 如何搭建NLP經典模型(含代碼)
如何搭建NLP經典模型(含代碼)
之前整理過齋藤康毅的深度學習神作《深度學習入門:基于Python的理論與實現》,對小白非常友好,它沒有用任何的現成框架(比如pyTorch、tensorFlow等等),而是直接用python自帶的庫手把手教你,從如何實現梯度下降開始到手磕一個CNN經典網絡,讓你不再對深度學習框架的內部機制感到神秘。
短短幾年,這位大佬再度出了“續集”—《深度學習進階:自然語言處理》[1]!(可以說是NLP入門必讀的經典著作了!)
小齋這次的寫作風格和前作一樣,都是手把手教你從實現詞向量開始,像搭積木一樣,再到如何實現經典網絡NLP屆的界的經典網絡RNN、LSTM、seq2seq和Attention等NLP中重要的深度學習技術。
(太感人了,這次終于要搞懂詞向量究竟是個什么鬼了!(逃
凡我不能創造的,我就不能理解。
— 理查德·費曼(致敬費曼)
話不多說,這次我不再整理的和上個系列一樣那么詳細(繁冗)了(個人覺得沒必要,那樣整理還不如直接看書來的直接痛快。所以這一次我會摘取基礎又重要的部分,如果你想再詳細深究下去,乖,去參考原書噢!
本書用到的庫:
Numpy
Matplotlib
(真的是只用了這兩個基本庫!(強
如果要用GPU加速運算的話,再加一個CuPy庫。
作者強調,自己動手的經驗、花時間思考的經驗,都是無法復制的。(所以,聽話,要自己嘗試敲1敲代碼噢!
本書第一章為上一本書神經網絡的復習,咱直接跳到第二章 從詞向量開始
正文開始
目錄
什么是自然語言處理?
同義詞詞典
基于計數的方法
基于計數的方法改進
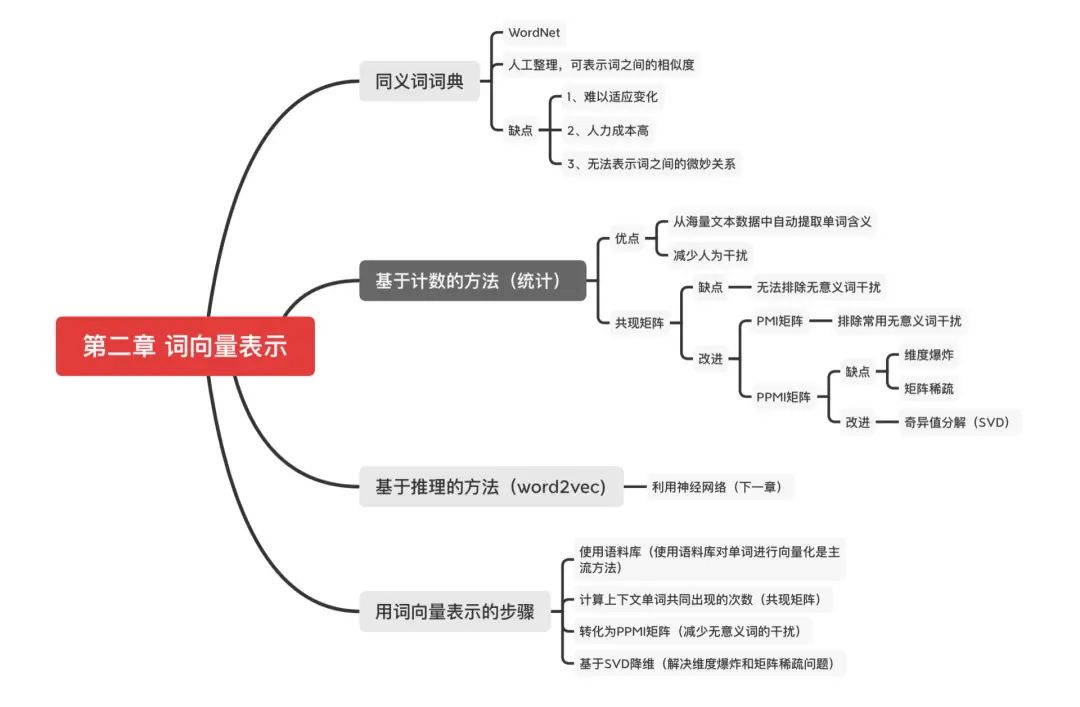
必做練習
-
語料庫的預處理。實現分詞(將文本分割成單詞,以單詞為最小單元輸入給模型)
-
單詞ID化(將單詞用ID來表示,相當于給每一個單詞編個代號,和我們學生編個學號一個意思,方便定位和管理唄)
-
利用共現矩陣表示文本的詞向量。
(這些練習會在后續搭建模型的時候用得到噢!相當于我們先造積木,之后搭網絡就有素材啦!本章的詞向量表示也就是對文本進行預處理的準備工作!)
