") 2020 年十大機器學(xué)習(xí)研究進(jìn)展匯總
2020 年十大機器學(xué)習(xí)研究進(jìn)展匯總
去年有哪些機器學(xué)習(xí)重要進(jìn)展是你必須關(guān)注的?聽聽 DeepMind 研究科學(xué)家怎么說。
2020 年因為新冠疫情,很多人不得不在家工作和學(xué)習(xí),大量人工智能學(xué)術(shù)會議也轉(zhuǎn)為線上。不過在去年我們?nèi)匀豢吹搅撕芏?AI 技術(shù)領(lǐng)域的進(jìn)展。DeepMind 研究科學(xué)家 Sebastian Ruder 近日幫我們對去年的機器學(xué)習(xí)社區(qū)進(jìn)行了一番總結(jié)。
首先你必須了解的是:這些重點的選擇基于作者個人熟悉的領(lǐng)域,所選主題偏向于表示學(xué)習(xí)、遷移學(xué)習(xí),面向自然語言處理(NLP)。如果讀者有不同的見解,可以留下自己的評論。
Sebastian Ruder 列出的 2020 年十大機器學(xué)習(xí)研究進(jìn)展是:
大模型和高效模型
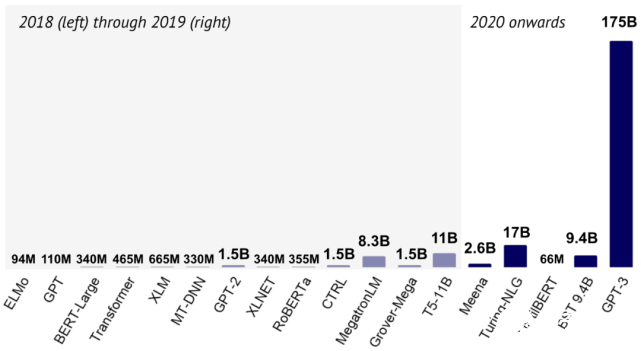
語言模型從 2018 年到 2020 年的發(fā)展(圖片來自 State of AI Report 2020)。
2020 年發(fā)生了什么?
在過去的一年,我們看到了很多前所未有的巨型語言和語音模型,如 Meena(Adiwardana et al., 2020)、Turing-NLG、BST(Roller et al., 2020)和GPT-3(Brown et al., 2020)。與此同時,研究人員們也早已意識到訓(xùn)練這樣的模型要耗費過量的能源(Strubell et al., 2019),并轉(zhuǎn)而探索體量更小、效果仍然不錯的模型:最近的一些進(jìn)展方向來自于裁剪((Sajjad et al., 2020、Sanh et al., 2020、)、量化(Fan et al., 2020b)、蒸餾(Sanh et al., 2019、Sun et al., 2020)和壓縮(Xu et al., 2020)。
另有一些研究關(guān)注如何讓 Transformer 架構(gòu)本身變得更高效。其中的模型包括 Performer(Choromanski et al., 2020)和 Big Bird(Zaheer et al., 2020),如本文第一張圖所示。該圖顯示了在Long Range Arena 基準(zhǔn)測試中不同模型的性能(y 軸)、速度(x 軸)和內(nèi)存占用量(圓圈大小)(Tay et al., 2020)。
像 experiment-impact-tracker 這樣的工具(Henderson et al., 2020)已讓我們對于模型的能耗效率更為了解。其研究者還推動了評估效率的競賽和基準(zhǔn)測試,如 EMNLP 2020 上的 SustaiNLP 研討會,NeurIPS 2020 上的 Efficient QA 競賽和 HULK(Zhou et al., 2020。
模型體量的擴大可以讓我們不斷突破深度學(xué)習(xí)能力的極限。而為了在現(xiàn)實世界部署它們,模型必須高效。這兩個方向也是相輔相成的:壓縮大號模型可以兼顧效率和性能(Li et al., 2020),而效率更高的方法也可以推動更強、更大的模型(Clark et al., 2020)。
