


關系抽取到底在乎什么?這是來自EMNLP20上清華大學劉知遠團隊的“靈魂發(fā)問”~ 關系抽取是每一位NLPer都很熟知的任務,特別是基于BERT的神經(jīng)關系抽取模型已經(jīng)登頂各大榜單SOTA,某些甚至直逼人類表現(xiàn)。但也許你和JayJay一樣,可能只是調(diào)個包、從不過問關系抽取的核心要素是啥吧~ 在劉知遠老師的EMNLP20論文《Learning from Context or Names? An Empirical Study on Neural Relation Extraction》中,就「關系抽取到底在乎什么」這一問題進行深入全面的探究,是難得的好文!
注意:本文所稱的關系抽取也稱關系分類,即判斷兩個實體
論文下載:https://arxiv.org/pdf/2010.01923.pdfgithub開源:https://github.com/thunlp/RE-Context-or-Names 為具備更好的閱讀體驗,本文以QA形式進行組織:
我們廢話不說,先po結論(劃重點): 1、對關系抽取的兩個主要特征(上下文信息和實體信息),進行了對比分析發(fā)現(xiàn):
上下文信息 和 實體信息 對于關系模型都很關鍵;
上下文信息是關系模型的主要信息來源;
實體信息中最重要的實體類型信息,但模型會存在對實體信息的過度依賴問題;
現(xiàn)有的數(shù)據(jù)集可能會通過實體泄漏淺層的啟發(fā)式信息,導致當前關系任務的指標虛高!
2、構建了關系預訓練模型,基于關系抽取的實體遮蔽的對比學習框架:
能幫助模型更好地的借助上下文信息和實體類型信息,避免“死記硬背”實體表面表述;
提高了多個場景下神經(jīng)關系抽取模型的有效性和魯棒性,特別是在低資源場景下;
Q1: 關系抽取為什么主要利用「上下文信息」和「實體信息」?

為什么本篇論文會選取上下文和實體信息進行對比研究呢?作者認為:
上下文信息:從人的直覺來看,文本上下文是主要的信息來源;最為簡單的一種方式,就是可以用關系模板進行歸納。如上圖所示,「... be founded ... by ...」模板就可以很好地映射到某一類關系上。因此,上下文關系肯定會對關系預測結構起著某種作用。
實體信息:實體信息主要包括實體類型、實體ID、實體屬性信息等,如果實體可以被鏈接到知識圖譜上,那么相關信息也可以被模型所利用。既然關系抽取基于實體pair進行的分類預測,那么實體信息就必不可少了。
Q2: 關系抽取的baseline模型選擇哪些?
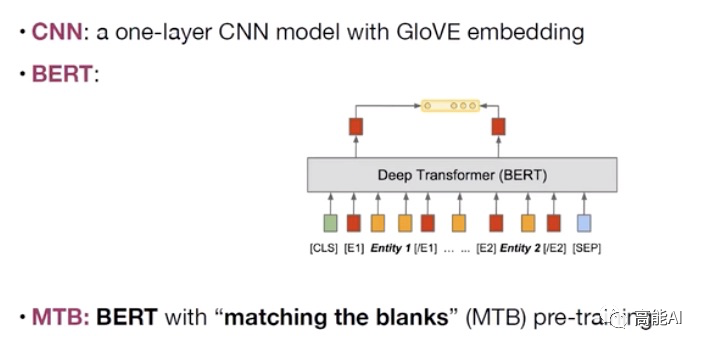
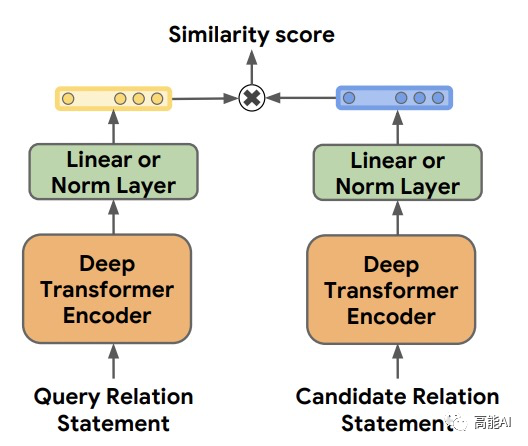
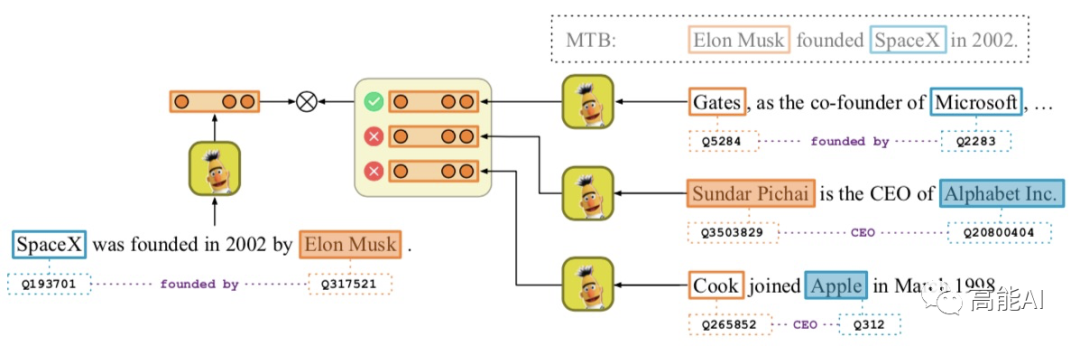
為了更好地進行分析驗證,本文主要主要采取CNN、BERT、MTB三種模型進行實驗(如上圖所示):采取BERT時主要是提取實體pair的相關標識符對應的表示進行關系分類。 MTB是由Google在2019年提出預訓練關系模型 ,其只在獲得更好的適配于關系抽取的特征表示,其具體的預訓練方式為:認為包含相同實體pair的句子表示相同的關系,將相似度得分作為預訓練目標,如下圖示意。
Q3: 「上下文信息」和「實體信息」到底哪家強?

