指征是很不準(zhǔn)的,也就意味著高通量蛋白質(zhì)測(cè)量很有可能存在誤差。 為了解決這一疑惑,李婧翌將實(shí)驗(yàn)誤差考慮進(jìn)建模后發(fā)現(xiàn),實(shí)際上 mRNA 和蛋白質(zhì)含量的相關(guān)性比 Nature 的文章報(bào)道的要高很多,轉(zhuǎn)錄的重要性被嚴(yán)重低估。這項(xiàng)“無(wú)心插柳”的研究結(jié)果被發(fā)表在 Science 雜志并收錄于本科教材 Molecular Cell Biology 中。 李婧翌對(duì)《麻省理工科技評(píng)論》中國(guó)回憶道:“我覺得很有趣的一點(diǎn)是,我們將很基本的統(tǒng)計(jì)方法用到了正確的問(wèn)題上,從而發(fā)現(xiàn)了非常意想不到的結(jié)果。這也說(shuō)明了考慮數(shù)據(jù)測(cè)量的隨機(jī)性和數(shù)據(jù)噪音對(duì)科學(xué)結(jié)論十分重要。”這一年,李婧翌還不到 30 歲。科研與教育同樣重要 作為一個(gè)青年科學(xué)家,李婧翌認(rèn)為,保持對(duì)未知問(wèn)題的好奇心,用研究拓寬人類的知識(shí)邊界,是支撐她科研工作的重要推動(dòng)力。 作為一個(gè)科研人員,李婧翌認(rèn)為目前的統(tǒng)計(jì)分析還遠(yuǎn)遠(yuǎn)談不上科學(xué),“如果一個(gè)分析人員在寫研究報(bào)告時(shí)沒有記錄分析的每一步,而只是簡(jiǎn)略地記錄一個(gè)結(jié)果,那最終結(jié)果就不太透明,并且可能也不能被重復(fù),可信度就要大打折扣。” 此外,李婧翌提到,如果要將最新研究的統(tǒng)計(jì)學(xué)方法發(fā)表在比較好的學(xué)術(shù)雜志上,通常情況下做的越復(fù)雜越容易發(fā)表,這就導(dǎo)致統(tǒng)計(jì)學(xué)領(lǐng)域出現(xiàn)一個(gè)通病:很多統(tǒng)計(jì)方法都比較像“黑箱”,它們過(guò)于復(fù)雜,也沒有給實(shí)際應(yīng)用的人員講授清楚優(yōu)缺點(diǎn)到底在哪里。
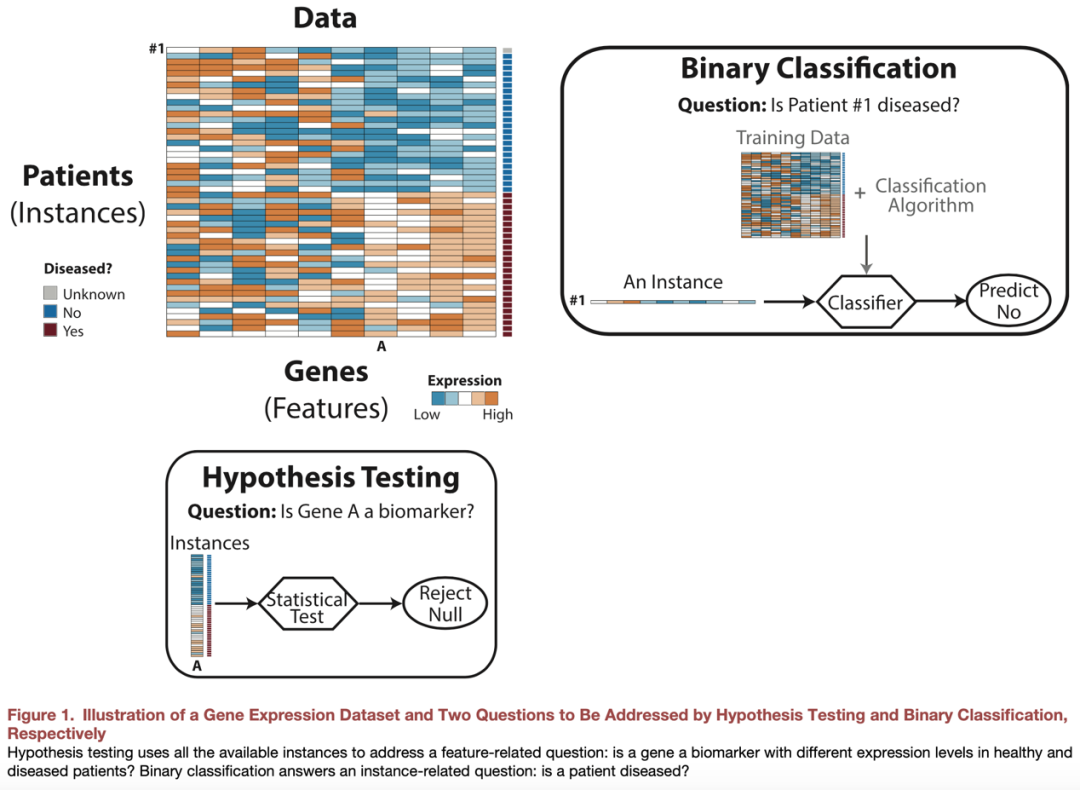
圖 | 對(duì)于同樣的一套多個(gè)病人樣本中的基因表達(dá)數(shù)據(jù),病人是觀測(cè)值,而基因是特征。大部分的病人已知得病或未得病。如果研究問(wèn)題是:基因A是否為一個(gè)有效的疾病標(biāo)志物,那么假設(shè)檢驗(yàn)是合適的統(tǒng)計(jì)方法。而如果研究問(wèn)題是:1號(hào)病人是否得病,那么二元分類是合適的統(tǒng)計(jì)方法。(來(lái)源:李婧翌的論文Li et al. (2020). Statistical hypothesis testing versus machine-learning binary classification: distinctions and guidelines. Patterns 1(7):110115.)
