") Calibration: 一個工業(yè)價值極大,學(xué)術(shù)界卻鮮有研究的問題
Calibration: 一個工業(yè)價值極大,學(xué)術(shù)界卻鮮有研究的問題
盡管深度學(xué)習(xí)給工業(yè)界帶來了一波上線春天,但是總有很多比較難的業(yè)務(wù),模型反復(fù)迭代后準(zhǔn)確率依然達(dá)不到預(yù)期的產(chǎn)品標(biāo)準(zhǔn),難以滿足用戶期望。
以下為工業(yè)界常見討(si)論(b)場景:
R&D小哥哥一頓調(diào)參輸出,RoBERTa都用上了,終于將模型從80%準(zhǔn)確率提升到了90%,但是PM小姐姐說,“不行!咱們必須要達(dá)到95%準(zhǔn)確率才能上線!否則就是對用戶和產(chǎn)品逼格的傷害!”
怎么辦呢?
熟悉工業(yè)界上線套路的小伙伴馬上就能給出答案,那就是提高模型決策的閾值!PM小姐姐只是根據(jù)產(chǎn)品標(biāo)準(zhǔn)定義了模型準(zhǔn)確率(或者說精確率,precision),但是并不在乎召回率有多高(畢竟模型只要沒上線,就相當(dāng)于召回率為0)。
那么基于上面的思路:假如模型的softmax輸出可靠,比如二分類場景,模型softmax之后1類的輸出是0.92,能表征模型有92%的把握說這是個正例,并且模型的這個把握是精準(zhǔn)的,那么PM小姐姐說要達(dá)到95%準(zhǔn)確率,那我們就瘋狂提高模型的決策閾值就好了,這樣把那些不確定性高的樣本砍掉了,模型準(zhǔn)確率自然就上來了。
然而,神經(jīng)網(wǎng)絡(luò)并不一定這么靠譜,你看模型的測試集輸出的話,卻常常發(fā)現(xiàn)模型要么以99.999的概率輸出來判定正例,要么0.0001的概率輸出來判定負(fù)例,基本沒有樣本落在0.1~0.9區(qū)間內(nèi)。那么這時候上面的思路就失效了。
那么有沒有辦法讓模型的softmax輸出能真實的反映決策的置信度呢?這個問題,就被稱為Calibration問題(直譯是叫“校準(zhǔn)”)。
故事要從一篇發(fā)表于2017年的ICML頂會論文開始,目前這篇論文引用量1001。
論文標(biāo)題:
On Calibration of Modern Neural Networks
鏈接:
https://arxiv.org/pdf/1706.04599.pdf
神經(jīng)網(wǎng)絡(luò)的 overconfidence
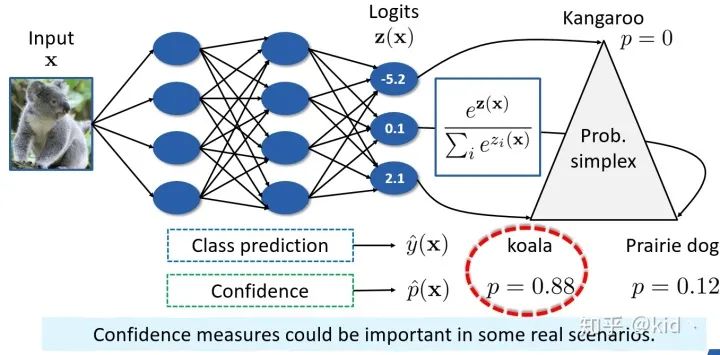
首先,讓咱們來思考一個普通圖像分類任務(wù)。對于一張“koala”的圖像,在經(jīng)過神經(jīng)網(wǎng)絡(luò)后會得到 logits 輸出 ,經(jīng)過 softmax 層后得到對各類別的預(yù)測的后驗概率,接著我們選擇概率最大的類別( koala)輸出為最后的預(yù)測類別。這里,最終的預(yù)測類別 ,其對應(yīng)的置信度為 。在大多情況下,我們只關(guān)心類別的預(yù)測 有多準(zhǔn),根本不 care 置信度是怎樣的。然而,在一些實際應(yīng)用場景下,置信度的度量也同樣重要。例如:
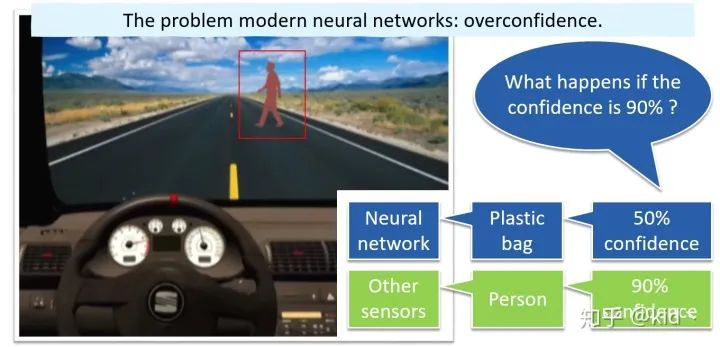
如上圖,對于自動駕駛中的目標(biāo)識別任務(wù),車輛的前方出現(xiàn)了一個人,神經(jīng)網(wǎng)絡(luò)會將其識別成塑料袋,此時輸出的置信度為50%(低于閾值),則可通過其它傳感器進(jìn)行二次的正確識別(識別為人)。但想想看,若神經(jīng)網(wǎng)絡(luò)對塑料袋預(yù)測的置信度為90%會怎樣?再例如:
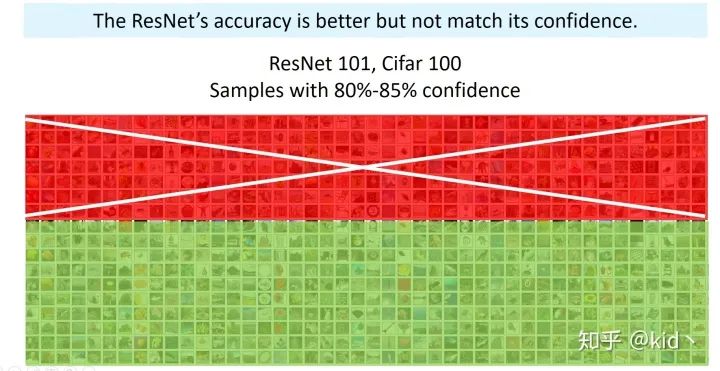
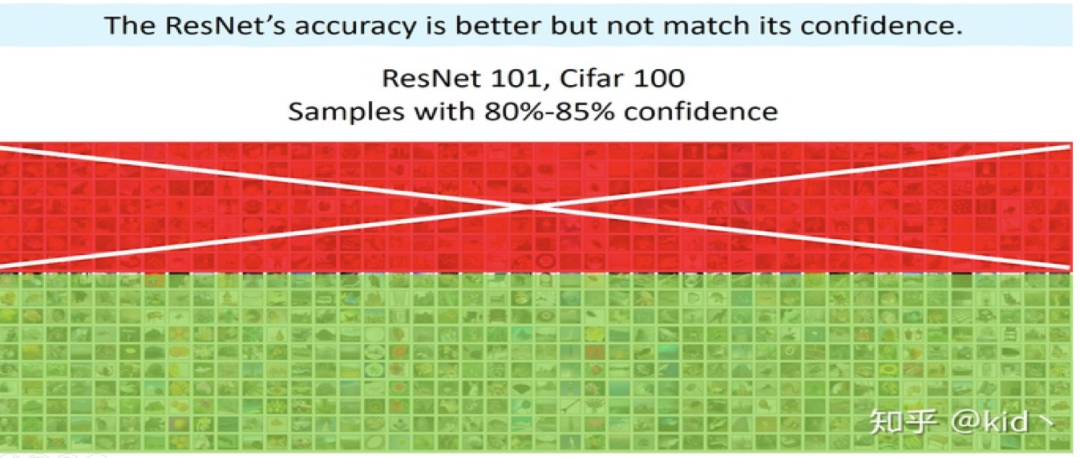
使用 Resnet 模型簡單的對一些圖片任務(wù)進(jìn)行訓(xùn)練,收斂后的模型對測試集的平均置信度高達(dá)80%-85%,然而只有將近70%的圖片能被正確分對(紅色代表分錯,綠色代表分對)。這意味著啥?訓(xùn)練好的模型好像有點盲目自信,即出現(xiàn)overconfidence現(xiàn)象,或者可以稱為模型的準(zhǔn)確率和置信度不匹配(miscalibration)。
預(yù)期校準(zhǔn)誤差(ECE)
直觀的來看,模型的準(zhǔn)確率應(yīng)當(dāng)和置信度相匹配。一個完美校準(zhǔn)的模型可定義成如下所示:
即,模型置信度 等于概率 的條件下模型的預(yù)測 為真實標(biāo)記 的概率同樣也為 。因此,本文提出一個新的度量方式叫做預(yù)期校準(zhǔn)誤差(Expected Calibrated Error, ECE)來描述模型學(xué)習(xí)的匹配程度:
很簡單,其實就是將前面那個完美校準(zhǔn)模型的等式寫成差的期望的形式。我們將期望進(jìn)一步展開可得到:
其中:
這里的 代表著一個個根據(jù)置信度區(qū)間劃分的一個個桶(用來裝樣本的),如下圖所示:

例如,我們將置信區(qū)間平均劃分成5份,然后將樣本按照其置信度挨個送到對應(yīng)的桶中,分別計算每個桶中的平均置信度和準(zhǔn)確率,兩者的差值(Gap)的期望就是所定義的ECE。
讀到這的讀者應(yīng)該能逐步體會本文想干一件啥事了。本文首先引出這樣一個問題,深度模型在學(xué)習(xí)過程中出現(xiàn)準(zhǔn)確率和置信度的嚴(yán)重不匹配問題,接著提出了一個合理的評價指標(biāo)來描述模型學(xué)習(xí)的匹配程度,所以接下來,它要提出方法來想辦法最小化期望校準(zhǔn)誤差(ECE)。
什么原因?qū)е律窠?jīng)網(wǎng)絡(luò)出現(xiàn)準(zhǔn)確率與置信度不匹配?