鑒于對效率和可用性的考慮,我認(rèn)為未來研究的重點不僅僅是模型的表現(xiàn)和參數(shù)數(shù)量,也會有能耗效率。這會有助于人們對于新方法進(jìn)行更全面的評估,從而縮小機器學(xué)習(xí)研究與實際應(yīng)用之間的差距。
檢索增強
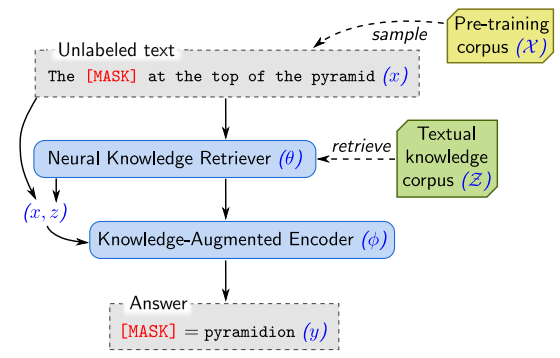
使用 REALM 進(jìn)行無監(jiān)督預(yù)訓(xùn)練,檢索器和編碼器經(jīng)過了聯(lián)合預(yù)訓(xùn)練。
大規(guī)模模型可以利用預(yù)訓(xùn)練數(shù)據(jù)學(xué)習(xí)出令人驚訝的全局知識,這使得它們可以重建事實(Jiang et al., 2020)并在不接觸外界上下文的情況下回答問題(Roberts et al., 2020)。然而,把這些知識隱式地存儲在模型參數(shù)中效率很低,需要極大的模型來存儲足量的信息。與之不同的是,最近的一些方法選擇同時訓(xùn)練檢索模型和大規(guī)模語言模型,在知識密集型 NLP 任務(wù)上獲得了強大的結(jié)果,如開放域問答(Guu et al., 2020、Lewis et al., 2020)和語言建模(Khandelwal et al., 2020)。
這些方法的主要優(yōu)點是將檢索直接集成到語言模型的預(yù)訓(xùn)練中,從而讓語言模型效率更高,專注于學(xué)習(xí)自然語言理解中更具挑戰(zhàn)性的概念。因此在 NeurIPS 2020 EfficientQA 競賽中的最佳系統(tǒng)依賴于檢索(Min et al., 2020)。
檢索是很多生成任務(wù)的標(biāo)準(zhǔn)方法,例如文本摘要和對話此前已大量被摘要生成所替代 (Allahyari et al., 2017)。檢索增強生成可以將兩個方面的優(yōu)點結(jié)合在一起:檢索段的事實正確性、真實性以及所生成文本的相關(guān)性和構(gòu)成。
檢索增強生成對于處理過去困擾生成神經(jīng)模型的失敗案例尤其有用,尤其是在處理幻覺(hallucination)上(Nie et al., 2019)。它也可以通過直接提供預(yù)測依據(jù)來幫助使系統(tǒng)更易于解釋。
少樣本學(xué)習(xí)

Prompt-based 微調(diào)使用模板化的提示和演示(Gao et al., 2020)。
在過去幾年中,由于預(yù)訓(xùn)練的進(jìn)步,給定任務(wù)的訓(xùn)練樣本數(shù)量持續(xù)減少(Peters et al., 2018、Howard et al., 2018)。我們現(xiàn)在正處在可以使用數(shù)十個示例來完成給定任務(wù)的階段(Bansal et al., 2020)。自然地,人們想到了少樣本學(xué)習(xí)變革語言建模的范式,其中最為突出的例子就是 GPT-3 中上下文學(xué)習(xí)的方法。它可以根據(jù)一些輸入 - 輸出對和一個提示進(jìn)行預(yù)測。無需進(jìn)行梯度更新。
不過這種方式仍然有其限制:它需要一個巨大的模型——模型需要依賴現(xiàn)有的知識——這個模型能夠使用的知識量受到其上下文窗口的限制,同時提示需要手工完成。
最近的一些工作試圖通過使用小模型,集成微調(diào)和自動生成自然語言提示(Schick and Schütze, 2020、Gao et al., 2020、Shin et al., 2020)讓少樣本學(xué)習(xí)變得更加有效。這些研究與可控神經(jīng)文本生成的更廣泛領(lǐng)域緊密相關(guān),后者試圖廣泛地利用預(yù)訓(xùn)練模型的生成能力。
