") 構(gòu)建圖模型的關(guān)鍵步驟
構(gòu)建圖模型的關(guān)鍵步驟
圖模型由節(jié)點(diǎn)和邊組成。節(jié)點(diǎn)表示實(shí)體或概念,邊則由屬性或關(guān)系構(gòu)成。
實(shí)體指的是具有可區(qū)別性且獨(dú)立存在的某種事物,如某一個(gè)人、某一個(gè)城市、某一種植物、某一種商品等,是圖模型中的最基本元素;
概念是對(duì)特征的組合而形成的知識(shí)單元,主要指集合、類別、對(duì)象類型、事物的種類,例如人物、地理等;
屬性主要指描述實(shí)體或概念的特征或特性,例如人員的國(guó)籍、生日等。
我們以“哲學(xué)家”為例設(shè)計(jì)圖模型,如圖5-13所示。
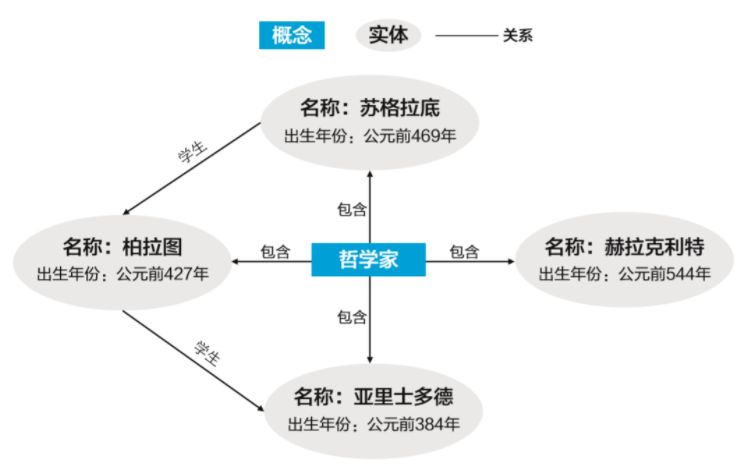
▲圖5-13 圖模型示例
圖模型構(gòu)建包含幾個(gè)關(guān)鍵步驟,如圖5-14所示。
▲圖5-14 企業(yè)圖模型構(gòu)建步驟
第一步:業(yè)務(wù)場(chǎng)景定義
業(yè)務(wù)場(chǎng)景決定信息涵蓋范圍,以及信息顆粒度的表示。
以支撐業(yè)務(wù)連續(xù)性為例,因?yàn)椴豢煽沽Φ挠绊懀糠謪^(qū)域的供應(yīng)商工廠無法正常生產(chǎn)和發(fā)貨,涉及的信息包括供應(yīng)商的信息、產(chǎn)能、元器件及內(nèi)部物料、合同和客戶信息,要求能夠根據(jù)用戶輸入的當(dāng)前物料儲(chǔ)備和合同狀態(tài),獲取影響內(nèi)部物料、產(chǎn)品、合同交付和客戶的清單和范圍。
這種應(yīng)用涉及對(duì)產(chǎn)品目錄和配置的解讀,需要對(duì)收集的信息進(jìn)行最小采購(gòu)器件的抽取。
信息顆粒度在圖模型建設(shè)中是個(gè)不可忽視的問題,根據(jù)應(yīng)用場(chǎng)景決定信息顆粒度以及圖模型的精確性與有效性。比如手機(jī),有品牌、型號(hào)、批次,直至手機(jī)整機(jī)。同樣的信息范圍,顆粒度越細(xì),圖模型應(yīng)用越廣泛,關(guān)系越豐富,但冗余越多,知識(shí)消費(fèi)越低效。信息顆粒度的原則是“能滿足業(yè)務(wù)應(yīng)用的最粗顆粒度”。
第二步:信息收集
信息的選取要考慮兩個(gè)方面的內(nèi)容。
與應(yīng)用場(chǎng)景直接相關(guān)的信息。例如,判斷不可抗力供應(yīng)中斷影響的范圍,直接相關(guān)的信息有物料信息、產(chǎn)品配置、合同信息等。
與應(yīng)用場(chǎng)景間接相關(guān),但可輔助理解問題的信息。這包括企業(yè)信息、專業(yè)領(lǐng)域信息、行業(yè)信息以及開放域信息。
第三步:圖建模
相同的數(shù)據(jù)可以有若干種模式的定義,良好的模式可以減少數(shù)據(jù)冗余,提高實(shí)體識(shí)別的準(zhǔn)確率,在建模的過程中,要結(jié)合數(shù)據(jù)特點(diǎn)與應(yīng)用場(chǎng)景來完成。同樣的數(shù)據(jù)從不同的視角可以得出不同的圖模型。
第四步:實(shí)體、概念、屬性、關(guān)系的標(biāo)注
企業(yè)圖模型中涉及的實(shí)體和概念可分為三類:
公共類,如人名、機(jī)構(gòu)名、地名、公司名、時(shí)間等;
企業(yè)類,如業(yè)務(wù)術(shù)語、企業(yè)部門等;
行業(yè)類,如金融行業(yè)、通信行業(yè)等。
第五步:實(shí)體和概念的識(shí)別
企業(yè)圖模型中實(shí)體、概念的識(shí)別可將業(yè)務(wù)輸入與數(shù)據(jù)資產(chǎn)中已有的信息作為種子,運(yùn)用命名實(shí)體識(shí)別(NER)的方法擴(kuò)展出新實(shí)體概念,經(jīng)業(yè)務(wù)確認(rèn)后,列入實(shí)體、概念庫(kù)。
第六步:屬性識(shí)別與關(guān)系識(shí)別
企業(yè)圖模型中的屬性與關(guān)系一般是根據(jù)業(yè)務(wù)知識(shí)在模式層設(shè)計(jì)時(shí)定義,屬性與關(guān)系相對(duì)穩(wěn)定,其擴(kuò)展場(chǎng)景不是很多。
企業(yè)圖模型的存儲(chǔ)技術(shù)要綜合考慮應(yīng)用場(chǎng)景、圖模型中節(jié)點(diǎn)和聯(lián)接的數(shù)量、邏輯的復(fù)雜度、屬性的復(fù)雜度,以及性能要求。一般建議采用混合存儲(chǔ)方式,用圖數(shù)據(jù)庫(kù)存儲(chǔ)關(guān)系,關(guān)系型數(shù)據(jù)庫(kù)或鍵值對(duì)存儲(chǔ)屬性。偏重邏輯推理的應(yīng)用場(chǎng)景用RDF的存儲(chǔ)方式,偏重圖計(jì)算的應(yīng)用場(chǎng)景選擇屬性圖的存儲(chǔ)方式。發(fā)揮兩類數(shù)據(jù)存儲(chǔ)和讀寫的各自優(yōu)勢(shì)。
知識(shí)計(jì)算主要是根據(jù)圖譜提供的信息得到更多隱含的知識(shí),如通過模式層以及規(guī)則推理技術(shù)可以獲取數(shù)據(jù)中存在的隱含信息。知識(shí)計(jì)算涉及三大關(guān)鍵技術(shù):圖挖掘計(jì)算、基于本體的推理、基于規(guī)則的推理。圖挖掘計(jì)算是基于圖論的相關(guān)算法,實(shí)現(xiàn)對(duì)圖譜的探索和挖掘。圖挖掘計(jì)算主要分為如下6類。
圖遍歷:知識(shí)圖譜構(gòu)建完之后可以理解為是一張很大的圖,可以去查詢和遍歷這個(gè)圖,要根據(jù)圖的特點(diǎn)和應(yīng)用場(chǎng)景進(jìn)行遍歷。
圖里面經(jīng)典的算法,如最短路徑。
路徑的探尋,即根據(jù)給定兩個(gè)實(shí)體或多個(gè)實(shí)體去發(fā)現(xiàn)它們之間的關(guān)系。
權(quán)威節(jié)點(diǎn)的分析,這在社交網(wǎng)絡(luò)分析中使用較多。
族群分析。
相似節(jié)點(diǎn)的發(fā)現(xiàn)。
圖挖掘計(jì)算如圖5-15所示。
▲圖5-15 圖模型示例
圖挖掘計(jì)算在當(dāng)前的應(yīng)用場(chǎng)景中,基于業(yè)務(wù)連續(xù)性,通過查詢遍歷圖模型,識(shí)別影響節(jié)點(diǎn)和影響范圍,基于最短路徑,輔助決策物流線路,在企業(yè)中的應(yīng)用較為普遍。
圖模型在企業(yè)中的價(jià)值,很大程度上取決于企業(yè)基于對(duì)象節(jié)點(diǎn)可以構(gòu)建多完善的關(guān)系,這個(gè)關(guān)系的構(gòu)建是一個(gè)逐步完善的過程,基于業(yè)務(wù)場(chǎng)景不斷補(bǔ)充和完善關(guān)系,這就是圖模型的優(yōu)勢(shì)。
當(dāng)形成一個(gè)足夠完善的企業(yè)級(jí)圖模型后,領(lǐng)域分段的業(yè)務(wù)場(chǎng)景應(yīng)用只需要裁剪部分節(jié)點(diǎn)和關(guān)系,就可以滿足業(yè)務(wù)的需求,達(dá)到快速響應(yīng)業(yè)務(wù)需求、降低開發(fā)成本的目的。
責(zé)任編輯人:CC
-
節(jié)點(diǎn)
+關(guān)注
關(guān)注
0文章
220瀏覽量
24444
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
電動(dòng)工具EMC測(cè)試整改:確保電磁兼容性的關(guān)鍵步驟

