 NLP:如何在只有詞典的情況下提升NER落地效果
NLP:如何在只有詞典的情況下提升NER落地效果
今天介紹一個論文autoner[1],主要是為了探索如何在只有詞典的情況下,提升NER實際落地效果;
首先,如果手中含有詞典,常規操作就是遠程監督打標數據,然后做NER;
遠程監督一個比較常見的操作就是使用我們手中的字典,通過字符匹配的形式對文本中可能存在的實體打標。
但是對于這種遠程監督的形式,存在比較多的問題,這個論文主要探討兩種:多標簽(multi-label tokens) 和標簽不完善的問題;
針對multi-label tokens,論文提出的是Fuzzy-LSTM-CRF,簡單講就是講LSTM后面的CRF層變為了Fuzzy CRF層,可以在處理tokens對應多標簽的情況下,不犧牲計算效率;
第二個問題標簽不完善,是因為字典畢竟是有限的,不可能把所有的實體都覆蓋到,那么句子中沒有被字典打標成功的詞組很有可能也是某種實體,但是遠程監督并沒有對此做處理。
針對這個問題,本文提出了一種比較新的標注框架,簡單來講就是在這新的框架中,不去預測單個的token的類別,而是去判斷兩個相鄰的tokens是不是在同一個實體中被tied;
上面只是我自己簡單的分類,其實存在的兩個問題和兩種解決架構是相互融合在一起的,具體的我們下面談。
0. 詞典形式簡單介紹
首先定義一下詞典形式,包含兩個部分,第一部分是實體的表面名稱,這個包括規范名稱和對應的同義詞列表;第二個部分就是實體的類型;
其次,詞典的標注肯定是有限的,肯定存在不在詞典中的某些詞組但是也屬于某種類型的實體;
對于這部分實體,我自己的理解大體可以包含兩個大部分;第一個大部分就是比如說【科技】這個領域覆蓋的【科技】實體有有限的,所以有漏網之魚;第二部分就是詞典的實體類型是有限的,比如詞典總共包含2個實體類型,但是你真實的文本包含更多的實體類型,存在漏網之魚。
對于這些漏網之魚的實體,我們的策略是這樣的。
首先通過AutoPhrase從文中挖掘出來高質量短語,然后統一賦值為unknown type,也就是未知類型。
1. Fuzzy-LSTM-CRF
1.1 標注策略
梳理一下,我們現在手上有詞典;
詞典包含兩個部分,一部分是已知實體類型(假設是2個,當然可能更多或者更少);另一個部分就是我們通過某種方式挖掘出來的高質量實體對應的未知類型;
然后我們通過手中的詞典對原始無標注文本進行打標;
那么現在對于句子中的某個token,它存在三種可能性;第一它可能是已知實體類型中的一種或者多種;第二它屬于未知類型;第三是屬于O這種情況,就是non-entity;
基于傳統架構BIlstm-CRF如何解決多標簽的問題?
其實本質解決的思路很簡單。對于原來的每個token,只是預測一個類別,現在是預測多個類別就可以了。
詳細點講就是,首先對于遠程監督標注的過程,我們會使用三種策略。
我們先假設我們使用{I;O;B;E;S}的標注形式;
第一,對于某個token,如果它對應到了已知類型中的某一個或者多個實體,那么按照對應的位置直接標記上,不要漏掉;也就是說{I;B;E;S}和對應的一個或者多個實體類型對上標;
第二對于對于某個token,如果屬于未知類型,那么對應的這個token就需要把所有已知實體類型(區別于上面的一個或者多個已知實體類型)和 {I,O, B, E, S}對應的打標上;
注意,這里并沒有使用未知實體類型,而是使用的所有的已知實體類型;
第三個對于既不屬于已知類型的,也不屬于未知類型的,全部打上O;