有關(guān)這一方面,可以參閱 Lilian Weng 的一篇博客:
https://lilianweng.github.io/lil-log/2021/01/02/controllable-neural-text-generation.html
少樣本學(xué)習(xí)可以使一個模型快速承接各種任務(wù)。但是為每個任務(wù)更新整個模型的權(quán)重是很浪費的。我們最好進(jìn)行局部更新,讓更改集中在一小部分參數(shù)里。有一些方法讓這些微調(diào)變得更加有效和實用,包括使用 adapter(Houlsby et al., 2019、Pfeiffer et al., 2020a、üstün et al., 2020),加入稀疏參數(shù)向量(Guo et al., 2020),以及僅修改偏差值(Ben-Zaken et al., 2020)。
能夠僅基于幾個范例就可以讓模型學(xué)會完成任務(wù)的方法,大幅度降低了機器學(xué)習(xí)、NLP 模型應(yīng)用的門檻。這讓模型可以適應(yīng)新領(lǐng)域,在數(shù)據(jù)昂貴的情況下為應(yīng)用的可能性開辟了道路。
對于現(xiàn)實世界的情況,我們可以收集上千個訓(xùn)練樣本。模型同樣也應(yīng)該可以在少樣本學(xué)習(xí)和大訓(xùn)練集學(xué)習(xí)之間無縫切換,不應(yīng)受到例如文本長度這樣的限制。在整個訓(xùn)練集上微調(diào)過的模型已經(jīng)在 SuperGLUE 等很多流行任務(wù)中實現(xiàn)了超越人類的性能,但如何增強其少樣本學(xué)習(xí)能力是改進(jìn)的關(guān)鍵所在。
對比學(xué)習(xí)
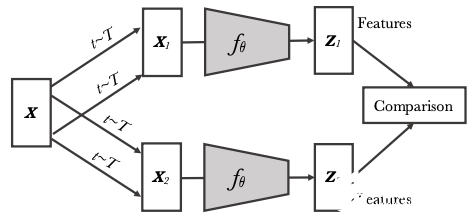
實例判別從同一個圖像的不同轉(zhuǎn)換之間比較特征(Caron et al., 2020)。
對比學(xué)習(xí)是一種為 ML 模型描述相似和不同事物的任務(wù)的方法。利用這種方法,可以訓(xùn)練機器學(xué)習(xí)模型來區(qū)分相似和不同的圖像。
最近,對比學(xué)習(xí)在計算機視覺和語音的自監(jiān)督表征學(xué)習(xí)(van den Oord, 2018; Hénaff et al., 2019)中越來越受歡迎。用于視覺表征學(xué)習(xí)的新一代自監(jiān)督強大方法依賴于使用實例判別任務(wù)的對比學(xué)習(xí):將不同圖像視為 negative pairs,相同圖像的多個視圖視為 positive pairs。最近的方法進(jìn)一步改善了這種通用框架:SimCLR(Chen et al., 2020)定義了增強型實例的對比損失;Momentum Contrast(He et al., 2020)試圖確保大量且一致的樣本對集合;SwAV(Caron et al., 2020)利用在線聚類;而 BYOL 僅使用 positive pairs(Grill et al., 2020)。Chen 和 He (2020) 進(jìn)一步提出了一種與先前方法有關(guān)的更簡單的表述。
