 谷歌開發出超過一萬億參數的語言模型,秒殺GPT-3
谷歌開發出超過一萬億參數的語言模型,秒殺GPT-3
繼GPT-3問世僅僅不到一年的時間,Google重磅推出Switch Transformer,直接將參數量從GPT-3的1750億拉高到1.6萬億,并比之前最大的、由google開發的語言模型T5-XXL足足快了4倍。
對于機器學習來說,參數可以算得上算法的關鍵:他們是歷史的輸入數據,經過模型訓練得來的結果,是模型的一部分。
一般來說,在NLP領域,參數數量和復雜程度之間具有正相關性。
迄今為止,OpenAI 的 GPT-3是有史以來最大的語言模型之一,有1750億個參數。
現在,距離GPT-3問世不到一年的時間,更大更復雜的語言模型又來了——
在對這種相關性進行最全面測試的基礎上,谷歌的研究人員開發了一種能夠訓練包含超過一萬億參數的語言模型:Switch Transformer,并進行了基準測試。
他們表示,1.6萬億參數模型是迄今為止最大的,并比之前最大的、由google開發的語言模型T5-XXL足足快了4倍。
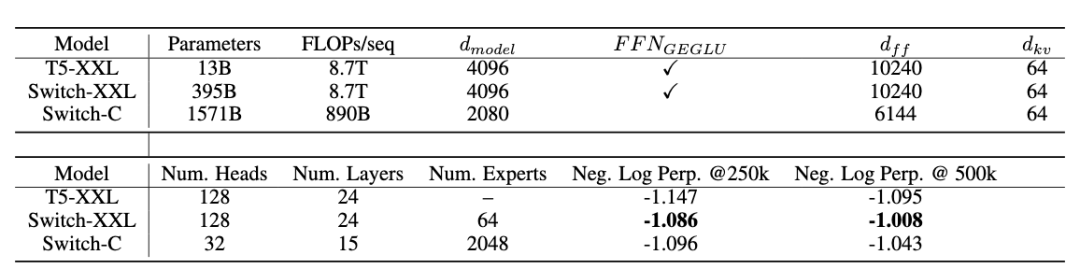
圖:Switch 模型設計和預訓練表現
研究人員在論文中表示,對于強大模型來說,進行大規模訓練是一個非常有效的途徑。
盡管在大數據集和參數支撐下的簡單的架構可以超越一些復雜的算法,然而,高效且大規模的訓練卻屬于極度的計算密集型。
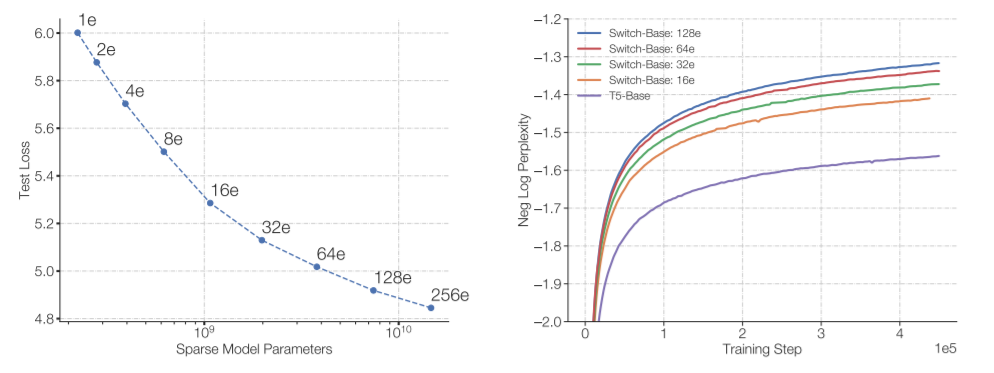