深圳南柯電子 EMC測(cè)試整改:確保產(chǎn)品電磁兼容性的關(guān)鍵步驟

建設(shè)智慧醫(yī)院的關(guān)鍵步驟都有哪幾點(diǎn)
光伏行業(yè)數(shù)字化轉(zhuǎn)型的關(guān)鍵步驟有哪些?

組合邏輯電路設(shè)計(jì)的關(guān)鍵步驟是什么
在PyTorch中搭建一個(gè)最簡(jiǎn)單的模型
利用TensorFlow實(shí)現(xiàn)基于深度神經(jīng)網(wǎng)絡(luò)的文本分類模型
解讀PyTorch模型訓(xùn)練過程
深圳比創(chuàng)達(dá)|EMC與EMI測(cè)試整改:確保設(shè)備電磁兼容性的關(guān)鍵步驟

EMI測(cè)試整改:確保電子設(shè)備電磁兼容性的關(guān)鍵步驟

主軸維修:關(guān)鍵步驟和要點(diǎn)有哪些?|深圳恒興隆機(jī)電.
交換芯片的構(gòu)建方式
MES系統(tǒng)實(shí)施的幾大關(guān)鍵步驟
配網(wǎng)故障定位:關(guān)鍵步驟與解決方案

邪惡PLC攻擊技術(shù)的關(guān)鍵步驟





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論