最近,Zhao et al. (2020)發(fā)現(xiàn)數(shù)據(jù)增強對于對比學(xué)習(xí)至關(guān)重要。這可能表明為什么在數(shù)據(jù)增強不那么普遍的 NLP 中使用大型預(yù)訓(xùn)練模型進(jìn)行無監(jiān)督對比學(xué)習(xí)并不成功。他們還假設(shè),實例判別比計算機視覺中的有監(jiān)督預(yù)訓(xùn)練更好的原因是:它不會試圖讓一個類中所有實例的特征相似,而是保留每個實例的信息。在 NLP 中,Gunel et al. (2020)無監(jiān)督的預(yù)訓(xùn)練涉及對成千上萬個單詞類型進(jìn)行分類的問題不大。在 NLP 中,Gunel et al. (2020)最近采用對比學(xué)習(xí)進(jìn)行有監(jiān)督的微調(diào)。
語言建模中常用的 one-hot 標(biāo)簽與模型輸出的 logit 之間的交叉熵目標(biāo)存在一些局限性,例如在不平衡的類中泛化效果較差(Cao et al., 2019)。對比學(xué)習(xí)是一種可選擇的補充范式,可以幫助緩解其中的一些問題。
對比學(xué)習(xí)與 masked 語言建模相結(jié)合能夠讓我們學(xué)習(xí)更豐富、更魯棒的表征。它可以幫助解決模型異常值以及罕見的句法和語義現(xiàn)象帶來的問題,這對當(dāng)前的 NLP 模型是一個挑戰(zhàn)。
要評估的不只是準(zhǔn)確率
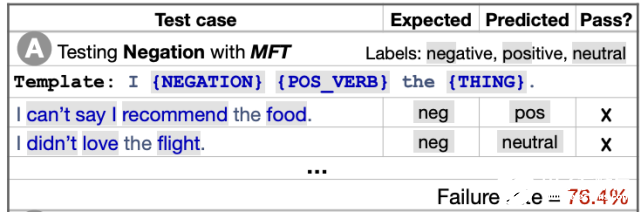
用于探索情感分析中否定性的理解的 CheckList 模板和測試(Ribeiro et al., 2020)。
NLP 中的 SOTA 模型已在許多任務(wù)上實現(xiàn)了超越人類的表現(xiàn),但我們能否相信這樣的模型可以實現(xiàn)真正的自然語言理解(Yogatama et al., 2019; Bender and Koller, 2020)?其實,當(dāng)前的模型離這個目標(biāo)還很遠(yuǎn)。但矛盾的是,現(xiàn)有的簡單性能指標(biāo)無法體現(xiàn)這些模型的局限性。該領(lǐng)域有兩個關(guān)鍵主題:a)精選當(dāng)前模型難以處理的樣例;b)不只是選擇準(zhǔn)確率等簡單指標(biāo),而是進(jìn)行更細(xì)粒度的評估。
關(guān)于前者,常用的方法是在數(shù)據(jù)集創(chuàng)建過程中使用對抗過濾(Zellers et al., 2018),過濾出由當(dāng)前模型正確預(yù)測的樣例。最近的研究提出了更有效的對抗過濾方法(Sakaguchi et al., 2020; Le Bras et al., 2020)和一種迭代數(shù)據(jù)集創(chuàng)建處理方法(Nie et al., 2020; Bartolo et al., 2020),其中樣例經(jīng)過過濾,模型經(jīng)過了多輪的重新訓(xùn)練。Dynabench 提供了此類不斷變化的基準(zhǔn)的子集。
針對第二點的方法在本質(zhì)上也是相似的。該領(lǐng)域通常會創(chuàng)建 minimal pairs(也稱為反事實樣例或?qū)Ρ燃↘aushik et al., 2020; Gardner et al., 2020; Warstadt et al., 2020),這些 minimal pairs 以最小的方式干擾了樣例,并且經(jīng)常更改 gold label。Ribeiro et al. (2020) 在 CheckList 框架中形式化了一些基本的直覺,從而可以半自動地創(chuàng)建此類測試用例。此外,基于不同的屬性來描述樣例可以對模型的優(yōu)缺點進(jìn)行更細(xì)粒度的分析(Fu et al., 2020)