注意:全文的講解都是以
(存在一個問題 —> 找到解決辦法 —> 新的解決辦法又有什么問題 —> 又找到解決辦法 )的思路一步一步引出各種概念和解決方案的。
我們的學習過程也是如此,市面上突然出現的各種模型也是如此,了解它解決了什么問題也就知道亂七八糟的各種模型為什么會出現了。
什么是自然語言處理?
-
自然語言:就是我們平常使用的語言,如漢語、英語;
-
自然語言處理:就是讓機器理解人類的語言,理解了人類語言才能對我們的語言進行進一步解讀和分析!(比如對人類的情感進行分析、對文本進行分類、能夠實現人機對話等等)
在沒有深度學習的時候,專家們是這樣進行詞向量的表示的:
同義詞詞典
最著名的同義詞詞典當屬WordNet [2]啦。WordNet等同義詞詞典中對大量單詞人工的定義了同義詞和層級結構關系等。
同義詞詞典存在的問題
-
難以順應時代的變化。語言是活的,新詞會不斷出現。
-
人力成本高,WordNet收錄了超過20W個單詞。
-
無法表示單詞的微妙差異。即使是含義相近的單詞,也有細微的差別。比如,vintage 和retro(類似復古的意思)雖然表示相同的含義,但是用法不同,而這種細微的差別在同義詞詞典中是無法表示出來的(讓人來解釋是相當困難的)。
Marty:“This is heavy (棘手).”
Dr. Brown:“In the future, things are so heavy (重)?”
— 電影《回到未來》
在電影《回到未來》中,有這樣一個場景:從1985 年穿越回來的馬蒂和生活在1955年的的博士的對話中,對“heavy”的含義有不同的理解。如果要處理這樣的單詞變化,就需要人工不停地更新同義詞詞典。
基于計數的方法(基于統計)
目標:從海量文本數據中自動提取單詞含義,減少人為干擾。
-
語料庫(corpus):就是我們輸入模型的大量文本,比如句子、文章等等。
這里將用一句話作為語料庫來闡述接下來的所有概念。
> text = 'you say goodbye and I say hello.'
語料庫的預處理
1、進行句子的分詞,并標記每個單詞的ID。(就像給每個學生編上學號ID一樣,方便后續指定某一個學生呀!)
>>>text=text.lower()//將所有單詞轉化為小寫>>>text=text.replace('.','.')//使句號其和前一個單詞分開>>>text'yousaygoodbyeandisayhello.'>>>words=text.split('')//切分句子>>>words['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.'] //由八個詞組成的數組
首先,使用lower()方法將所有單詞轉化為小寫,這樣可以將句子開頭的單詞也作為常規單詞處理。然后,將空格作為分隔符,通過split(' ')切分句子。考慮到句子結尾處的句號(.),我們先在句號前插人一個空格(即用 ' .'替換'.'),再進行分詞。
2、我們進一步給單詞標上 ID,以便使用單詞 ID 列表,方便為后續對每個單詞進行操作。
將單詞列表轉化為單詞 ID 列表,然后再將其轉化為 NumPy 數組。
word_to_id={}//將單詞轉化為單詞IDid_to_word={}//將單詞ID轉化為單詞(鍵是單詞ID,值是單詞)forwordinwords:ifwordnotinword_to_id://如果單詞不在word_to_id中,則分別向word_to_id和id_to_word添加新ID和單詞new_id=len(word_to_id)word_to_id[word]=new_idid_to_word[new_id] = wordcorpus = np.array([word_to_id[w] for w in words])