為了分析「上下文信息」和「實體信息」對于關系模型的內(nèi)在影響,論文設置眾多輸入格式(如上圖所示):
Context+Mention (C+M) :即最為廣泛的使用方式,在原句子輸入的同時,強調(diào)實體mention:對于BERT模型,采用位置向量和特殊的實體標識符來強化metion。
Context+Type (C+T) :將實體mention用其實體類型Type代替,如上圖,「SpaceX」用「organization」代替,「Elon Musk」用「person」代替。
Only Context (OnlyC) :即只利用上下文信息,將實體mention用「subject」或「object」代替,通過這種方式可以將實體信息源完全阻擋。
Only Mention (OnlyM) :即只利用實體提及,忽略其他文本上下文的輸入。
Only Type (OnlyT) :即只利用實體類型信息,如「organization」「SEP」「person」。
論文通過上述設置在最大的有監(jiān)督關系數(shù)據(jù)集TACRED上(共42種關系,10w+實例)進行了相關實驗,結果如下(指標為micro F1值):
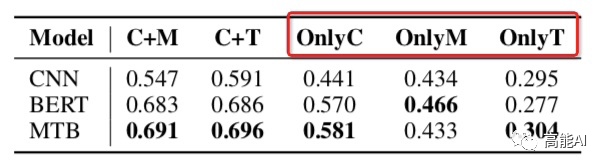
由上圖的紅框(OnlyC、OnlyM、OnlyT)可以看出,只利用上下文信息或實體信息指標都大幅下降,這表明:上下文信息 和 實體信息 對于關系模型都很關鍵;
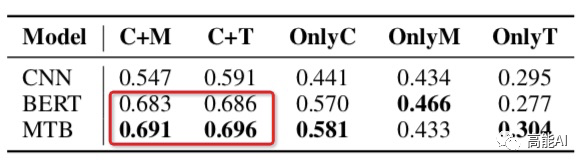
由上圖的紅框可以看出,C+M和C+T表現(xiàn)一致,這表明:實體提及中的類型Type信息很重要!這與之前女神的SOTA《反直覺!陳丹琦用pipeline方式刷新關系抽取SOTA》中關于「類型信息」的重要性相互佐證~
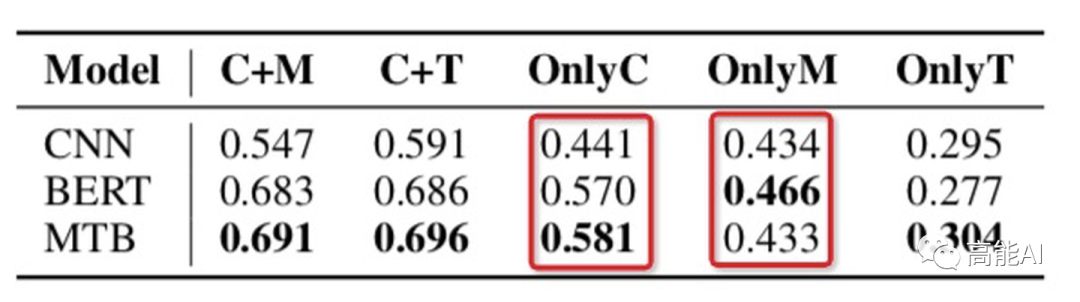
由上圖的紅框可以看出:
OnlyC總體高于OnlyM,可以看出:上下文信息比實體信息更重要~(PS:CNN中OnlyC沒有明顯高于OnlyM,也說明其上下文的捕捉能力不如BERT吧)
OnlyM也有較高指標,這表明:現(xiàn)有的數(shù)據(jù)集可能會通過實體泄漏淺層的啟發(fā)式信息,導致當前關系任務的指標虛高!
此外,本篇論文也通過Case Study進一步證明了上述結果、并有了新的發(fā)現(xiàn):
C+M與C+T類似,共享95.7%的正確預測和68.1%的錯誤預測,充分說明了實體提及的主要的信息來源是其類型Type信息。
C+M容易對實體提及產(chǎn)生過高的偏置依賴,特別是容易對訓練集中的實體提及進行“死記硬背”,如下圖:模型容易死記住訓練集中「Washington」的實體提及只存在于「stateorprovinceofresidence 」關系中,從而導致關系預測錯誤。

