") 美團(tuán)業(yè)務(wù)中智能問(wèn)答技術(shù)的相關(guān)落地與實(shí)踐介紹
美團(tuán)業(yè)務(wù)中智能問(wèn)答技術(shù)的相關(guān)落地與實(shí)踐介紹
分享嘉賓:美團(tuán) 江會(huì)星博士
導(dǎo)讀:本文主要介紹在美團(tuán)業(yè)務(wù)中智能問(wèn)答技術(shù)的相關(guān)落地與實(shí)踐。通常問(wèn)答系統(tǒng)需要提前構(gòu)建好問(wèn)答對(duì)知識(shí)庫(kù),這種方式對(duì)高頻問(wèn)題能處理的很好,但難以解決開(kāi)放性問(wèn)題。在日常生活服務(wù)中,如"去哪玩"、"住哪家酒店"等,在行前通常需要對(duì)景點(diǎn)、酒店等目的地做詳細(xì)咨詢?cè)贈(zèng)Q策,智能問(wèn)答是一種非常友好的方式來(lái)幫助用戶獲取信息。
但針對(duì)不同的景點(diǎn)、酒店等用戶問(wèn)的問(wèn)題通常不同,是開(kāi)放性的,且信息往往是動(dòng)態(tài)分布在商戶頁(yè)面詳情、政策、用戶評(píng)論、社區(qū)問(wèn)答等各類數(shù)據(jù)中。這需要提供一套智能"問(wèn)題解決"能力,實(shí)時(shí)從各類信息中找出準(zhǔn)確的信息來(lái)回答用戶問(wèn)題,輔助用戶決策。本文在簡(jiǎn)單介紹完智能問(wèn)答技術(shù)框架之后,著重介紹Document QA,Community QA, KBQA三類"問(wèn)答解決"能力。
01
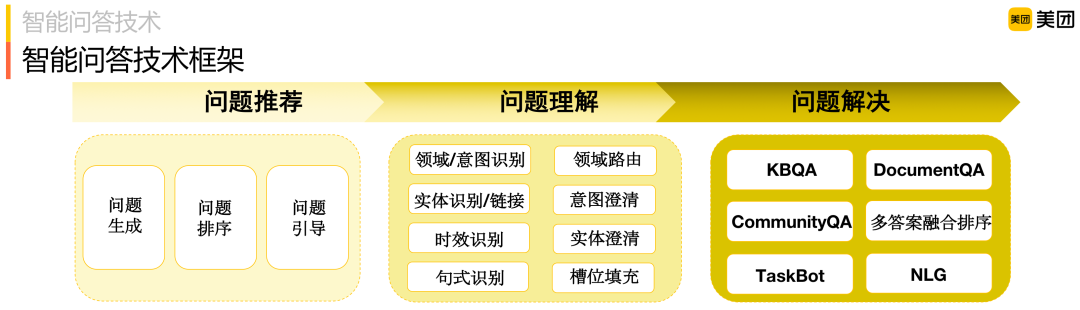
智能問(wèn)答技術(shù)框架
智能問(wèn)答通常會(huì)涉及三方面問(wèn)題:
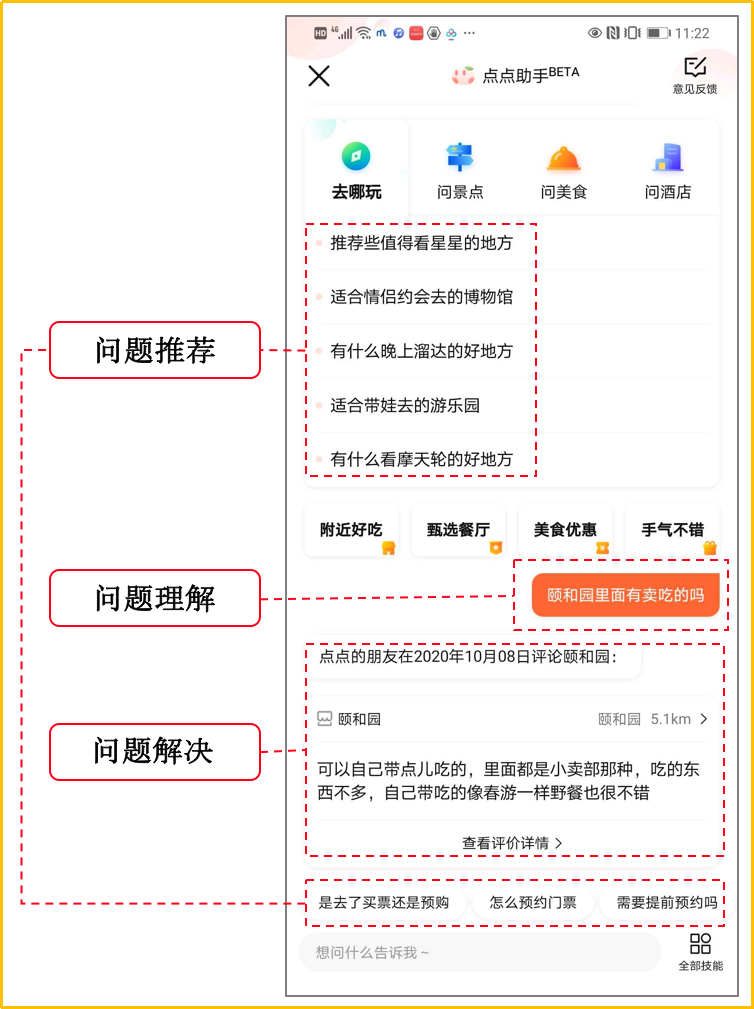
問(wèn)題推薦:當(dāng)用戶進(jìn)入智能問(wèn)答產(chǎn)品門戶時(shí),問(wèn)答系統(tǒng)通常會(huì)根據(jù)用戶信息推薦相關(guān)問(wèn)題來(lái)幫助用戶明確他的意圖,以便很好的為他服務(wù)。這里通常涉及問(wèn)題怎么來(lái) ( 問(wèn)題生成 ),推薦哪些問(wèn)題 ( 問(wèn)題排序 ) 和對(duì)話過(guò)程中還會(huì)問(wèn)哪些問(wèn)題,即多輪問(wèn)題引導(dǎo),問(wèn)答系統(tǒng)通常會(huì)考慮問(wèn)題之間的相關(guān)性,問(wèn)題間的順承關(guān)系給出相應(yīng)的問(wèn)題引導(dǎo);
問(wèn)題理解:當(dāng)用戶輸入時(shí),判斷是不是問(wèn)問(wèn)題,是哪個(gè)領(lǐng)域/意圖,有什么實(shí)體槽位,是不是時(shí)效性問(wèn)題等等。如果問(wèn)題可能屬于多個(gè)領(lǐng)域,則需要領(lǐng)域路由澄清,如果意圖不明確,則需進(jìn)一步澄清等,如果一個(gè)實(shí)體名關(guān)聯(lián)多個(gè)實(shí)體店,例如,七天酒店有很多門店,則需要澄清"你要問(wèn)的是哪一個(gè)門店";
問(wèn)題解決:給出最終問(wèn)題的答案,本文將重點(diǎn)介紹,包括基于閱讀理解的問(wèn)答 ( Document QA )、社區(qū)問(wèn)答 ( Community QA ) 以及基于圖譜的問(wèn)答 ( KBQA )。另外針對(duì)有第三方API的問(wèn)題,我們也會(huì)以TaskBot方式調(diào)用API來(lái)解決,本次主要介紹"自供給"形式的問(wèn)題解決方案,TaskBot暫不介紹。
智能問(wèn)答技術(shù)框架如下圖所示:
02
Document QA
商戶簡(jiǎn)介、攻略和UGC評(píng)論等非結(jié)構(gòu)化文檔中包含大量?jī)?yōu)質(zhì)信息,從非結(jié)構(gòu)化文檔中提取答案,即文檔問(wèn)答 ( Document QA )。近年來(lái)基于深度神經(jīng)網(wǎng)絡(luò)的機(jī)器閱讀理解 ( Machine Reading Comprehension,MRC ) 技術(shù)得到了快速的發(fā)展,逐漸成為問(wèn)答和對(duì)話系統(tǒng)中的關(guān)鍵技術(shù)。MRC模型以問(wèn)題和文檔為輸入,通過(guò)閱讀文檔內(nèi)容預(yù)測(cè)問(wèn)題的答案。