1.2 Fuzzy-LSTM-CRF 模型架構
其實很好理解,傳統的CRF最大化唯一一條有效的標注序列。在這里,我們最大化所有有可能的標注序列。
公式如下:
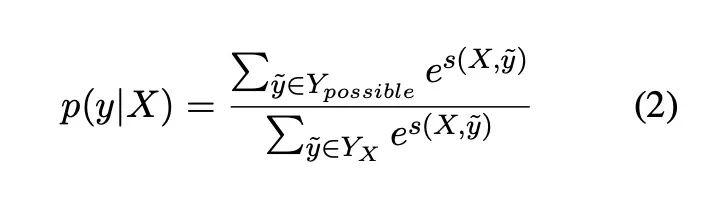
Fuzzy-LSTM-CRF優化公式
看架構圖:
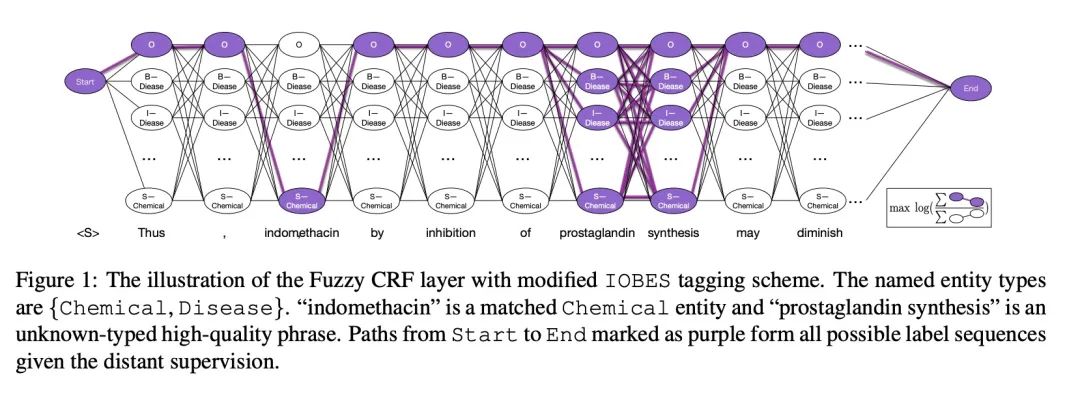
Fuzzy-LSTM-CRF
2. AutoNER
區別于Fuzzy-LSTM-CRF 模型沿用傳統架構,在這里論文提出一種新的標注架構-Tie or Break;
這個標注框架更加關注的是當前token和上一個token是否在同一個實體里面;如果在同一個實體里面,那么就標注為Tie;
如果當前單詞和上一個單詞至少有一個在unkonw類型的高質量短語,那么標注為unkonw,其他情況標注為Break;
優化過程:把實體識別和實體類型判定分離開。
原論文中描述的是先做實體識別,兩個Break之間作為一個span,然后做實體類型判定;
實體識別中,對于當前單詞和上一個單詞之間類別的的輸出,對Tie和Break做二分類損失,如果類別是unkown類別,直接跳過,不計算損失。
概率公式如下:
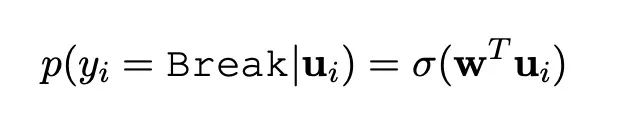
tie_break_loss
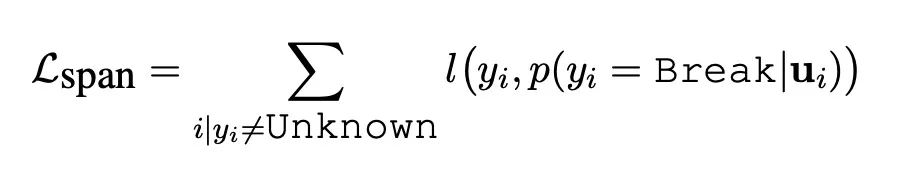
tie_break_loss
第二步預測實體類型,包含None實體類型
unkonw這種,知道這屬于實體,在高質量短語詞典中,但是不知道短語類型,所在這里我們會標注為None實體類型。
其他的不在詞典中的,當然也就會被標注為None實體類型。
為了應對多標簽,也就是同一個實體對應不同的類別,這里修改了最后的CE損失函數:
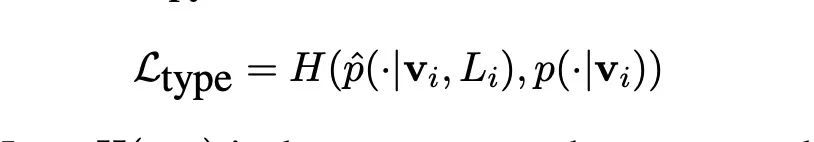
CE_總
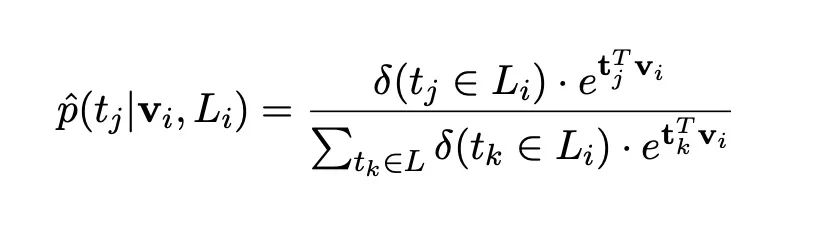
CE_Soft
使用的是軟標簽的進行的CE的計算,并沒有使用硬標簽。
對應的是在遠程監督中,當前實體真實類型標簽集合。從公式我們可以知道,尤其是看分母,在不屬于這個集合的標簽概率我們并沒有計算在內。
總結
多提一個小細節,就是高質量短語的挖掘使用的是AutoPhrase,大家可以去試一下;
論文提出兩種結構解決多標簽和標簽不完善的問題。
首先對于標簽不完善,使用上面提到的AutoPhrase去挖掘文本中的高質量短語,作為詞典中的未知類型。
在Fuzzy-LSTM-CRF,需要注意的細節是,對于未知類型的標注,我們使用的策略是標注所有已知類型;
對于AutoNER,有兩個細節需要注意,一個是新的標注框架tie or break,重點在于去看兩個相鄰單詞是否屬于同一個實體;第二個細節就是為了解決多標簽問題,修改了損失函數,使用的軟標簽;
責任編輯:xj
原文標題:【論文解讀】如何在只有詞典的情況下提升NER落地效果
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
自然語言
+關注
關注
1文章
288瀏覽量
13355 -
nlp
+關注
關注
1文章
489瀏覽量
22049
原文標題:【論文解讀】如何在只有詞典的情況下提升NER落地效果
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論