然而ECE是沒辦法直接最小化的,因此本文嘗試著做一些探索性的實驗來觀察啥因素會使得模型的 ECE 變大。本文分別從三個方面上去進(jìn)行實驗:
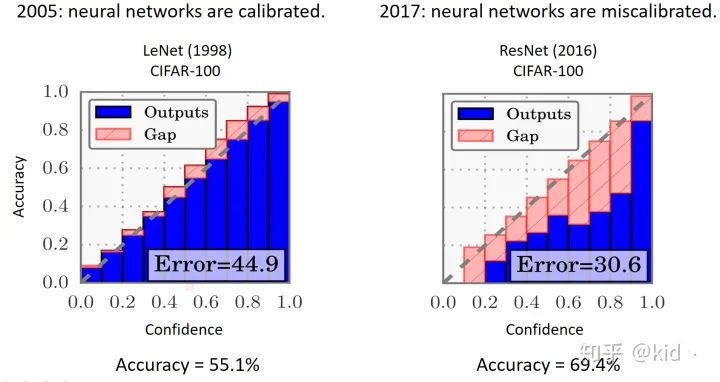
▲網(wǎng)絡(luò)復(fù)雜度對ECE的影響
網(wǎng)絡(luò)復(fù)雜度對 ECE 的影響:首先,作者使用兩個模型(LeNet和ResNet)分別對CIFAR-100數(shù)據(jù)集進(jìn)行了訓(xùn)練,準(zhǔn)確率分別為55.1%和69.4%,ResNet 在預(yù)測性能上完爆LeNet。然而,ResNet 置信度(右圖藍(lán)色+紅色部分)的分布和準(zhǔn)確率(右圖藍(lán)色部分)出現(xiàn)了嚴(yán)重的不匹配,導(dǎo)致二者的 Gap (紅色部分)非常大。注意完美校準(zhǔn)模型的分布應(yīng)當(dāng)是藍(lán)色部分剛好和對角線重合,且沒有紅色 Gap 部分。
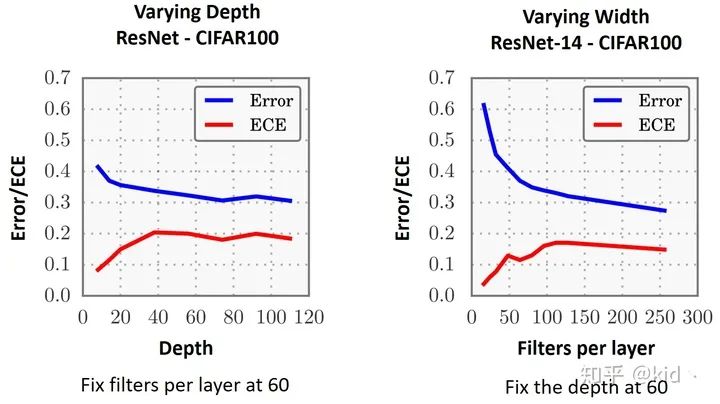
▲網(wǎng)絡(luò)的寬度和深度對ECE的影響
網(wǎng)絡(luò)寬度和深度對 ECE 的影響:在得知模型復(fù)雜度會影響模型的 ECE 后,作者緊接著做了網(wǎng)絡(luò)寬度和深度對模型 ECE 和錯誤率(Error)的影響。可以看到,在控制變量前提下,單方面的增加網(wǎng)絡(luò)的深度和寬度均會使得模型的 Error 降低,這是我們所期望的;然而,ECE也會同樣的隨著上升。換句話來說,一昧的增加模型復(fù)雜度能有效的提高模型的預(yù)測性能,但同樣帶來的問題是模型的 overconfidence 問題愈發(fā)嚴(yán)重。
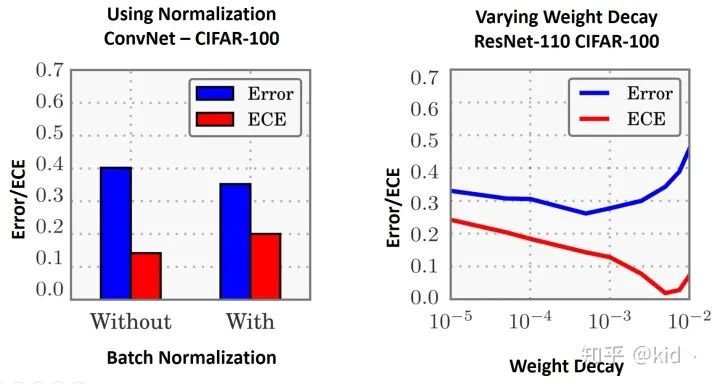