根據(jù)需要預(yù)測(cè)的答案形式不同,閱讀理解任務(wù)可以分為填空式 ( Cloze-style )、多項(xiàng)選擇式 ( Multi-choice )、片段提取式 ( Span-extraction ) 和自由文本 ( Free-form )。在實(shí)際問(wèn)答系統(tǒng)中最常使用的是片段提取式閱讀理解 ( MRC ),該任務(wù)需要從文檔中提取連續(xù)的一段文字作為答案。最具影響力的片段提取式MRC公開(kāi)數(shù)據(jù)集有SQuAD和MSMARCO等,這些數(shù)據(jù)集的出現(xiàn)促進(jìn)了MRC模型的發(fā)展。
在模型方面,深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)被較早的應(yīng)用到了機(jī)器閱讀理解任務(wù)中,并采用基于邊界預(yù)測(cè)(boundary-based prediction)方式解決片段提取式閱讀理解任務(wù)。這些模型采用多層循環(huán)神經(jīng)網(wǎng)絡(luò)+注意力機(jī)制的結(jié)構(gòu)獲得問(wèn)題和文檔中每個(gè)詞的上下文向量表示,在輸出層預(yù)測(cè)答案片段的起始位置和終止位置。
近年來(lái)預(yù)訓(xùn)練語(yǔ)言模型如BERT,RoBERTa和XLNet等在眾多NLP任務(wù)上取得突破性進(jìn)展,尤其是在閱讀理解任務(wù)上。這些工作在編碼階段采用Transformer結(jié)構(gòu)獲得問(wèn)題和文檔向量表示,在輸出層同樣采用邊界預(yù)測(cè)方式預(yù)測(cè)答案在文檔中的位置。目前在單文檔閱讀理解任務(wù)SQuAD上,深度神經(jīng)網(wǎng)絡(luò)模型的預(yù)測(cè)EM/F1指標(biāo)已經(jīng)超越了人類標(biāo)注者的水平,說(shuō)明了模型在答案預(yù)測(cè)上的有效性。
Document QA借助機(jī)器閱讀理解 ( MRC ) 技術(shù),從非結(jié)構(gòu)化文檔中抽取片段回答用戶問(wèn)題。在問(wèn)答場(chǎng)景中,當(dāng)用戶輸入問(wèn)題后,問(wèn)答系統(tǒng)首先采用信息檢索方式從商戶詳情或諸多UGC評(píng)論中查找到相關(guān)文檔,再利用MRC模型從文檔中摘取能夠確切回答問(wèn)題的一段文本。
美團(tuán)和大眾點(diǎn)評(píng)上商戶的簡(jiǎn)介攻略、UGC評(píng)論均有專業(yè)內(nèi)容運(yùn)營(yíng)團(tuán)隊(duì),可以產(chǎn)生內(nèi)容優(yōu)質(zhì)、高可信度的答案,應(yīng)用機(jī)器閱讀理解技術(shù)直接從文檔中提取答案,不需要人工維護(hù)意圖類目,可以在不同業(yè)務(wù)領(lǐng)域靈活遷移,人工維護(hù)成本小。
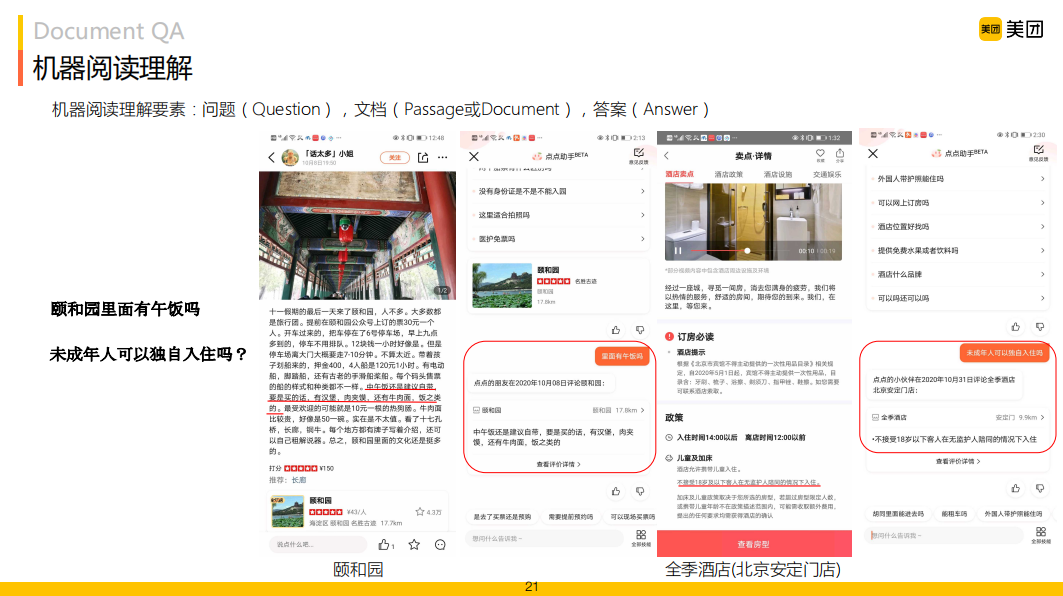
圖中左邊是頤和園的評(píng)論信息,右邊是全季酒店的詳細(xì)信息,這些信息構(gòu)成了機(jī)器閱讀理解中的文檔要素。當(dāng)詢問(wèn)"頤和園里面有午飯嗎?"、"未成年人可以獨(dú)自入住嗎?"時(shí),如果需要用戶直接從文檔中自我閱讀的話,耗時(shí)費(fèi)力。最好的方式是直接給答案,而這些答案往往隱藏在大段的文本里面。比如"頤和園里面有午飯嗎?",在評(píng)論里面描述有"中午飯還是建議自帶,要是買的話有漢堡肉夾饃,還有牛肉面飯之類的";"未成年人可以獨(dú)自入住嗎?"政策里面描述有"不接受18歲以下客人,在無(wú)監(jiān)督人陪同的情況下入住。"
1. 機(jī)器閱讀理解模型
深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)較早的應(yīng)用到機(jī)器閱讀理解任務(wù),代表性的包括Bi-DAF、R-NET、QANet、BERT等。這些模型均采用多層循環(huán)神經(jīng)網(wǎng)絡(luò)或Transformer加注意力機(jī)制等方式來(lái)解決問(wèn)題和文檔的上下文向量表示,最后通過(guò)邊界預(yù)測(cè)來(lái)獲取答案片段的起始和結(jié)束位置。我們選擇表現(xiàn)最好的BERT模型進(jìn)行相應(yīng)任務(wù)的建模,將問(wèn)題和文檔作為輸入,預(yù)測(cè)在文檔中的起始位置和結(jié)束位置,將最大可能的起始位置和結(jié)束位置之間的片段抽取出來(lái),作為答案。
文檔問(wèn)答系統(tǒng)的答案預(yù)測(cè)流程包含三個(gè)步驟:
(1) 文檔檢索與選擇 ( Retriever ):根據(jù)Query關(guān)鍵字檢索景點(diǎn)等商戶下的相關(guān)詳情和UGC評(píng)論,根據(jù)相關(guān)性排序,篩選出相關(guān)的評(píng)論用于提取候選答案;