作為一個(gè)有交叉學(xué)科背景的研究人員,李婧翌充分利用了這一點(diǎn):能夠更好地讓生命科學(xué)領(lǐng)域的數(shù)據(jù)分析人員去理解現(xiàn)有的一些經(jīng)典方法的優(yōu)缺點(diǎn)和適用范圍,同時(shí),李婧翌自己發(fā)展新方法也將以此為目標(biāo),創(chuàng)造出更透明、更穩(wěn)定的統(tǒng)計(jì)學(xué)方法。舉例而言,李婧翌在最近發(fā)表的一篇文章中就嘗試對(duì)兩種常用但經(jīng)常被混淆的統(tǒng)計(jì)方法:假設(shè)檢驗(yàn)和二元分類,進(jìn)行解釋并闡述這兩種方法各自適用的數(shù)據(jù)分析問(wèn)題。譬如對(duì)致癌基因和抑癌基因的預(yù)測(cè)問(wèn)題,李婧翌解釋了為什么基于現(xiàn)有的大數(shù)據(jù),二元分類是一個(gè)更加適用的統(tǒng)計(jì)方法。 作為教師,李婧翌致力于將統(tǒng)計(jì)方法開發(fā)和實(shí)際應(yīng)用的重要性更緊密的結(jié)合。 李婧翌認(rèn)為,無(wú)論中美,目前統(tǒng)計(jì)學(xué)的基礎(chǔ)教育中都有很多過(guò)時(shí)的教學(xué)內(nèi)容,因?yàn)楹芏嘤?jì)算都已經(jīng)可以依靠計(jì)算機(jī)的程序包來(lái)進(jìn)行自動(dòng)化運(yùn)算。統(tǒng)計(jì)學(xué)教育更重要的應(yīng)該是去教授學(xué)生為什么需要統(tǒng)計(jì)學(xué),數(shù)據(jù)背后的隨機(jī)性應(yīng)該怎么去理解,以及數(shù)據(jù)分析到底想解決什么問(wèn)題,“我覺得這些其實(shí)是統(tǒng)計(jì)教育需要改變的的東西,我希望我能夠發(fā)揮一些作用。”
責(zé)任編輯:lq
-
自動(dòng)化
+關(guān)注
關(guān)注
29文章
5596瀏覽量
79407 -
統(tǒng)計(jì)
+關(guān)注
關(guān)注
1文章
19瀏覽量
13517 -
數(shù)據(jù)分析
+關(guān)注
關(guān)注
2文章
1452瀏覽量
34077
原文標(biāo)題:提高數(shù)據(jù)分析的科學(xué)性與透明度,UCLA教授用統(tǒng)計(jì)學(xué)“反轉(zhuǎn)”中心法則
文章出處:【微信號(hào):deeptechchina,微信公眾號(hào):deeptechchina】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Mathematica 在數(shù)據(jù)分析中的應(yīng)用
首個(gè)科學(xué)計(jì)算基座大模型BBT-Neutron開源,助力突破大科學(xué)裝置數(shù)據(jù)分析瓶頸
數(shù)據(jù)可視化與數(shù)據(jù)分析的關(guān)系
葡萄酒俱樂(lè)部計(jì)劃部署RFID技術(shù)以提高供應(yīng)鏈的透明度
LLM在數(shù)據(jù)分析中的作用
raid 在大數(shù)據(jù)分析中的應(yīng)用
數(shù)據(jù)分析在數(shù)字化中的作用
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第一章人工智能驅(qū)動(dòng)的科學(xué)創(chuàng)新學(xué)習(xí)心得
動(dòng)態(tài)代理IP的匿名性和透明度,為主要考慮關(guān)鍵!

加州立法推動(dòng)AI透明度,生成式人工智能迎來(lái)數(shù)據(jù)披露新紀(jì)元
LED透鏡的顏色與透明度基本概念
數(shù)據(jù)分析除了spss還有什么
數(shù)據(jù)分析有哪些分析方法
Alpha半透明圖形疊加算法Matlab+Verilog的設(shè)計(jì)實(shí)現(xiàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論