C+T不容易捕捉共指信息和語義信息,如下圖所示,「Natalie」和「she」兩個實體如果被實體Type替代后,不容易捕捉到原有的共指關系:

再通過對OnlyC的case分析中發(fā)現(xiàn):人類可以本能地從上下文中判斷關系,但模型似乎在捕捉上下文信息的能力上還有很大缺失。如下圖所示,具體體現(xiàn)在3個方面:
Wrong:對于那些很清晰的關系模式仍然會預測錯誤。
No pattern:對于那些不具備pattern的關系會預測錯誤。
Confusing:對于困惑的關系類型缺乏魯棒能力。

Q4: 如何提升關系模型的預測性能? 從上文的分析中,我們可以發(fā)現(xiàn):上下文信息和實體信息對于關系模型都很重要,但在一些情況下,關系模型并不能很好地理解關系模式、會過度依賴于實體mention的淺層提示信息。 為了更好地捕捉上下文信息和實體類型Type信息,論文提出了一種基于實體遮蔽的對比學習框架,來進行關系預訓練。 1、對比學習數(shù)據(jù)生成方法
對比學習預訓練框架如上圖所示,論文借鑒了「對比學習」的思想,通過聚合“neighbors”、分離“non-neighbors”來學習特征表示;通過這種模式,“neighbors”具備相似的表示。因此,定義“neighbors”對于對比學習至關重要。
本文定義:實體pair共享同種關系的句子是“neighbors”。
為了防止模型在預訓練過程中對實體mention死記硬背、或者抽取比較淺層的表面特征,作者采取了隨機mask實體的辦法,將實體mention替換為「BLANK」,替換率為0.7. 事實上,生成預訓練數(shù)據(jù)是通過遠程監(jiān)督的方法進行,這雖然會造成噪聲;但作者認為噪聲問題對于預訓練框架不是關鍵的,因為:預訓練目標是相對于像BERT這樣的原始預訓練模型,獲得相對更好的關系表示,而不是直接訓練關系模型對于下游任務,因此數(shù)據(jù)中的噪聲是可以接受的。 通過上述的對比學習生成方法,預訓練模型可以學習更好地從實體metion中掌握類型Type信息,并從文本上下文中提取關系語義:
成對的兩個句子雖然包含不同的實體pair,但共享相同的關系,提示模型發(fā)現(xiàn)這些實體mention之間的聯(lián)系。此外,實體mask策略可以有效地避免簡單的記憶實體mention。這最終鼓勵模型利用實體類型Type信息。
生成策略提供了相同關系類型下的多種上下文集合,這有利于模型學習從多種表達方式中提取關系pattern。
2、對比學習訓練目標 上述預訓練的目標函數(shù)共包含兩部分:對比學習目標( Contrastive Pre-training,CP)和遮蔽語言模型(MLM):
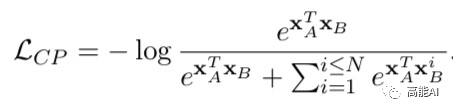
對比損失CP采取隨機負樣本采樣,加速訓練過程。 3、對比學習實驗結果
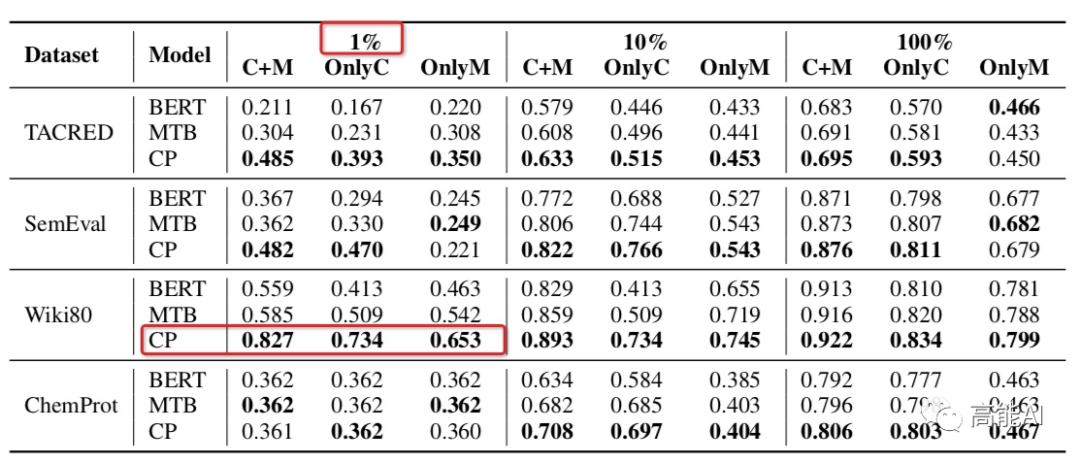
基于對比學習的預訓練框架的關系模型最終表現(xiàn)如何?作者在不同的數(shù)據(jù)集上設置不同數(shù)據(jù)使用量(1%、10%、100%)進行了對比分析,發(fā)現(xiàn):對比學習模型CP在不同數(shù)據(jù)集上均超過了BERT和MTB,特別是在低資源(1%數(shù)據(jù)量)條件下也能呈現(xiàn)較高指標,如上圖紅框所示。 可見,對比學習機制相比于Google的MTB模型更具備多樣性的數(shù)據(jù)特征、能更充分的學習實體類型Type信息。