如果單詞不在 word_to_id 中,則分別向 word_to_id 和id_to_word 添加新 ID 和單詞
如下為創建好了單詞 ID 和單詞的對應表
>id_to_word{0:'you',1:'say',2:'goodbye',3:'and',4:'i',5:'hello',6:'.'}>word_to_id{'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5, '.': 6}
最后,我們將單詞列表轉化為單詞 ID 列表,然后再將其轉化為 NumPy 數組。
>corpusarray([0, 1, 2, 3, 4, 1, 5, 6])
將第一步和第二步封裝為一個preprocess() 函數,使用這個函數,可以按如下方式對語料庫進行預處理。( 代碼在common/util.py)
輸入要處理的語料庫text,輸出corpus, word_to_id, id_to_word
> text = 'You say goodbye and I say hello.'>corpus,word_to_id,id_to_word=preprocess(text)
corpus 是單詞ID 列表,word_to_id 是單詞到單詞 ID 的字典,id_to_word 是單詞 ID 到單詞的字典。
語料庫的預處理已完成。這里準備的 corpus、word_to_id 和 id_to_word 這 3 個變量名在本書接下來的很多地方都會用到。
接下來的目標就是使用語料庫提取單詞含義,這里先使用基于計數的方法,也就是基于統計的方法,能夠得到詞向量!(也就是將單詞表示為向量)
分布式假說(distributional hypothesis)
-
分布式假說(distributional hypothesis):某個單詞的含義由它周圍的單詞形成。(某個人存在的價值由它的社會屬性構成。—我瞎說的)
單詞本身沒有含義,單詞含義由它所在的上下文(語境)形成。
比如“I drink beer.” “We drink wine.” , drink 的附近常有飲料出現。
另外,從“I guzzle beer.” “We guzzle wine.”可知,guzzle 和 drink 所在的語境相似。進而我們可以推測出guzzle 和 drink 是近義詞(guzzle 是“大口喝”的意思) 。
基于這一假說,我們就可以通過單詞的上下文來表示該單詞。如圖,左側和右側的 2 個單詞就是上下文。

這里的窗口大小可以控制你需要關心多少單詞的上下文。顯而易見,關心的上下文單詞數越多,單詞的含義越準確,但是所需要的存儲量就越大,看你自己的取舍咯!這里簡單起見,窗口大小為1。
如何基于分布式假設使用向量表示單詞,最直截了當的實現方法是對周圍單詞的數量進行計數。
共現矩陣(co-occurrence matrix)
-
共現矩陣(co-occurrence matrix):用上下文共同出現的單詞次數作為該單詞的向量。即若兩個單詞挨著出現一次,次數加一。
上面已經處理好語料庫了,接下來構建共現矩陣,也就是計算每個單詞的上下文所包含的單詞的頻數。在這個例子中,我們將窗口大小設為 1,從單詞 ID 為 0 的 you 開始。
單詞 you 的上下文僅有 say 這個單詞,如下圖所示。

所以單詞you可表示為:
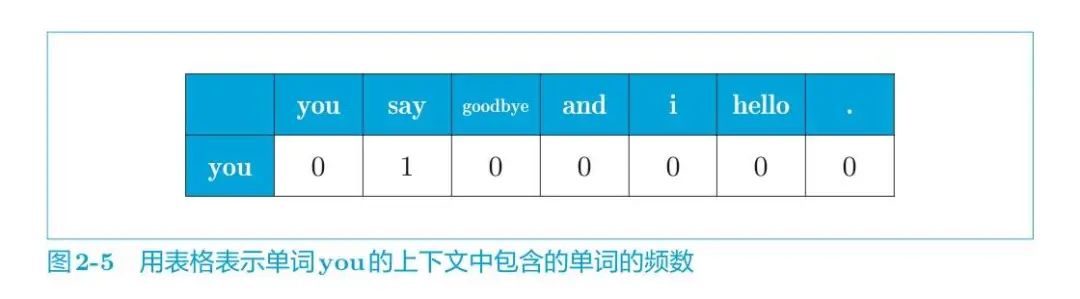
即可以用向量 [0, 1, 0, 0, 0, 0, 0] 表示單詞 you。其他單詞也是重復如此操作。

于是得到了共現矩陣:
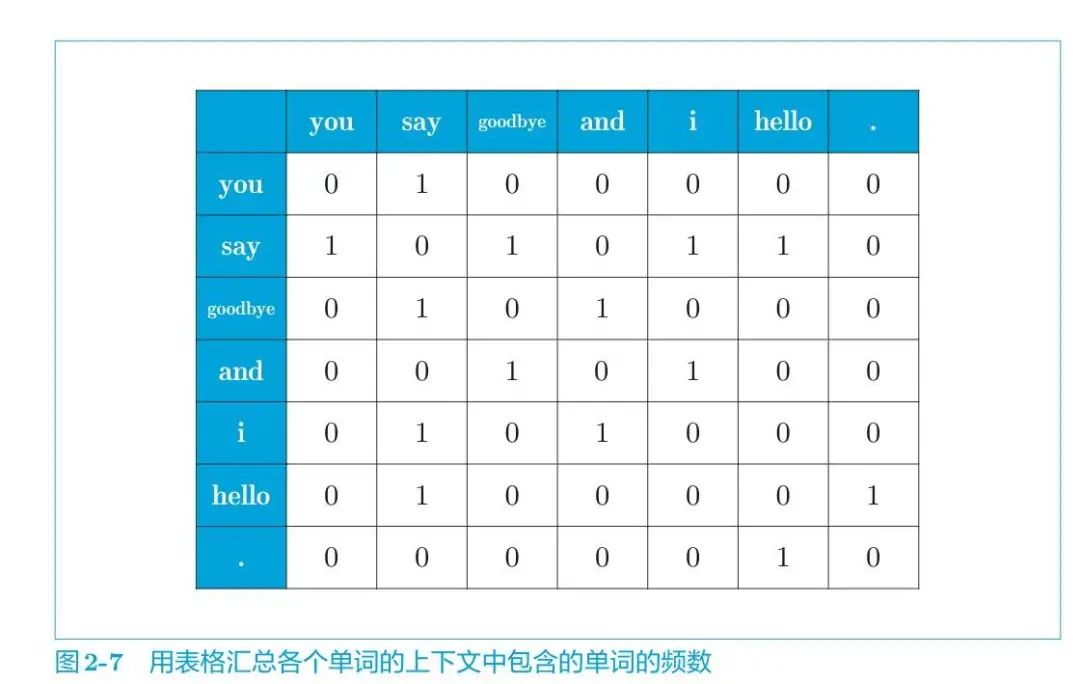
接下來,我們來實際創建一下上面的共現矩陣。
將圖 2-7 的結果按原樣手動輸入。
C=np.array([[],[],[],[],[],[],[], ], dtype=np.int32)
這就是共現矩陣。使用這個共現矩陣,可以獲得各個單詞的向量,如下所示。
print(C[0])#單詞ID為0的向量#[0100000]print(C[4])#單詞ID為4的向量#[0101000]print(C[word_to_id['goodbye']])#goodbye的向量# [0 1 0 1 0 0 0]
我們通過共現矩陣成功地用向量表示了單詞。但手動輸入共現矩陣太麻煩,這一操作顯然可以自動化。下面,我們來實現一個能直接從語料庫生成共現矩陣的函數。
通過函數create_co_matrix()能直接從語料庫生成共現矩陣。(代碼實現在common/util.py)
其中參數 corpus 是單詞 ID 列表,參數 vocab_ size 是詞匯個數,window_size 是窗口大小。
defcreate_co_matrix(corpus,vocab_size,window_size=1):corpus_size=len(corpus)co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32)foridx,word_idinenumerate(corpus):foriinrange(1,window_size+1):left_idx=idx-iright_idx=idx+iifleft_idx>=0:left_word_id=corpus[left_idx]co_matrix[word_id,left_word_id]+=1ifright_idxright_word_id=corpus[right_idx]co_matrix[word_id,right_word_id]+=1return co_matrix
首先,用元素為 0 的二維數組對 co_matrix 進行初始化。然后,針對語料庫中的每一個單詞,計算它的窗口中包含的單詞。同時,檢查窗口內的單詞是否超出了語料庫的左端和右端。
這樣一來,無論語料庫多大,都可以自動生成共現矩陣。之后,我們都將使用這個函數生成共現矩陣。
到這里我們終于第一次成功的用向量表示單詞啦!將正式邁入文本詞向量表示的道路!
寫到這發現篇幅太長了,為了能有更好的學習體驗,接下來共現矩陣存在的問題以及改進方式就下一篇再見啦!
責任編輯:xj
原文標題:小白跟學系列之手把手搭建NLP經典模型(含代碼)
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
模型
+關注
關注
1文章
3286瀏覽量
49010 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13603 -
nlp
+關注
關注
1文章
489瀏覽量
22066
原文標題:小白跟學系列之手把手搭建NLP經典模型(含代碼)
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
超級干貨!本地搭建代碼托管平臺Gitea






 工商網監
工商網監
評論