(2) 候選答案提取 ( Reader ):利用MRC模型在每個(gè)相關(guān)評(píng)論上提取一段文字作為候選答案,同時(shí)判斷當(dāng)前評(píng)論是否有答案,預(yù)測(cè)有答案和無(wú)答案的概率;
(3) 答案排序 ( Ranker ):根據(jù)候選答案的預(yù)測(cè)得分排序。這樣能夠同時(shí)處理多篇相關(guān)評(píng)論,比較并選擇最優(yōu)答案,同時(shí)根據(jù)無(wú)答案概率和閾值判斷是否拒絕回答,避免無(wú)答案時(shí)錯(cuò)誤回答。
Document QA問(wèn)答系統(tǒng)架構(gòu)如下圖所示:
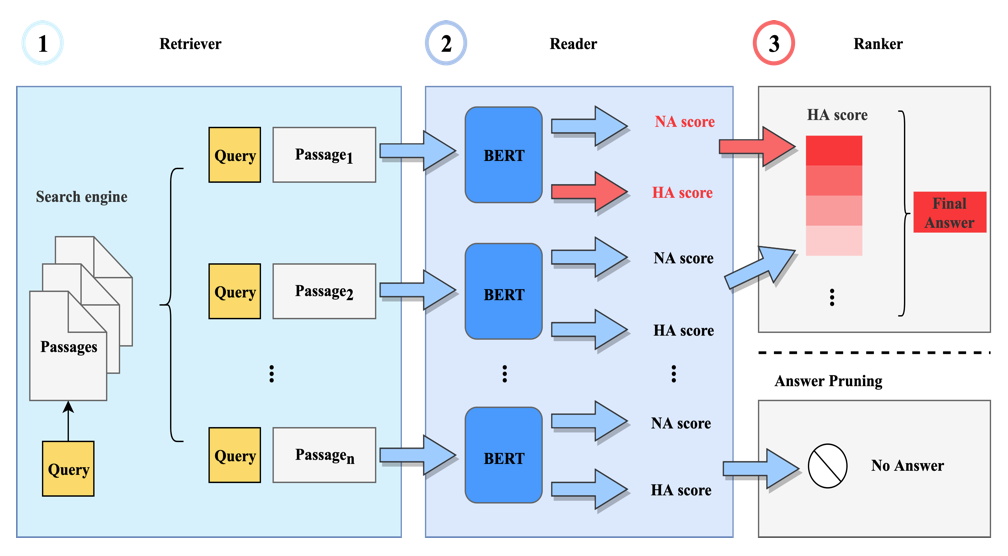
文檔檢索和排序:上圖①表示文檔檢索的過(guò)程,首先根據(jù)用戶詢問(wèn)的商戶名定位到具體商戶,通過(guò)關(guān)鍵字或向量召回該商戶下與Query相關(guān)評(píng)論或詳情信息的TopN篇文檔。
答案片段預(yù)測(cè):在答案提取任務(wù)中,將每條詳情或評(píng)論作為一個(gè)文檔 ( Document ),把用戶Query和文檔拼接起來(lái),中間加入分割符號(hào)[SEP],并在Query前加入特殊分類符號(hào)[CLS];把拼接后的序列依次通過(guò)②中的模型,在每條評(píng)論上提取一段文字作為候選答案,并預(yù)測(cè)有答案概率 ( HA Score ) 和無(wú)答案概率 ( NA Score )。長(zhǎng)度分別為N和M的Query和Document,每一個(gè)token經(jīng)過(guò)BERT Encoder,分別得到隱層向量表示Ti(i=1,2,...,N)和Tj' (j=1,2,...,M)。將Document的向量表示經(jīng)過(guò)全連接層和Softmax計(jì)算后得到每個(gè)Token作為答案起始和終止位置的概率Pistart和Pjend,然后找到Pistart*Pjend(i,j=1,2,...,M,i<j)最大的組合,將位置i和j之間文字作為候選答案,Pistart*Pjend作為有答案概率 ( HA Score )。
答案排序:答案重排序部分如③所示,根據(jù)前一步的候選答案得分 ( HA Score ) 排序,選擇最相關(guān)的一個(gè)或多個(gè)答案輸出。
無(wú)答案判斷:在實(shí)際使用中還會(huì)面臨召回文檔無(wú)答案問(wèn)題,需要在答案提取的同時(shí)加入無(wú)答案判斷任務(wù)。我們的具體做法是聯(lián)合訓(xùn)練,將BERT模型的[CLS]位置的向量表示C經(jīng)過(guò)額外的全連接層和二分類Softmax,得到無(wú)答案概率 ( NA Score ),根據(jù)無(wú)答案概率 ( NA Score ) 和人為設(shè)定的閾值判斷是否需要拒絕回答。
Document QA在實(shí)際落地過(guò)程中也發(fā)現(xiàn)了一些問(wèn)題。通常情況下,MRC模型抽取的答案偏短,回答信息不充分,如問(wèn)“停車方便嗎”,答案為“停車方便‘,從MRC任務(wù)看,這樣的回答也很不錯(cuò),但該答案并沒(méi)有回答為什么方便,信息不充分,更期望的答案是”停車方便,有免費(fèi)停車場(chǎng)“。
我們通過(guò)在構(gòu)造模型訓(xùn)練數(shù)據(jù)時(shí)選擇更完整的句子作為標(biāo)準(zhǔn)答案,在預(yù)測(cè)時(shí)盡量選擇完整的句子作為回答等方式來(lái)優(yōu)化解決;另一個(gè)問(wèn)題是時(shí)效性問(wèn)題,比如”現(xiàn)在需要預(yù)約嗎?“明確地問(wèn)當(dāng)前的情況,如果用經(jīng)典的閱讀理解獲取的答案可能是”可以預(yù)約“和”不可以預(yù)約“。通常情況下,這種信息在我們UGC是大量存在的,不過(guò)有一些信息,非常好的答案可能是一個(gè)時(shí)效性很差的問(wèn)題,或是很久以前的評(píng)論,這種對(duì)用戶來(lái)說(shuō)幫助不大。
所以我們對(duì)時(shí)效性進(jìn)行了相應(yīng)處理,根據(jù)時(shí)間的關(guān)鍵詞,包括現(xiàn)在、今天,也包括一些事件如櫻花、桃花等,它們都有一些特定時(shí)間點(diǎn),這些都作為時(shí)間詞來(lái)處理。還有很多場(chǎng)景,比如景點(diǎn)、酒店等領(lǐng)域,通過(guò)梳理也能發(fā)現(xiàn)有一些意圖跟時(shí)效性相關(guān),比如說(shuō)門票、營(yíng)業(yè)狀態(tài)等,我們對(duì)它們也做相應(yīng)的時(shí)效性處理;再就是”是否類“問(wèn)題缺少直接回答,MRC模型用于答案片段抽取,適合回答事實(shí)類的描述性問(wèn)題。