為了構(gòu)建功能更強大的機器學(xué)習(xí)模型,我們不僅需要了解模型是否優(yōu)于先前的系統(tǒng),還需要了解它會導(dǎo)致哪種錯誤以及還有哪些問題沒被反映出來。通過提供對模型行為的細(xì)粒度診斷,我們可以更輕松地識別模型的缺陷并提出解決方案。同樣,利用細(xì)粒度的評估可以更細(xì)致地比較不同方法的優(yōu)缺點。
語言模型的現(xiàn)實應(yīng)用問題
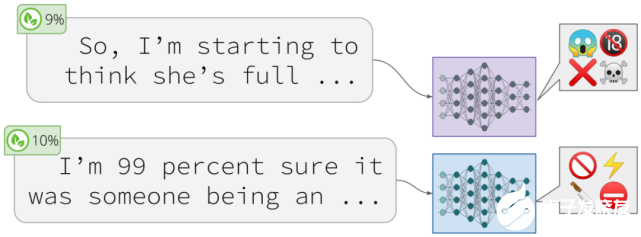
模型會根據(jù)看似無害的提示,生成有害的結(jié)果(Gehman et al., 2020)。
與 2019 年語言模型 (LMs) 分析側(cè)重于此類模型所捕獲的語法、語義和世界認(rèn)知的氛圍相比,最近一年的分析揭示了許多實際問題。
比如經(jīng)過預(yù)訓(xùn)練的 LM 容易生成「有毒」的語言 (Gehman et al., 2020)」、泄露信息 (Song & Raghunathan, 2020)。還存在微調(diào)后易受到攻擊的問題,以致攻擊者可以操縱模型預(yù)測結(jié)果 (Kurita et al., 2020; Wallace et al., 2020),以及容易受到模型的影響(Krishna et al., 2020; Carlini et al., 2020)。
眾所周知,預(yù)訓(xùn)練模型可以捕獲關(guān)于受保護(hù)屬性(例如性別)的偏見(Bolukbasi et al., 2016; Webster et al., 2020),Sun et al., 2019 的研究給出了一份減輕性別偏見的調(diào)查。
大公司推出的大型預(yù)訓(xùn)練模型往往在實際場景中會有積極的部署,所以我們更應(yīng)該意識到這些模型存在什么偏見,又會產(chǎn)生什么有害的后果。
隨著更大模型的開發(fā)和推出,從一開始就將這些偏見和公平問題納入開發(fā)過程是很重要的。
Multilinguality
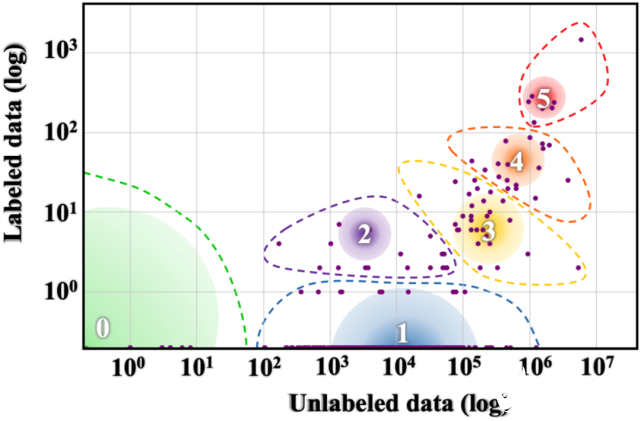
全球標(biāo)記 / 未標(biāo)記語言數(shù)據(jù)的不均衡分布情況(Joshi et al., 2020)。
2020 年,多語言 NLP 有諸多亮點。旨在加強非洲語種 NLP 研究的 Masakhane 機構(gòu)在第五屆機器翻譯會議 (WMT20) 上發(fā)表的主題演講,是去年最令人鼓舞的演講之一。此外,這一年還出現(xiàn)了其他語言的新通用基準(zhǔn),包括 XTREME (Hu et al., 2020)、XGLUE (Liang et al., 2020)、IndoNLU (Wilie et al., 2020)、IndicGLUE (Kakwani et al., 2020)。現(xiàn)有的數(shù)據(jù)集也拓展到了其他語言中,比如:
SQuAD: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020), FQuAD (d‘Hoffschmidt et al., 2020);
Natural Questions: TyDiQA (Clark et al., 2020), MKQA (Longpre et al., 2020);
MNLI: OCNLI (Hu et al., 2020), FarsTail (Amirkhani et al., 2020);
the CoNLL-09 dataset: X-SRL (Daza and Frank, 2020);
the CNN/Daily Mail dataset: MLSUM (Scialom et al., 2020)。