▲歸一化和權(quán)重衰減對ECE的影響
normalization 和 weight decay 對 ECE 的影響:接著的實驗也是我們?yōu)樘岣吣P托阅芙?jīng)常使用的 batch normalization 和 loss regularization。左圖:使用 batch normalization 會有效的提升模型的性能,但同時也會提升模型的 ECE。右圖:weight decay 通常用來調(diào)節(jié) L2 正則的權(quán)重衰減系數(shù),隨著其系數(shù)的增加相當(dāng)于更多的強調(diào)模型參數(shù) w 要盡可能的小,能有效的防止模型過擬合。該現(xiàn)象表明,模型越不過擬合,其ECE是越小的,也就是說模型越不會 overconfidence ;換句話說,模型對樣本的擬合程度和對樣本的置信度是息息相關(guān)的,擬合得越好,置信度越高,所以 ECE 越大。(個人理解,歡迎評論區(qū)指正~)
我們該如何對模型進(jìn)行校準(zhǔn)呢?
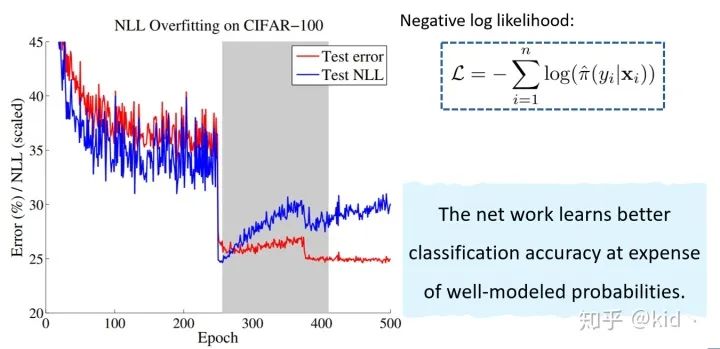
作者接下來又做了一個很有意思的實驗,在CIFAR-100上訓(xùn)練模型500個 epoch,其中在第250個 epoch 和第375個 epoch 下調(diào)節(jié)學(xué)習(xí)率,觀察測試集上的 test error 和 test NLL 的變化情況。Test NLL 的定義如圖中所示,它其實等價于測試集上的交叉熵。這個實驗啥意思呢?我調(diào)節(jié)了一下學(xué)習(xí)率后,測試性能得到了提升,但是測試集上的交叉熵卻出現(xiàn)了過擬合現(xiàn)象(出現(xiàn)了反常的上升現(xiàn)象)。有意思的點來了!有人肯定會 argue 不是說好本文研究的是overconfidence嘛?