但是真實(shí)存在大量的”是不是、是否、能否“等是否類問(wèn)題,如”酒店提供飲食嗎?“,原來(lái)的回答是”早上10元一位管吃飽“,但是回答的不夠直接,我們希望同時(shí)也能更直接地先回答是否。故此我們采用多任務(wù)的學(xué)習(xí)方式,在MRC模型上加入了Yes/No的分類任務(wù),來(lái)判斷答案的觀點(diǎn)是肯定還是否定。改進(jìn)后的答案為”是的。早上10元一位管吃飽“。
最終,我們的MRC模型架構(gòu)如下圖所示:
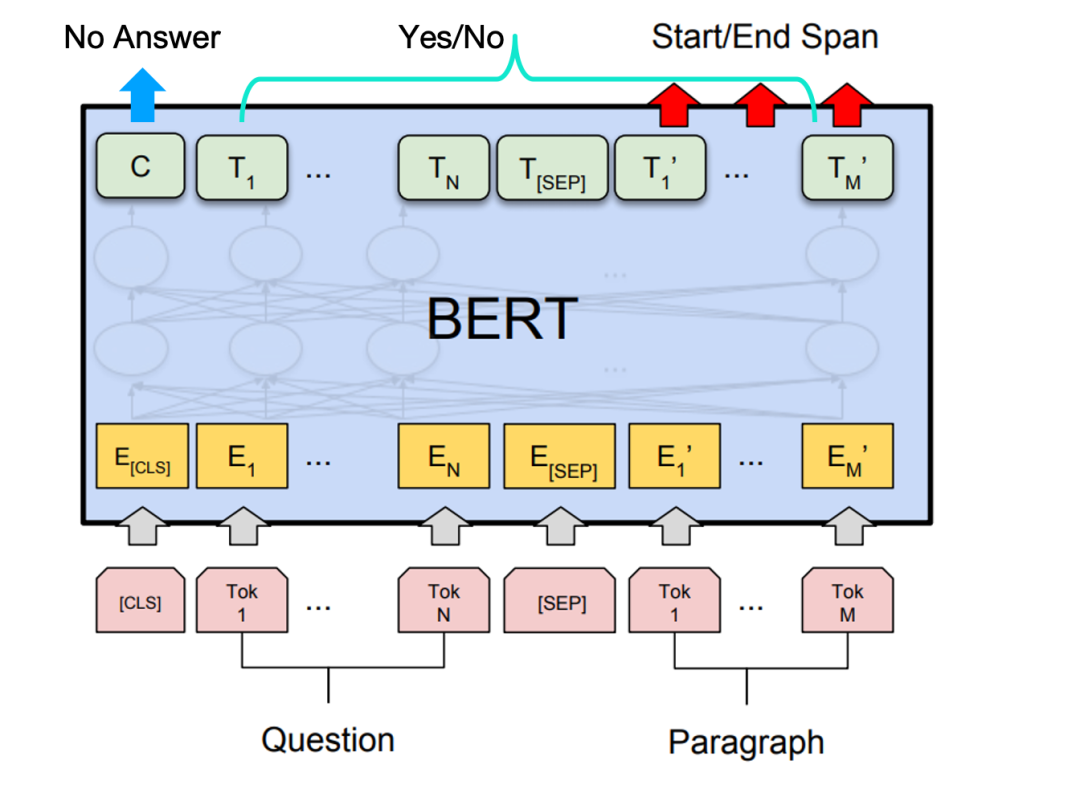
2. 多文檔機(jī)器閱讀理解
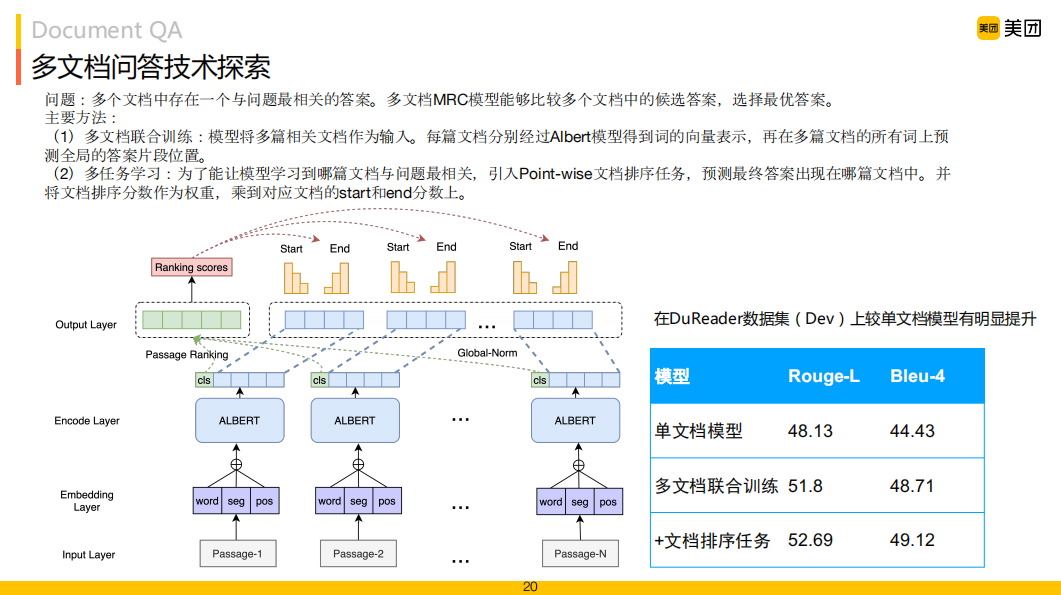
另外,針對(duì)當(dāng)前應(yīng)用從多個(gè)文檔中查找一個(gè)與問(wèn)題最相關(guān)的答案,促使我們嘗試多文檔MRC模型,即直接對(duì)多文檔進(jìn)行閱讀理解的建模,從而選擇最優(yōu)的一個(gè)作為最終答案。在上圖左邊結(jié)構(gòu)中,我們將多篇文檔作為輸入,每篇文檔都預(yù)測(cè)它的起始和結(jié)束位置,然后通過(guò)文檔排序任務(wù)將多文檔的相關(guān)性進(jìn)行加權(quán),對(duì)每個(gè)片段的得分進(jìn)行排序。右邊表格是我們的模型在公開(kāi)數(shù)據(jù)集DuReader上的驗(yàn)證結(jié)果,通過(guò)比較單文檔模型、多文檔聯(lián)合訓(xùn)練以及在多文檔聯(lián)合訓(xùn)練基礎(chǔ)上增加排序任務(wù)加權(quán),Rouge-L和Bleu-4值都有大幅提升,當(dāng)前我們的模型在DuReader Leaderboard上排名第一。
03
Community QA
社區(qū)問(wèn)答 ( Community Question Answering,CQA ) 和常見(jiàn)問(wèn)題問(wèn)答 ( Frequently Asked Questions,F(xiàn)AQ ) 是基于問(wèn)答對(duì)的問(wèn)答系統(tǒng)的兩種方式。FAQ通常由人工事先維護(hù)好問(wèn)答知識(shí)庫(kù),當(dāng)用戶問(wèn)問(wèn)題時(shí),根據(jù)相似度匹配到最相關(guān)的問(wèn)題,并給出對(duì)應(yīng)的答案。FAQ在限定領(lǐng)域內(nèi)回答質(zhì)量較好,但是問(wèn)答知識(shí)庫(kù)整理成本高。隨著社交媒體的發(fā)展,CQA可以通過(guò)社交平臺(tái)獲得大量用戶衍生的問(wèn)題答案對(duì),為基于問(wèn)答對(duì)的問(wèn)答系統(tǒng)提供了穩(wěn)定可靠的問(wèn)答數(shù)據(jù)。
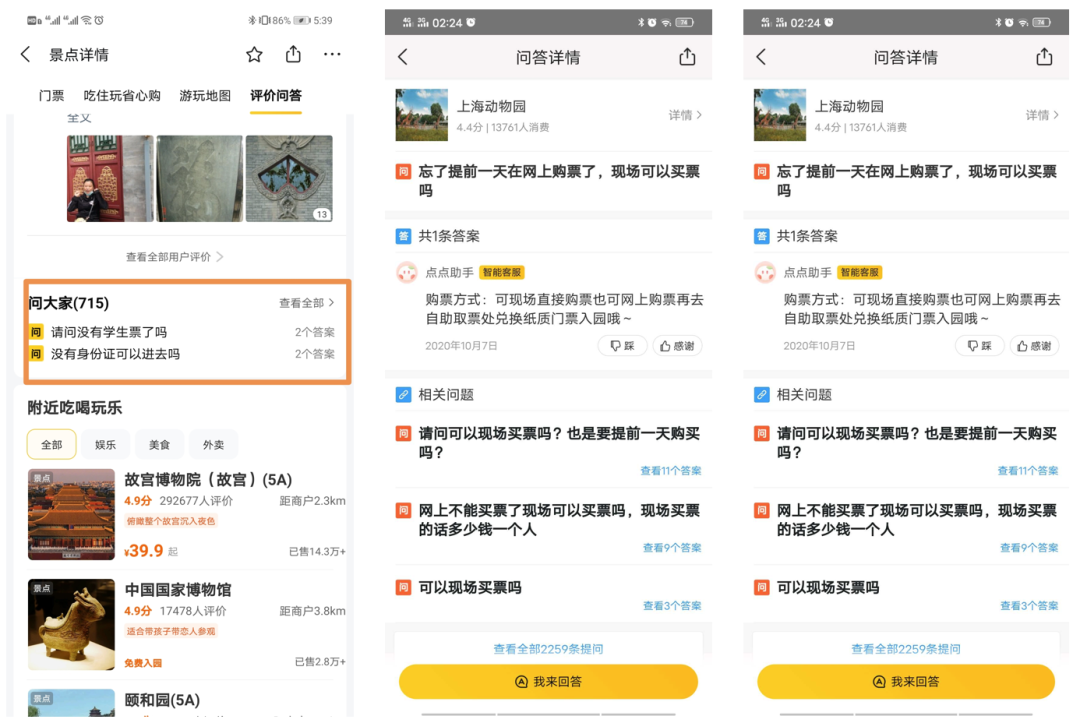
在美團(tuán)和大眾點(diǎn)評(píng)APP中,商戶詳細(xì)頁(yè)中有一個(gè)"問(wèn)大家"模塊,其問(wèn)題和答案都是由用戶生成,含有關(guān)于當(dāng)前商戶許多用戶關(guān)心的關(guān)鍵信息,比如景點(diǎn)相關(guān)的"是否允許攜帶寵物"等客觀問(wèn)題,以及"停車是否方便"等主觀問(wèn)題,很大程度上能回答用戶對(duì)于景點(diǎn)或其他商戶的開(kāi)放域問(wèn)題。
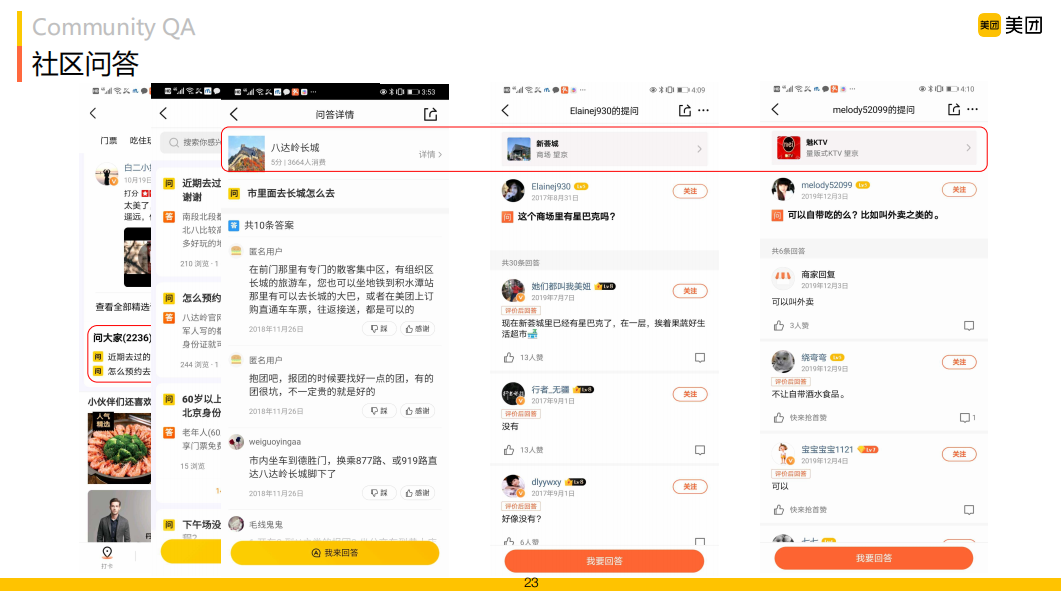
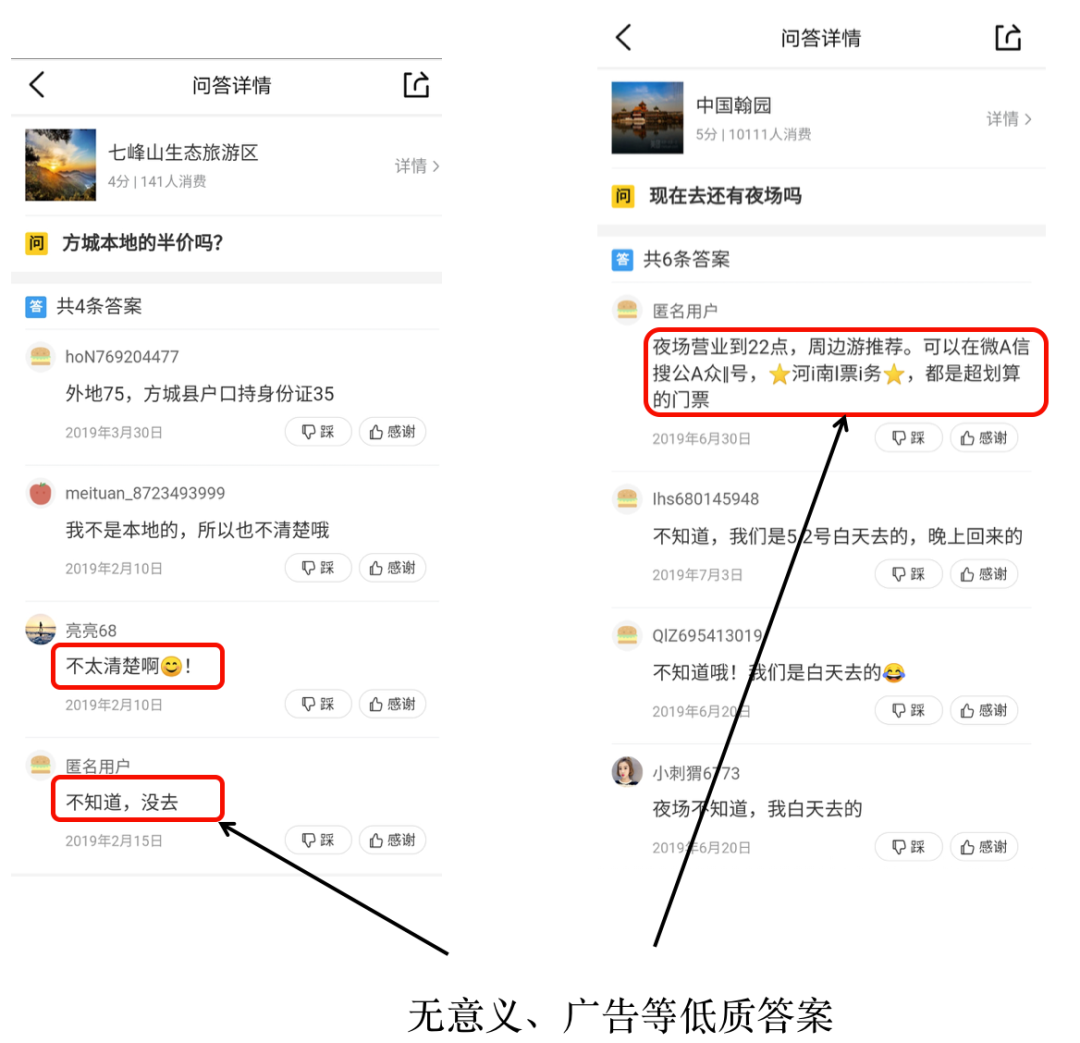
在問(wèn)大家數(shù)據(jù)中,每個(gè)商戶下通常存在多個(gè)問(wèn)題,且每個(gè)問(wèn)題下有多個(gè)用戶回答的答案。如圖所示,對(duì)于八達(dá)嶺長(zhǎng)城,有2000多個(gè)大家問(wèn)的問(wèn)題,"市里面去長(zhǎng)城怎么去"問(wèn)題下有10條不同用戶回答的答案。由于社區(qū)問(wèn)答中知識(shí)分享并不存在義務(wù)性,有價(jià)值的問(wèn)答中往往混雜有大量無(wú)意義的信息,甚至語(yǔ)義相左的答案。如關(guān)于新薈城"這個(gè)商場(chǎng)里有星巴克嗎?"答案中既有肯定的回答,也包含"好像沒(méi)有"等。用戶回答的質(zhì)量參差不齊,如何挑選出好的答案,就非常重要。
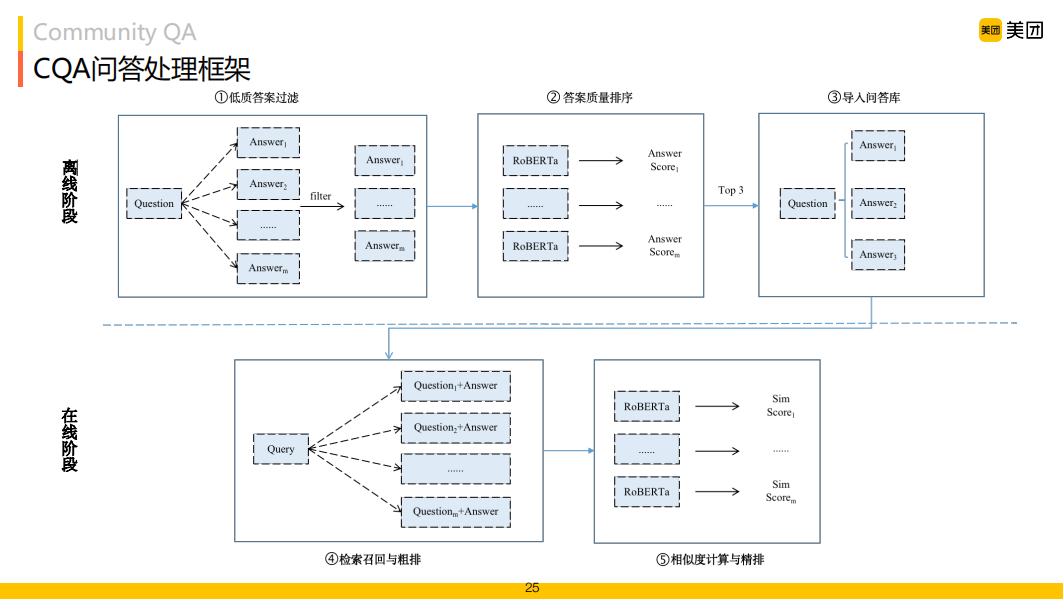