通過 Hugging Face 數(shù)據(jù)集可以訪問其中的大部分?jǐn)?shù)據(jù)集,以及許多其他語言的數(shù)據(jù)。涵蓋 100 種語言的強大模型也就應(yīng)運而生了,包括 XML-R (Conneau et al., 2020)、RemBERT (Chung et al., 2020)、InfoXLM (Chi et al., 2020)等,具體可參見 XTREME 排行榜。大量特定語言的 BERT 模型已經(jīng)針對英語以外的語言進(jìn)行了訓(xùn)練,例如 AraBERT (Antoun et al., 2020)和 IndoBERT (Wilie et al., 2020),查看 Nozza et al., 2020; Rust et al., 2020 的研究可以了解更多信息。借助高效的多語言框架,比如 AdapterHub (Pfeiffer et al., 2020)、Stanza (Qi et al., 2020)和 Trankit (Nguyen et al., 2020) ,世界上許多語種的建模和應(yīng)用工作都變得輕松了許多。
此外,還有兩篇很有啟發(fā)的研究,《The State and Fate of Linguistic Diversity(Joshi et al., 2020)》和《Decolonising Speech and Language Technology (Bird, 2020)》。第一篇文章強調(diào)了使用英語之外語言的緊迫性,第二篇文章指出了不要將語言社區(qū)及數(shù)據(jù)視為商品。
拓展到英語之外的 NLP 研究有很多好處,對人類社會能產(chǎn)生實實在在的影響。考慮到不同語言中數(shù)據(jù)和模型的可用性,英語之外的 NLP 模型將大有作為。同時,開發(fā)能夠應(yīng)對最具挑戰(zhàn)性設(shè)置的模型并確定哪些情況會造成當(dāng)前模型的基礎(chǔ)假設(shè)失敗,仍然是一項激動人心的工作。
圖像Transformers
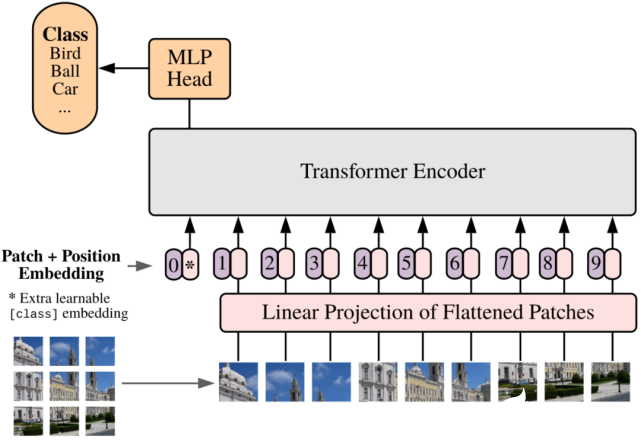
Vision Transformer 的論文中,研究者將 Transformer 編碼器應(yīng)用于平坦圖像塊。
Transformer 在 NLP 領(lǐng)域取得了巨大的成功,但它在卷積神經(jīng)網(wǎng)絡(luò) CNN 占據(jù)主導(dǎo)地位的計算機視覺領(lǐng)域卻沒那么成功。2020 年初的DETR (Carion et al., 2020)將 CNN 用于計算圖像特征,但后來的模型完全是無卷積的。Image GPT (Chen et al., 2020)采用了 GPT-2 的方法,直接從像素進(jìn)行預(yù)訓(xùn)練,其性能優(yōu)于有監(jiān)督的 Wide ResNet,后來的模型是將圖像重塑為被視為「token」的補丁。Vision Transformer (ViT,Dosovitskiy et al., 2020)在數(shù)百萬個標(biāo)記好的圖像上進(jìn)行了訓(xùn)練,每一個圖像都包含此類補丁,模型效果優(yōu)于現(xiàn)有最新的 CNN。Image Processing Transformer(IPT,Chen et al., 2020)在被破壞的 ImageNet 示例上進(jìn)行對比損失預(yù)訓(xùn)練,在 low-level 圖像任務(wù)上實現(xiàn)了新的 SOTA。Data-efficient image Transformer (DeiT,Touvron et al., 2020) 以蒸餾方法在 ImageNet 上進(jìn)行了預(yù)訓(xùn)練。