即模型的置信度太高而準(zhǔn)確率過低,這里對 NLL overfitting 豈不是好事,因為負(fù)對數(shù)似然上升了等價于模型的置信度的降低了。注意:這里的是對正確類上的置信度,而前面的實驗是對預(yù)測類的置信度!其實認(rèn)真想想,是一個意思,前面之所以 confident 很高的樣本準(zhǔn)確率很低,正是因為其在正確類別上的置信度太低導(dǎo)致的!!(這部分卡了很久)
該結(jié)果可以表明,模型置信度和準(zhǔn)確率的不匹配很大可能的原因來自于模型對 NLL 的過擬合導(dǎo)致的。所以,咋辦呢?最小化 NLL 唄。
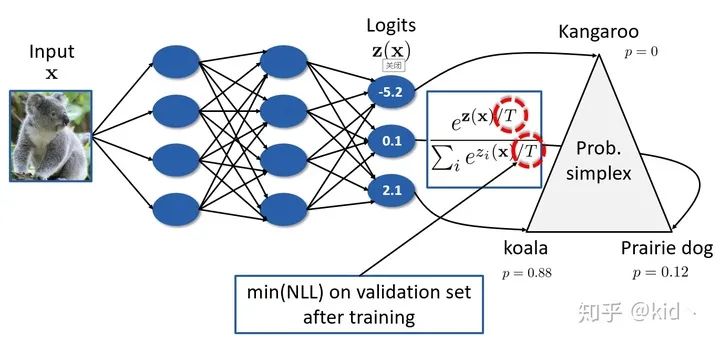
此時,本文提出在驗證集上對帶 temperature 參數(shù)的 softmax 函數(shù)進(jìn)行校準(zhǔn)。即我們訓(xùn)練完模型后,最小化 NLL 來學(xué)習(xí) temperature 參數(shù),注意到對該項的優(yōu)化并不會影響模型預(yù)測的準(zhǔn)確率,只會對模型的 confidence 進(jìn)行校準(zhǔn)。最終的結(jié)果是這樣的,詳細(xì)可參考論文。
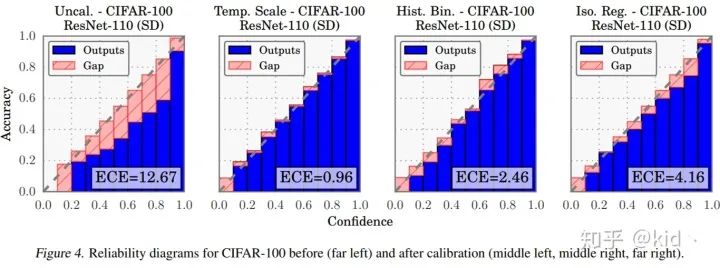
討論
上述得實驗結(jié)果我覺得對很多研究領(lǐng)域都是很有啟發(fā)意義的。
模型的置信度應(yīng)當(dāng)是和準(zhǔn)確率匹配的,這樣的模型我覺得才是有意義的,否則以很高置信度進(jìn)行很離譜的預(yù)測錯誤的模型會讓人感覺這個模型好像什么都會、又好像什么都不會。
ECE 的指標(biāo)是否能反應(yīng)樣本的一些性質(zhì),例如難易程度、是否為噪聲等。
該文章是間接的去優(yōu)化ECE的,能否有直接優(yōu)化的形式,或者主動學(xué)習(xí)里面能否考慮這一點來挑選樣本?
責(zé)任編輯:xj
原文標(biāo)題:Calibration: 一個工業(yè)價值極大,學(xué)術(shù)界卻鮮有研究的問題!
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4777瀏覽量
100974 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5511瀏覽量
121356
原文標(biāo)題:Calibration: 一個工業(yè)價值極大,學(xué)術(shù)界卻鮮有研究的問題!
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
以學(xué)術(shù)力量促進(jìn)開源技術(shù)新未來
夸克學(xué)術(shù)搜索受熱捧,成年輕人PC端AI應(yīng)用首選
為何無人機領(lǐng)域廣泛采用PX4作為核心控制平臺

存算一體技術(shù)的分類
天合光能亮相世界經(jīng)濟論壇“2024加速工業(yè)轉(zhuǎn)型和脫碳化”峰會
TensorFlow是什么?TensorFlow怎么用?
德克薩斯大學(xué)將創(chuàng)建一個學(xué)術(shù)界最強大的生成性人工智能研究中心
RISC-V在服務(wù)器方面應(yīng)用與發(fā)展前景
RISC-V在服務(wù)器方面的應(yīng)用與發(fā)展前景如何?剛畢業(yè)的學(xué)生才開始學(xué)來的及嗎?
中圖儀器與合肥工業(yè)大學(xué)共探3D顯微形貌測量技術(shù)
科技前沿 |?學(xué)術(shù)交融:中圖儀器與合肥工業(yè)大學(xué)共探3D顯微形貌測量技術(shù)

通過Kirkendall效應(yīng)來均勻二次顆粒中的應(yīng)力分布
端到端自動駕駛的基石在哪里?
Imec推出首款針對N2節(jié)點的設(shè)計探路工藝設(shè)計套件
端到端自動駕駛的基石到底是什么?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論