CQA問(wèn)答系統(tǒng)處理框架如上圖所示,我們將問(wèn)題處理分為兩個(gè)階段,首先離線階段通過(guò)低質(zhì)量過(guò)濾、答案質(zhì)量排序等維護(hù)一個(gè)相對(duì)質(zhì)量較好的問(wèn)題-答案庫(kù),在線階段,從知識(shí)庫(kù)中檢索得到答案并回答用戶。
1. 答案質(zhì)量過(guò)濾
由于問(wèn)大家數(shù)據(jù)中用戶回復(fù)答案質(zhì)量的參差不齊,需要過(guò)濾掉與問(wèn)題無(wú)關(guān)的低質(zhì)量答案,保留相關(guān)性強(qiáng)的答案。我們采用了如下方法保證答案質(zhì)量:
低質(zhì)量答案過(guò)濾:?jiǎn)柎蠹覕?shù)據(jù)中存在一些無(wú)意義、廣告、不禮貌等低質(zhì)量答案,嚴(yán)重影響答案質(zhì)量和用戶體驗(yàn)。我們通過(guò)對(duì)問(wèn)答數(shù)據(jù)分析并總結(jié)出一些廣告、不禮貌的敏感詞和Pattern,通過(guò)Pattern匹配的方式過(guò)濾;總結(jié)一些表示無(wú)意義信息的關(guān)鍵詞,更新到停用詞表中,通過(guò)計(jì)算答案中停用詞占比方式對(duì)無(wú)意義答案進(jìn)行過(guò)濾。
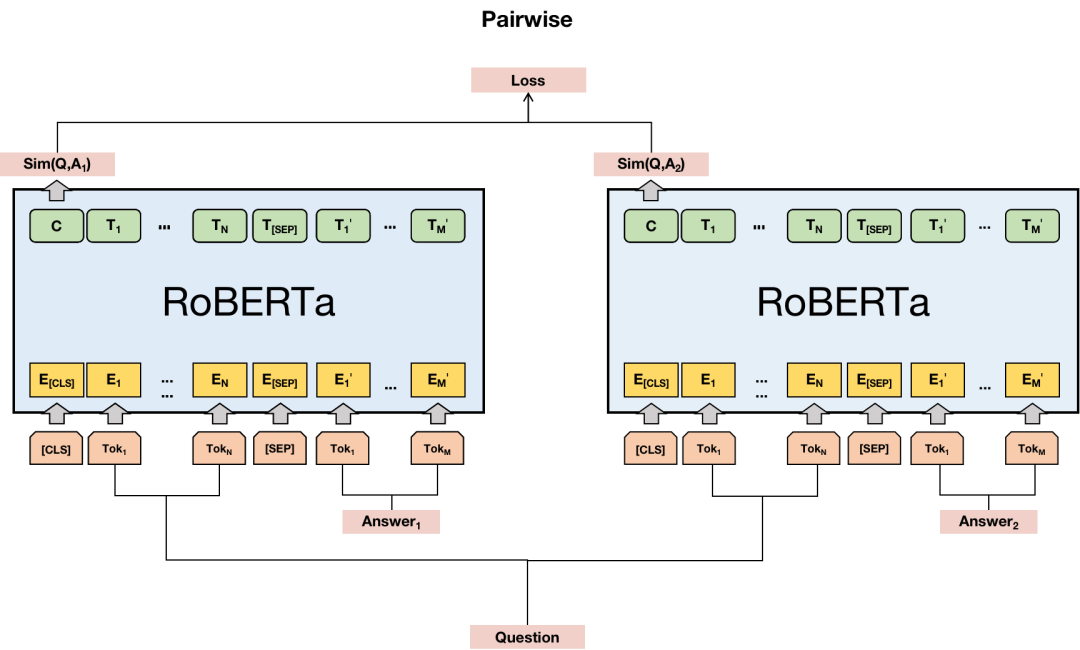
答案質(zhì)量排序:除了對(duì)低質(zhì)量問(wèn)題過(guò)濾外,我們期望對(duì)有多個(gè)答案的情況進(jìn)行相應(yīng)的排序。將質(zhì)量更好的答案排在前面。基于Pairwise方式的排序模型其訓(xùn)練目標(biāo)不僅要將候選答案分類到正確的類別,更關(guān)注于將Top K的結(jié)果排在前面,這與我們的業(yè)務(wù)目標(biāo)一致,因此我們使用基于Pairwise方式的RoBERTa模型對(duì)答案質(zhì)量進(jìn)行排序。在訓(xùn)練階段,給定一個(gè)問(wèn)題Q和兩個(gè)候選答案A1和A2,組成三元組 (Q,A1,A2) 輸入到模型中,其中第一個(gè)候選答案A1比第二個(gè)候選答案A2質(zhì)量要好。
在模型訓(xùn)練時(shí),這個(gè)三元組被拆分為兩個(gè)問(wèn)答對(duì) (Q,A1) 和 (Q,A2)。每個(gè)問(wèn)答對(duì) (Q,A) 通過(guò)[SEP]標(biāo)識(shí)符分割,并在問(wèn)題前加入[CLS],最終以[CLS] Q [SEP] A [SEP]的形式輸入到Bert模型中。然后得到[CLS]的輸出作為問(wèn)答對(duì)的表示,經(jīng)過(guò)一個(gè)全連接層和Softmax得到問(wèn)答相似度值。我們將兩個(gè)候選答案的交叉熵?fù)p失和合頁(yè)損失作為最終的損失函數(shù)。在預(yù)測(cè)階段,將問(wèn)答對(duì)輸入到模型中得到文本相似度值,根據(jù)這個(gè)值對(duì)同一問(wèn)題下的不同答案排序,從而選出Top答案。
2. 在線問(wèn)題匹配
在線階段解決的是將用戶的問(wèn)題與知識(shí)庫(kù)知識(shí)進(jìn)行匹配的問(wèn)題。同時(shí)考慮文本相關(guān)性和語(yǔ)義相關(guān)性,將問(wèn)題匹配分為召回和精排兩步:
第一步檢索召回候選問(wèn)題并進(jìn)行粗排;
第二步根據(jù)語(yǔ)義相似度對(duì)候選答案進(jìn)行精排,返回Top-K問(wèn)題和對(duì)應(yīng)答案。
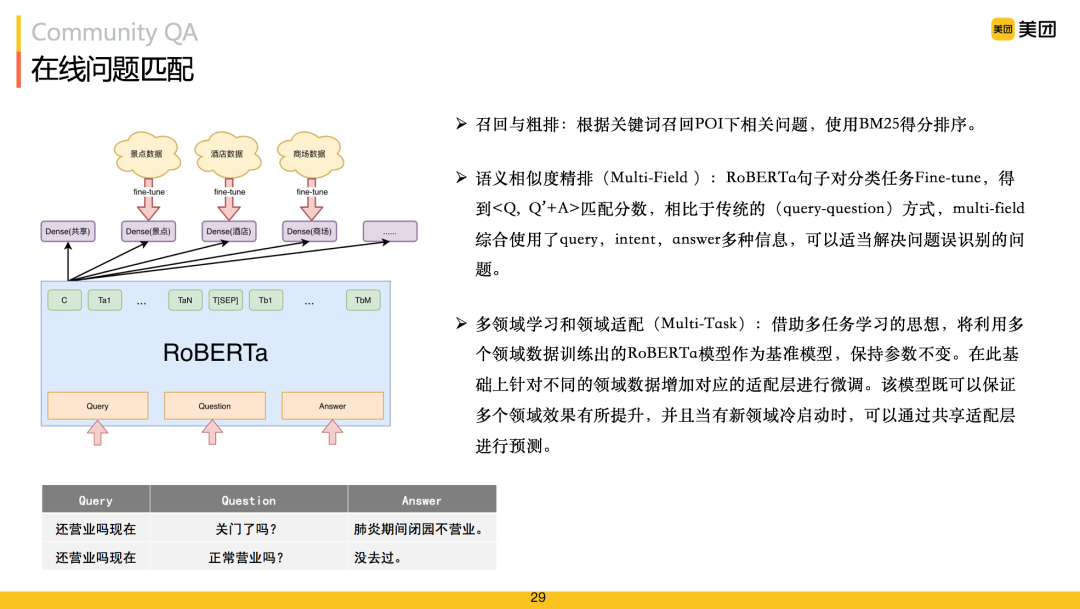
在我們的任務(wù)中涉及到景點(diǎn)、酒店、商場(chǎng)等多場(chǎng)景,多領(lǐng)域知識(shí)適配任務(wù)突出。模型框架首先建模成Multi-Task架構(gòu),所有領(lǐng)域數(shù)據(jù)訓(xùn)練出一個(gè)共享參數(shù),解決新領(lǐng)域與冷啟動(dòng)的問(wèn)題,同時(shí)不同的領(lǐng)域,也會(huì)得到各自領(lǐng)域的參數(shù),提升各自領(lǐng)域效果。除此之外,也發(fā)現(xiàn)只計(jì)算用戶的Query和問(wèn)答對(duì)里問(wèn)題的相似度,是不太夠的。
答案往往也能幫助我們更好的去理解問(wèn)題。上圖中"還營(yíng)業(yè)嗎現(xiàn)在"的問(wèn)題,語(yǔ)義上"正常營(yíng)業(yè)嗎?"比"關(guān)門了嗎?"更相關(guān),但從答案"肺炎期間閉園不營(yíng)業(yè)"和"沒(méi)去過(guò)"中很容易辨識(shí)出第一條答案更相關(guān)。因此建模時(shí)我們將答案也考慮進(jìn)去,采用Multi-Field框架。最終我們的模型為Multi-Field Multi-Task RoBERTa模型。