有趣的是,研究者們發(fā)現(xiàn)了 CNN 是更好的教師,這一發(fā)現(xiàn)類似于蒸餾歸納偏置(inductive bias)應(yīng)用于 BERT (Kuncoro et al., 2020)。相比之下在語音領(lǐng)域,Transformer 并未直接應(yīng)用于音頻信號,而通常是將 CNN 等編碼器的輸出作為輸入(Moritz et al., 2020; Gulati et al., 2020; Conneau et al., 2020)。
與 CNN 和 RNN 相比,Transformer 的歸納偏置更少。盡管在理論上,它不如 RNN (Weiss et al., 2018; Hahn et al., 2020)強大,但如果基于充足的數(shù)據(jù)和規(guī)模,Transformer 會超越其他競爭對手的表現(xiàn)。
未來,我們可能會看到 Transformer 在 CV 領(lǐng)域越來越流行,它們特別適用于有足夠計算和數(shù)據(jù)用于無監(jiān)督預(yù)訓(xùn)練的情況。在小規(guī)模配置的情況下,CNN 應(yīng)該仍是首選方法和基線。
自然科學(xué)與機器學(xué)習(xí)
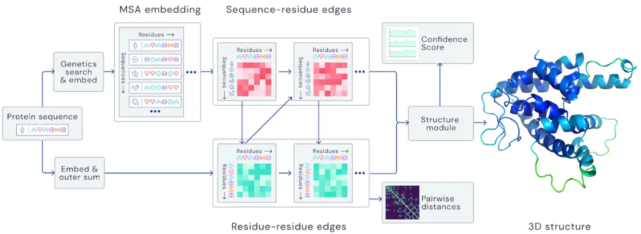
基于自注意力的 AlphaFold 架構(gòu)。
去年,DeepMind 的AlphaFold在 CASP 蛋白質(zhì)折疊挑戰(zhàn)賽中實現(xiàn)了突破性的表現(xiàn),除此之外,將機器學(xué)習(xí)應(yīng)用于自然科學(xué)還有一些顯著的進(jìn)展。MetNet (S?nderby et al., 2020)證明機器學(xué)習(xí)在降水預(yù)測方面優(yōu)于數(shù)值天氣預(yù)報;Lample 和 Charton(2020)采用神經(jīng)網(wǎng)絡(luò)求解微分方程,比商用計算機系統(tǒng)效果更好;Bellemare et al. (2020)使用強化學(xué)習(xí)為平流層的熱氣球?qū)Ш健?/p>
此外,ML 現(xiàn)已被廣泛應(yīng)用于 COVID-19,例如 Kapoor 等人利用 ML 預(yù)測 COVID-19 的傳播,并預(yù)測與 COVID-19 相關(guān)的結(jié)構(gòu),Anastasopoulos 等人將相關(guān)數(shù)據(jù)翻譯成 35 種不同的語言,Lee 等人的研究可以實時回答有關(guān) COVID-19 的問題。
有關(guān) COVID-19 相關(guān)的 NLP 應(yīng)用程序的概述,請參閱第一期 COVID-19 NLP 研討會的會議記錄:《Proceedings of the 1st Workshop on NLP for COVID-19 (Part 2) at EMNLP 2020》。
自然科學(xué)可以說是 ML 最具影響力的應(yīng)用領(lǐng)域。它的改進(jìn)涉及到生活的許多方面,可以對世界產(chǎn)生深遠(yuǎn)的影響。隨著蛋白質(zhì)折疊等核心領(lǐng)域的進(jìn)展,ML 在自然科學(xué)中的應(yīng)用速度只會加快。期待更多促進(jìn)世界進(jìn)步的研究出現(xiàn)。
強化學(xué)習(xí)