總結 本文主要基于「關系抽取到底在乎什么」、「上下文和實體mention如何影響關系模型」進行了討論,發(fā)現(xiàn):
文本上下文和實體mention都給關系模型提供了關鍵信息;
關系抽取數(shù)據(jù)集可能會通過實體泄漏淺層的啟發(fā)式信息,導致當前關系任務的指標虛高!
關系模型并不能很好地理解關系模式、會過度依賴于實體mention的淺層提示信息
基于上述幾點,論文提出了一種基于實體遮蔽的對比學習框架來改進關系模型的表現(xiàn),最終提高了多個場景下神經(jīng)關系抽取模型的有效性和魯棒性(特別是在低資源條件下)。 有了本文全面的實驗分析,或許未來我們可以進一步研究開放關系抽取和關系發(fā)現(xiàn)問題,這些需要我們考慮zero-shot問題,但可以確信:預訓練關系模型將對這些領域產(chǎn)生積極影響。
責任編輯:xj
原文標題:劉知遠老師的“靈魂發(fā)問”:關系抽取到底在乎什么?
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
自然語言
+關注
關注
1文章
292瀏覽量
13654 -
nlp
+關注
關注
1文章
490瀏覽量
22616 -
知識圖譜
+關注
關注
2文章
132瀏覽量
8001
原文標題:劉知遠老師的“靈魂發(fā)問”:關系抽取到底在乎什么?
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
ICY DOCK PCIe可拆卸式擴展插槽硬盤抽取盒或轉接器,革新存儲解決方案

請問移植rtthread nano版時官網(wǎng)里面系統(tǒng)時鐘函數(shù)在哪里實現(xiàn)的?
ADS1298 tdr的值到底是多大,跟采樣率等有沒有什么關系?
DAC3482設置DACCLK時,到底需要設置成和DATACLK相等還是二分之一的關系?
請問AMC1203文檔中的OSC過采樣率和sinc3濾波器中的抽取率是不是同一個概念?
自然語言處理與機器學習的關系 自然語言處理的基本概念及步驟
軌道交通行業(yè) ICY DOCK硬盤抽取盒解決方案

ADS1299用ADS采集數(shù)據(jù),ADS可以不抽取看原始得數(shù)據(jù)嗎?
求助,關于AMC1306M25抽取率OSR的疑問求解
NLP技術在聊天機器人中的作用
TLV320AIC3254內(nèi)部中的ADC處理模塊和minidsp到底是什么關系?
labview如何獲取到圖像的內(nèi)存地址
求助,AD7190關于Σ-Δ ADC其中的抽取濾波器的數(shù)據(jù)轉換問題求解
INA116把電流轉換成電壓,那么還需要在乎放大器的輸入偏置電流大小嗎?
防水和防振動功能2.5 英寸SAS/SATA硬盤抽取盒 非常適合車載數(shù)據(jù)存儲






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論