04
KBQA
在我們商戶頁(yè)面上還存在營(yíng)業(yè)時(shí)間、地址、套餐價(jià)格等結(jié)構(gòu)化信息,商場(chǎng)商戶下還存在各商鋪樓層分布、主營(yíng)商品等信息,這類結(jié)構(gòu)化信息源我們采用基于知識(shí)圖譜的問(wèn)答方式來(lái)回答用戶問(wèn)題。KBQA是一種基于知識(shí)圖譜的問(wèn)答技術(shù),其主要任務(wù)是將自然語(yǔ)言問(wèn)題 ( NLQ ) 通過(guò)不同方法映射到結(jié)構(gòu)化的查詢,并在知識(shí)圖譜中獲取答案。相比非結(jié)構(gòu)化文本問(wèn)答方法利用圖譜豐富的語(yǔ)義關(guān)聯(lián)信息,能夠深入理解用戶問(wèn)題、解決更多復(fù)雜推理類問(wèn)題。
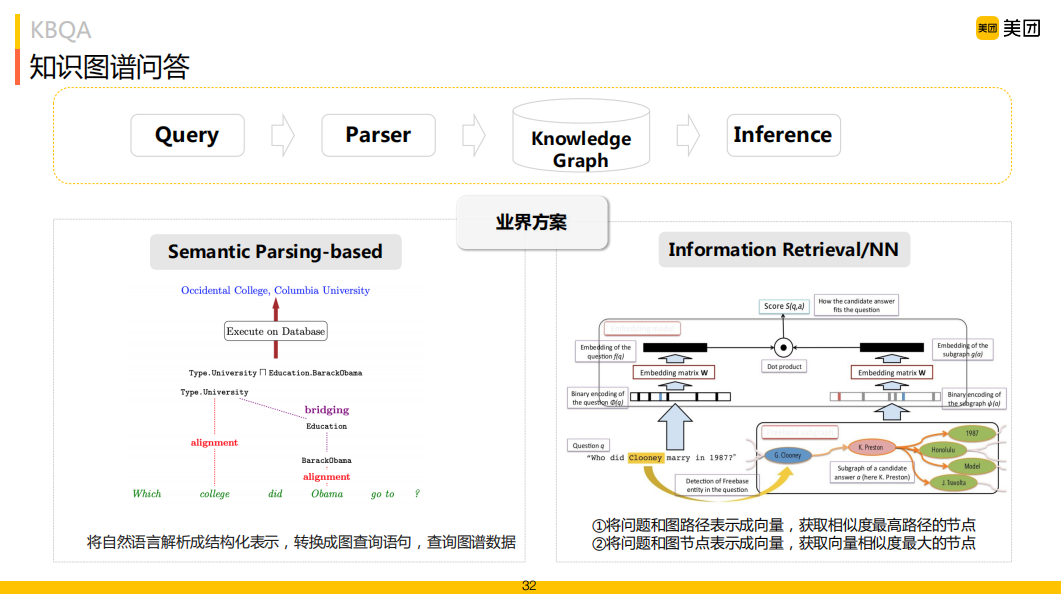
主流的KBQA解決方案包括基于查詢圖方法 ( Semantic Parser )、基于搜索排序方法 ( Information Retrieval )。查詢圖方案核心思路就是將自然語(yǔ)言問(wèn)題經(jīng)過(guò)一些語(yǔ)義分析方式轉(zhuǎn)化成中間的語(yǔ)義表示 ( Logical Forms ),然后再將其轉(zhuǎn)化為可以在 KG 中執(zhí)行的描述性語(yǔ)言 ( 如 SPARQL 語(yǔ)言 ) 在圖譜中查詢,這種方式優(yōu)勢(shì)就是可解釋強(qiáng),符合知識(shí)圖譜的顯示推理過(guò)程。
搜索排序方案首先會(huì)確定用戶Query中的實(shí)體提及詞 ( Entity Mention ),然后鏈接到 KG 中的主題實(shí)體 ( Topic Entity ),并將與Topic Entity相關(guān)的子圖 ( Subgraph ) 提取出來(lái)作為候選答案集合,通過(guò)對(duì)Query以及Subgraph進(jìn)行向量表示并映射到同一向量空間,通過(guò)兩者相似度排序得到答案。這類方法更偏向于端到端的解決問(wèn)題,但在擴(kuò)展性和可解釋性上不如查詢圖方案。在美團(tuán)場(chǎng)景里我們采用以Semantic Parser方法為主的解決方案。
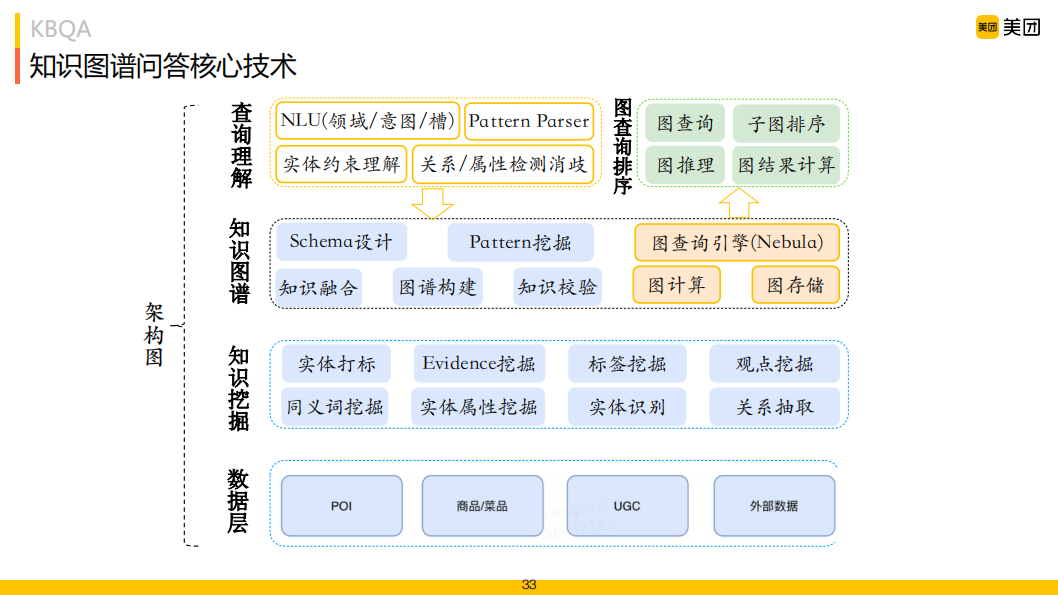
知識(shí)圖譜問(wèn)答核心技術(shù)共分為四層,數(shù)據(jù)層、知識(shí)挖掘和知識(shí)圖譜層為知識(shí)圖譜構(gòu)建常見(jiàn)架構(gòu),知識(shí)圖譜問(wèn)答的關(guān)注重點(diǎn)為上層查詢理解、圖查詢及圖排序部分。

在對(duì)話理解階段,我們已將用戶輸入的Query理解成領(lǐng)域、意圖和槽位的形式,比如"頤和園學(xué)生門票多少錢"理解為門票意圖,"頤和園"是travel_landmark,"學(xué)生門票"是ticket_type。在KBQA的查詢理解階段我們只需要解決好關(guān)系/屬性檢測(cè)和消歧、實(shí)體約束理解。
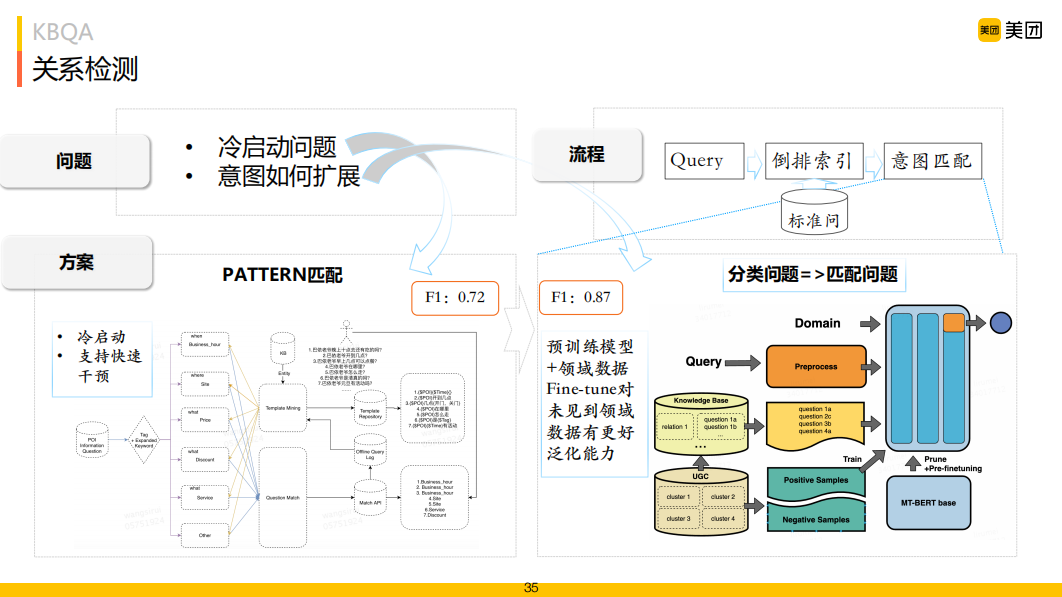
對(duì)于圖譜問(wèn)答來(lái)說(shuō),如何檢測(cè)出圖中關(guān)系?一種是定義關(guān)系Pattern,建立Pattern和關(guān)系的映射關(guān)系;另一種是將關(guān)系檢測(cè)定義為分類任務(wù),或者是匹配任務(wù),每種關(guān)系提前維護(hù)好可能全的不同說(shuō)法,通過(guò)計(jì)算用戶Query與關(guān)系說(shuō)法的相似度匹配來(lái)確定關(guān)系。它的一個(gè)好處就是對(duì)冷啟動(dòng)非常友好,而分類通常需要構(gòu)建大量的訓(xùn)練數(shù)據(jù)集,冷啟動(dòng)不友好。關(guān)系檢測(cè)我們采用了Pattern和說(shuō)法匹配相結(jié)合的方式。
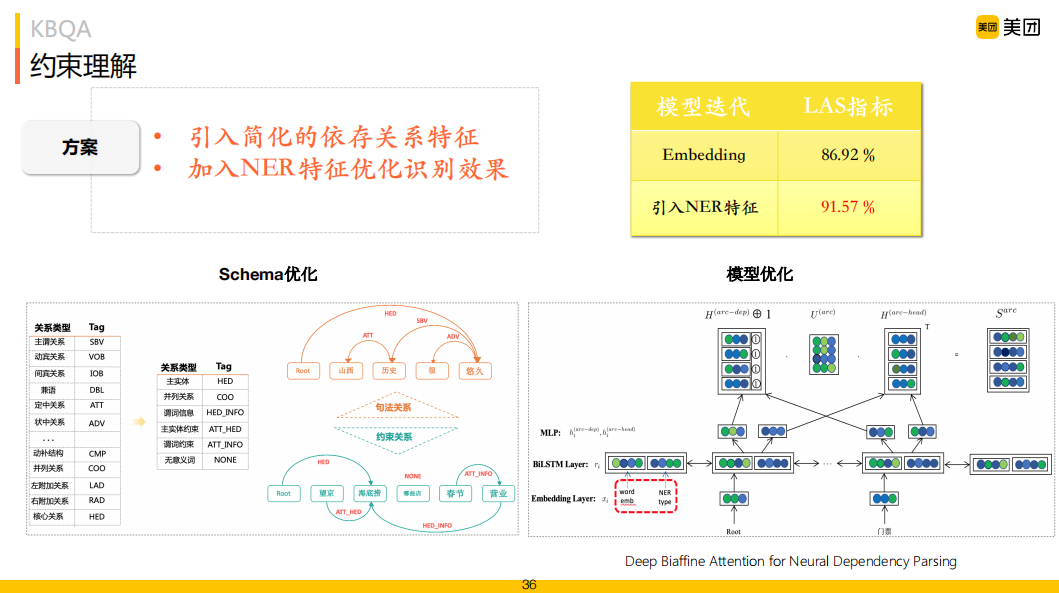
約束理解我們建模為依存理解問(wèn)題,相比通用的依存理解,依據(jù)我們的業(yè)務(wù)場(chǎng)景將關(guān)系數(shù)量縮減到只有六類,主實(shí)體、并列關(guān)系、謂詞信息、主實(shí)體約束、謂詞約束和無(wú)意義詞。模型選擇上采用比較經(jīng)典的Deep Biaffine模型,在這里通過(guò)在輸入層加入NER的特征,如圖右上角所示,指標(biāo)上有較大的提升。