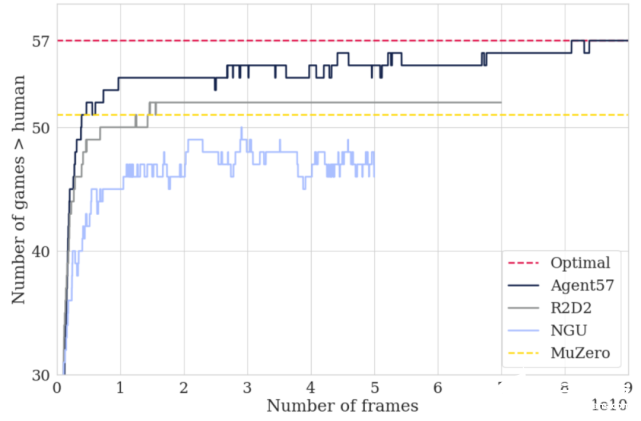
與最先進(jìn)的智能體相比,Agent57 和 MuZero 整個訓(xùn)練過程中在雅達(dá)利游戲中的表現(xiàn)優(yōu)于人類基準(zhǔn)(Badia et al., 2020)。
單個深度強化學(xué)習(xí)智能體Agent57(Badia et al., 2020)首次在 57 款 Atari 游戲上超過人類,這也是深度強化學(xué)習(xí)領(lǐng)域中的一個長期基準(zhǔn)。智能體的多功能性來自于神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)允許在探索性策略和利用性策略之間切換。
強化學(xué)習(xí)在游戲方面的另一個里程碑是 Schrittwieser 等人開發(fā)的MuZero,它能預(yù)測環(huán)境各個方面,而環(huán)境對精確的規(guī)劃非常重要。在沒有任何游戲動態(tài)知識的情況下,MuZero 在雅達(dá)利上達(dá)到了 SOTA 性能,在圍棋、國際象棋和日本象棋上表現(xiàn)也很出色。
最后是 Munchausen RL 智能體(Vieillard et al., 2020),其通過一個簡單的、理論上成立的修改,提高了 SOTA 水平。
強化學(xué)習(xí)算法有許多實際意義 (Bellemare et al., 2020)。研究人員對這一領(lǐng)域的基本算法進(jìn)行改進(jìn),通過更好的規(guī)劃、環(huán)境建模和行動預(yù)測產(chǎn)生很大的實際影響。
隨著經(jīng)典基準(zhǔn)(如 Atari)的基本解決,研究人員可能會尋找更具挑戰(zhàn)性的設(shè)置來測試他們的算法,如推廣到外分布任務(wù)、提高樣本效率、多任務(wù)學(xué)習(xí)等。
責(zé)任編輯:PSY
-
人工智能
+關(guān)注
關(guān)注
1791文章
47208瀏覽量
238304 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8408瀏覽量
132580 -
自然語言
+關(guān)注
關(guān)注
1文章
288瀏覽量
13347
發(fā)布評論請先 登錄
相關(guān)推薦
高能點焊電源技術(shù)在現(xiàn)代工業(yè)制造中的應(yīng)用與研究進(jìn)展

上海光機所在多路超短脈沖時空同步測量方面取得研究進(jìn)展
AI大模型的最新研究進(jìn)展
度亙核芯榮獲“2023年度中國十大光學(xué)產(chǎn)業(yè)技術(shù)”獎

量子計算+光伏!本源研究成果入選2023年度“中國地理科學(xué)十大研究進(jìn)展”

綜述:高性能銻化物中紅外半導(dǎo)體激光器研究進(jìn)展

中國科學(xué)十大進(jìn)展!華為云盤古氣象大模型入選!
2023年度中國半導(dǎo)體十大研究進(jìn)展出爐,一項傳感器技術(shù)入榜(附全名單)
睿創(chuàng)微納8微米榮獲“2023年度山東十大科技創(chuàng)新成果”
睿創(chuàng)微納8微米榮獲“2023年度山東十大科技創(chuàng)新成果”

2024 年“十大突破性技術(shù)”榜單

福布斯公布關(guān)于2024年人工智能發(fā)展的十大預(yù)見
2023年度十大科技名詞





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論