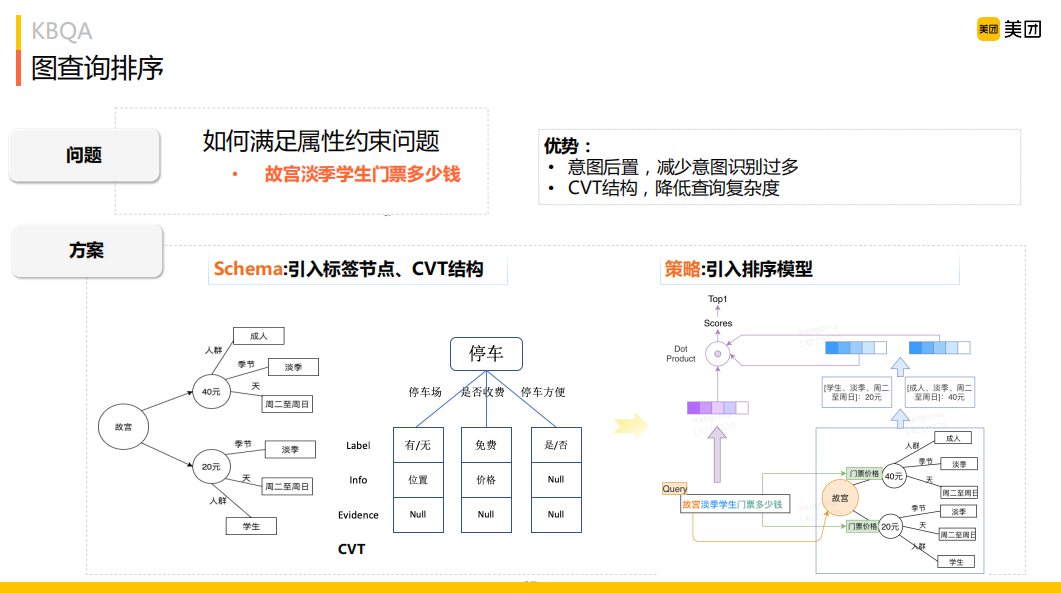
圖查詢排序方面,首先引入標(biāo)簽節(jié)點(diǎn)、CVT結(jié)構(gòu),將約束關(guān)聯(lián)到節(jié)點(diǎn)上。比如"故宮成人票多少錢",它的意圖是問(wèn)故宮價(jià)格,如圖左下角所示,成人票是價(jià)格的一個(gè)約束,建模時(shí)把約束"成人"建在"價(jià)格"的節(jié)點(diǎn)上。在線查詢時(shí),通過(guò)一跳就能查詢到價(jià)格節(jié)點(diǎn),我們要做的事情就是約束匹配,找到一條最優(yōu)的路徑;再就是引入排序模型,排序解決的就是選擇含約束條件的最優(yōu)路徑。這樣常見(jiàn)的約束可以比較快的整理出來(lái),不常見(jiàn)的約束也可以作為約束節(jié)點(diǎn)加進(jìn)去,因排序模型解決了相似計(jì)算問(wèn)題,對(duì)于未見(jiàn)過(guò)的約束類型也同樣生效。
05
多QA答案融合排序
上述問(wèn)答模塊在回答范圍上各有側(cè)重,但對(duì)于同一個(gè)用戶問(wèn)題,不同的問(wèn)答模塊都有可能返回候選答案,如下表格中例子所示,有多個(gè)候選答案,如何做出選擇。
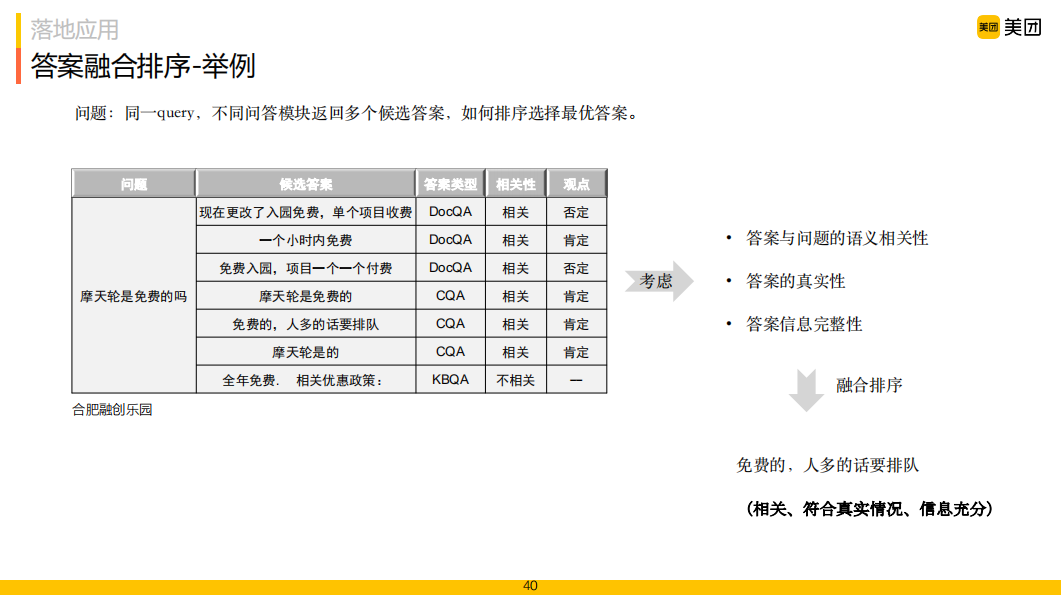
在答案選擇時(shí)主要考慮以下三個(gè)因素:
答案與問(wèn)題的語(yǔ)義相關(guān)性:我們希望選擇與問(wèn)題在語(yǔ)義上最相關(guān)的答案;
答案信息完整性:我們希望答案能夠完整地回答問(wèn)題,而不僅僅回答問(wèn)題的一個(gè)方面 ( 如問(wèn)題"停車是否方便",回答"停車方便,有免費(fèi)停車場(chǎng)"比僅回答"停車方便"更好 );
答案的真實(shí)性:多個(gè)答案在觀點(diǎn)上可能存在相互矛盾,我們需要選擇最接近實(shí)際情況的答案。
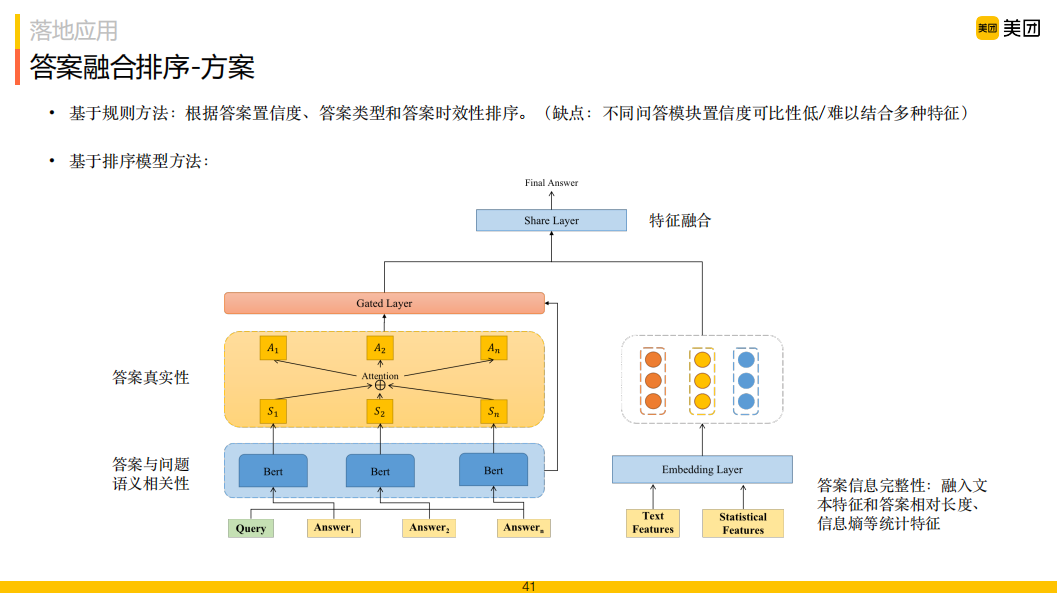
在初始階段我們采用基于規(guī)則的方式,主要考慮答案的相關(guān)性和真實(shí)性。在相關(guān)性方面考慮答案的類型 ( KBQA、CQA和DocQA ) 和置信度,根據(jù)答案置信度的類型排序。每種問(wèn)答方案根據(jù)答案置信度將答案分為兩級(jí),級(jí)別越高優(yōu)先級(jí)越高,同一級(jí)別的優(yōu)先級(jí)為KBQA > CQA > DocQA;在答案真實(shí)性方面主要考慮答案時(shí)間,時(shí)間越久的答案真實(shí)性越差,超過(guò)一定時(shí)間 ( 如2年 ) 的答案會(huì)被降低在排序中的級(jí)別;對(duì)于時(shí)效類問(wèn)題,如“景區(qū)最近花開(kāi)了嗎”,超過(guò)3個(gè)月的答案將不會(huì)被采用。這里的問(wèn)題是不同類型的答案置信度分?jǐn)?shù)往往是不能相互比較的,總會(huì)有一些Bad Case存在。
再就是基于排序模型的方式:
利用問(wèn)題和答案的語(yǔ)義相似度匹配的方式,建模答案與問(wèn)題語(yǔ)義相關(guān)性,為了提高排序模型效果,我們?cè)谂判驎r(shí)利用到了問(wèn)題所對(duì)應(yīng)的NLU意圖信息,將模型的輸入從"問(wèn)題+答案"形式轉(zhuǎn)化為"問(wèn)題+意圖+答案"形式,充分利用意圖信息,提高相關(guān)性計(jì)算準(zhǔn)確率;
假設(shè)問(wèn)題的正確答案往往會(huì)出現(xiàn)在多篇文章中,且有共同點(diǎn),將基于問(wèn)答相似度的答案排序模型與多答案交叉推理模型進(jìn)行聯(lián)合訓(xùn)練。具體地,我們將上述排序模型得到的[CLS]向量 ( 或其他層向量 ) 作為答案的語(yǔ)義表示,然后計(jì)算每個(gè)候選答案與剩余候選答案之間的Attention來(lái)整合他們之間的信息,通過(guò)門控機(jī)制將BERT模型輸出的相關(guān)性向量表示與交叉驗(yàn)證得到的向量表示結(jié)合,對(duì)答案進(jìn)行排序;
在答案完整性方面,考慮答案本身的一些統(tǒng)計(jì)特征:答案相對(duì)長(zhǎng)度、信息熵,并將其融合到融合排序模型中。
06
落地應(yīng)用示例
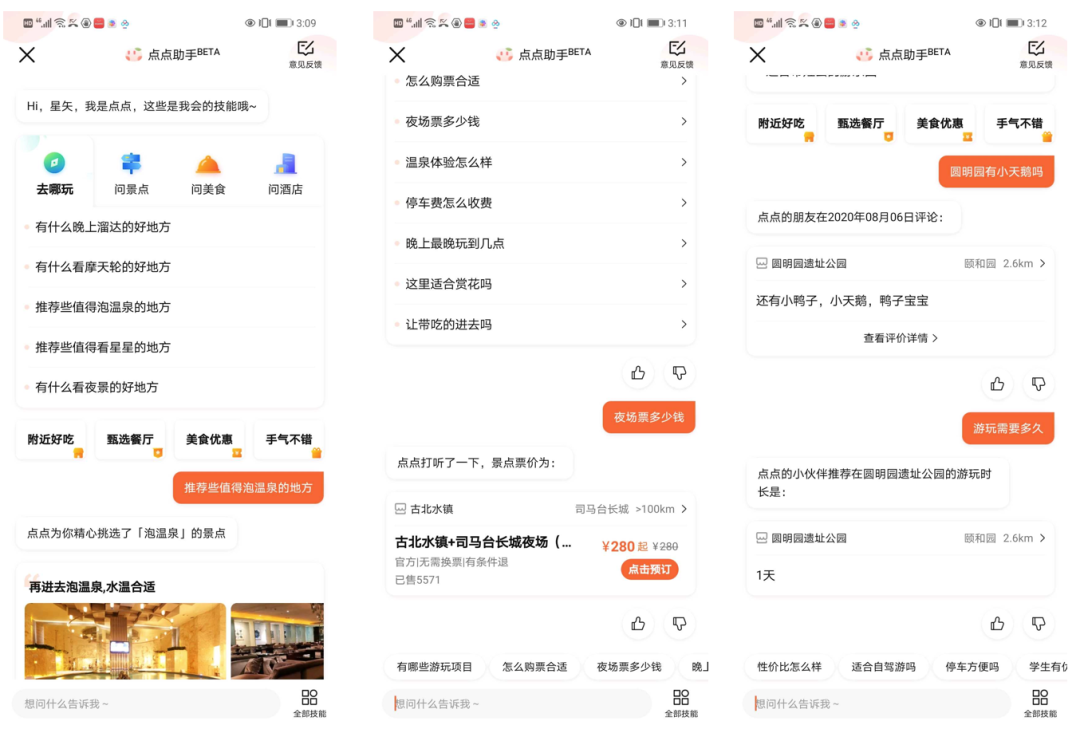
1. 問(wèn)答助手
在問(wèn)景點(diǎn)、問(wèn)酒店、問(wèn)商場(chǎng)等生活服務(wù)場(chǎng)景中,問(wèn)答助手可以回答用戶如"去哪玩"、"住哪家酒店"等相關(guān)問(wèn)題,輔助用戶行前決策。
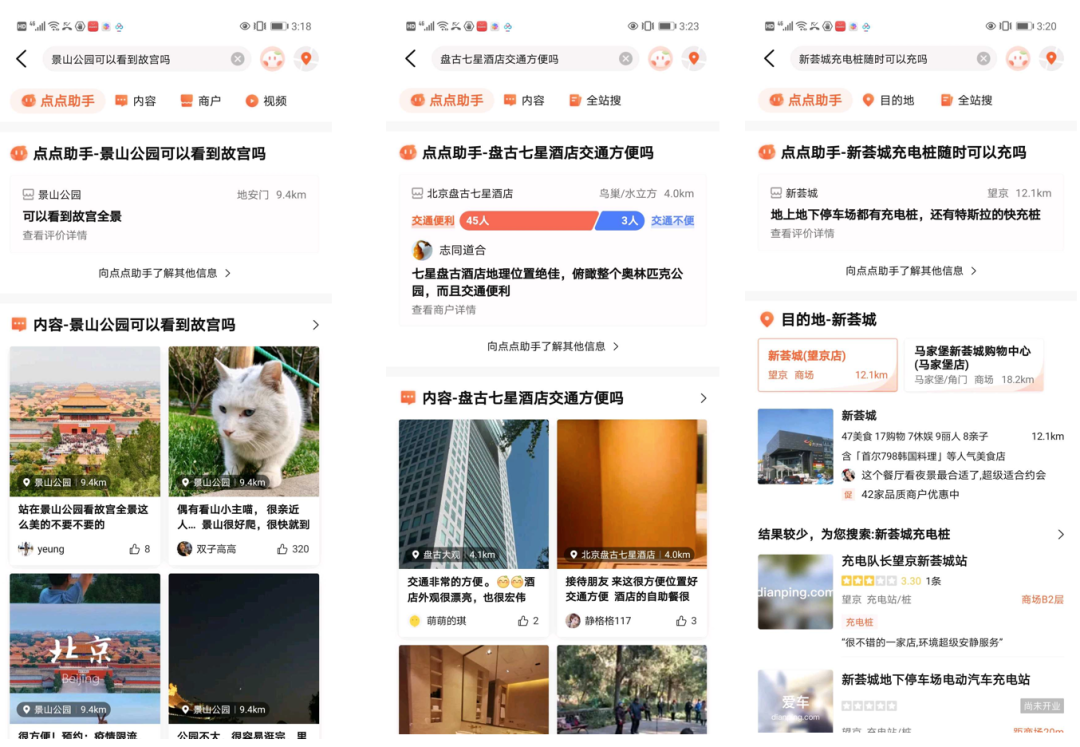
2. 問(wèn)答搜索
搜索仍然是當(dāng)前主要獲取信息的手段,問(wèn)答搜索解決搜索中用戶的問(wèn)答訴求,提升搜索質(zhì)量和用戶滿意度。
3. 景點(diǎn)門票購(gòu)票智能客服
在景點(diǎn)門口為無(wú)人售票帶來(lái)溫度,在景點(diǎn)門口通過(guò)掃碼美團(tuán)買票在線完成現(xiàn)場(chǎng)購(gòu)票,智能客服完成用戶相關(guān)問(wèn)題答疑,減少地推人員工作量。
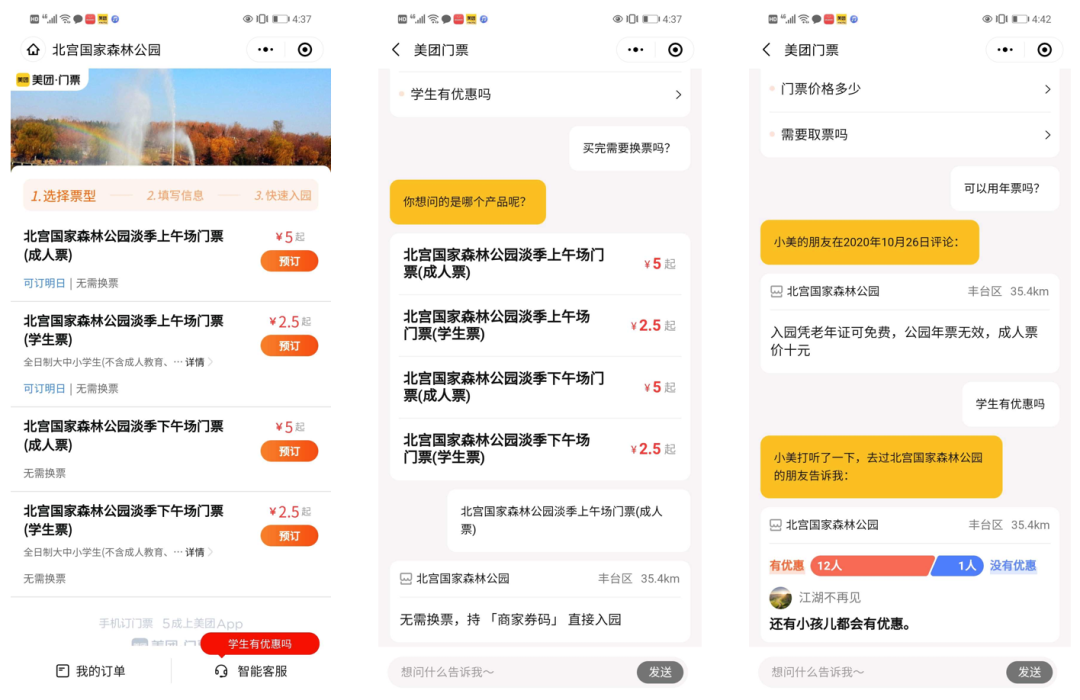
4. 問(wèn)大家
在問(wèn)大家模塊中,通常用戶新問(wèn)的問(wèn)題很難有其他用戶能及時(shí)回答,智能問(wèn)答可以有效整合商戶相關(guān)信息給出答案,及時(shí)解答用戶的疑問(wèn),提升用戶體驗(yàn)。
關(guān)于我們:
美團(tuán)是中國(guó)領(lǐng)先的生活服務(wù)電子商務(wù)平臺(tái),公司擁有美團(tuán)、大眾點(diǎn)評(píng)、美團(tuán)外賣等消費(fèi)者熟知的App,服務(wù)涵蓋餐飲、打車、共享單車、酒店旅游、電影、休閑娛樂(lè)等200多個(gè)品類。2018年6月開(kāi)始組建美團(tuán)對(duì)話平臺(tái)團(tuán)隊(duì),從自研美團(tuán)客服機(jī)器人開(kāi)始,一步步在業(yè)務(wù)中逐步沉淀對(duì)話核心技術(shù),2019年6月開(kāi)始以摩西對(duì)話平臺(tái)形式,進(jìn)一步支持美團(tuán)其他對(duì)話相關(guān)業(yè)務(wù)如員工服務(wù)、售前咨詢、商家服務(wù)等。隨著平臺(tái)建設(shè)的需要,2020年,我們開(kāi)始構(gòu)建各場(chǎng)景下的智能問(wèn)答能力,本文介紹的主要是該部分能力建設(shè)的階段性成果。
最后,感謝團(tuán)隊(duì)成員江南、思睿、冷佳等同學(xué)對(duì)本文內(nèi)容的貢獻(xiàn)。今天的分享就到這里,謝謝大家。
責(zé)任編輯:xj
原文標(biāo)題:美團(tuán)智能問(wèn)答技術(shù)探索與實(shí)踐
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
智能
+關(guān)注
關(guān)注
8文章
1709瀏覽量
117487 -
美團(tuán)
+關(guān)注
關(guān)注
0文章
125瀏覽量
10354 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
287瀏覽量
13346
原文標(biāo)題:美團(tuán)智能問(wèn)答技術(shù)探索與實(shí)踐
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Reddit測(cè)試人工智能問(wèn)答功能Reddit Answers
華為Mate系列新品攜手美團(tuán)外賣首發(fā)
探索設(shè)計(jì)稿自動(dòng)生成Flutter代碼的技術(shù)方案
單北斗智能終端:高精度定位技術(shù)在行業(yè)應(yīng)用中的革新實(shí)踐

AI智能化問(wèn)答:自然語(yǔ)言處理技術(shù)的重要應(yīng)用

華為云聯(lián)合中國(guó)信通院發(fā)布 智能化軟件開(kāi)發(fā)落地實(shí)踐指南
UWB定位系統(tǒng)在智能制造中的應(yīng)用實(shí)踐

開(kāi)啟全新AI時(shí)代 智能嵌入式系統(tǒng)快速發(fā)展——“第六屆國(guó)產(chǎn)嵌入式操作系統(tǒng)技術(shù)與產(chǎn)業(yè)發(fā)展論壇”圓滿結(jié)束
京東云智能編程助手與安全大模型雙雙獲獎(jiǎng)!

動(dòng)態(tài)線程池思想學(xué)習(xí)及實(shí)踐
【大語(yǔ)言模型:原理與工程實(shí)踐】核心技術(shù)綜述
消防智能疏散系統(tǒng)的技術(shù)原理與實(shí)踐應(yīng)用 中智盛安智能疏散指示
三星電子擬收購(gòu)大陸集團(tuán)汽車電子業(yè)務(wù)
美團(tuán)取得構(gòu)建高精地圖專利
喜訊!拓普聯(lián)科榮獲美團(tuán)充電寶“2023年度技術(shù)創(chuàng)新獎(jiǎng)”






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論