而這,也正是Google的研究者發明Switch Transformer的原因。
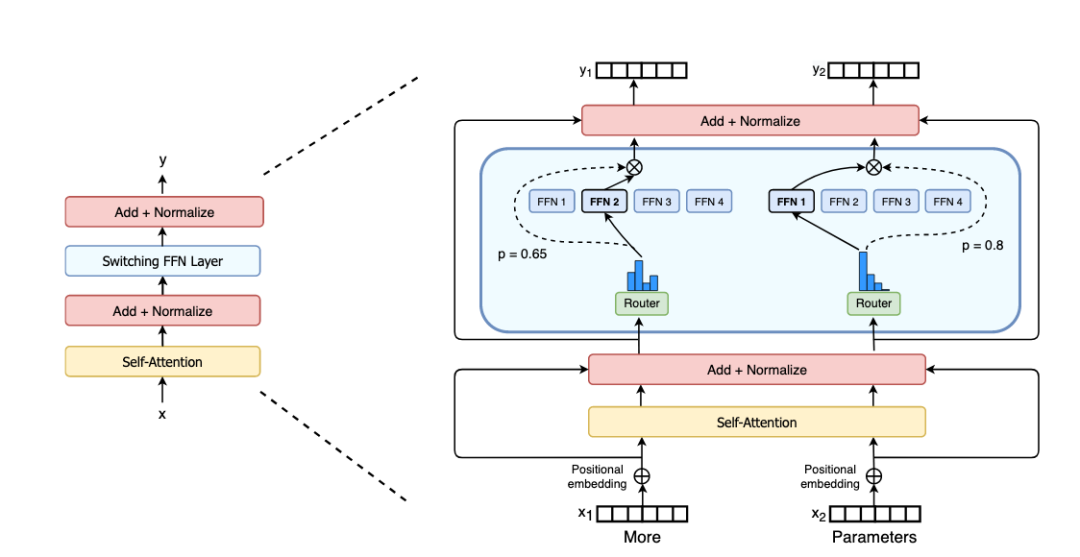
圖:Switch Transformer編碼塊
Switch Transformer使用了一種叫做稀疏激活(sparsely activated)的技術,這個技術只使用了模型權重的子集,或者是轉換模型內輸入數據的參數,即可達成相同的效果。
此外,Switch Transformer還主要建立在混合專家(Mix of Expert)的基礎上。
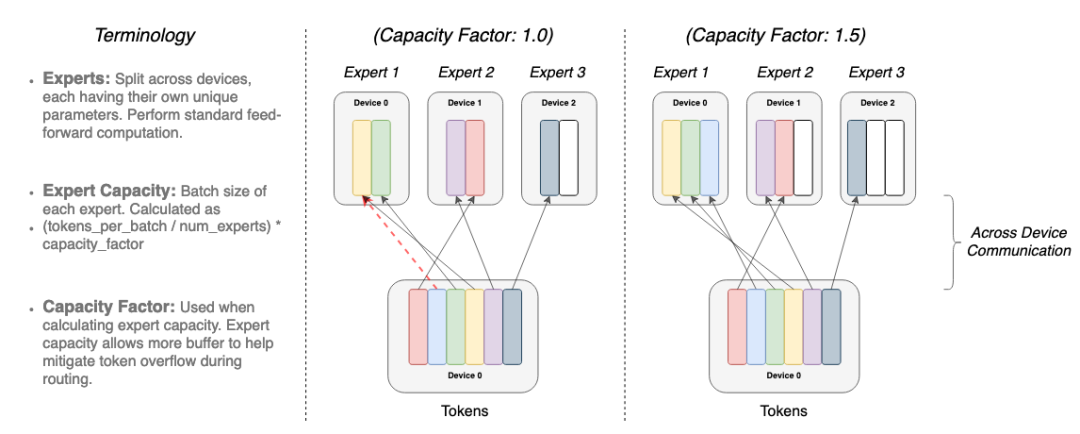
圖:Token動態路由示例
什么是“混合專家”呢?
混合專家(Mix of Expert,MoE)是90年代初首次提出的人工智能模型范式。
在MoE中,對于不同的輸入,會選擇不同的參數。多個專家(或者專門從事不同任務的模型)被保留在一個更大的模型中,針對任何給定的數據,由一個“門控網絡”來選擇咨詢哪些專家。
其結果是一個稀疏激活的模型——具有數量驚人的參數,但計算成本不變。然而,盡管MoE取得了一些顯著的成功,但其廣泛采用仍然受到復雜性、通信成本和訓練不穩定性的阻礙。而Switch Transformer則解決了這些問題。
Switch Transformer的新穎之處,在于它有效地利用了為密集矩陣乘法(廣泛應用于語言模型的數學運算)設計的硬件,如GPU和谷歌的TPU。
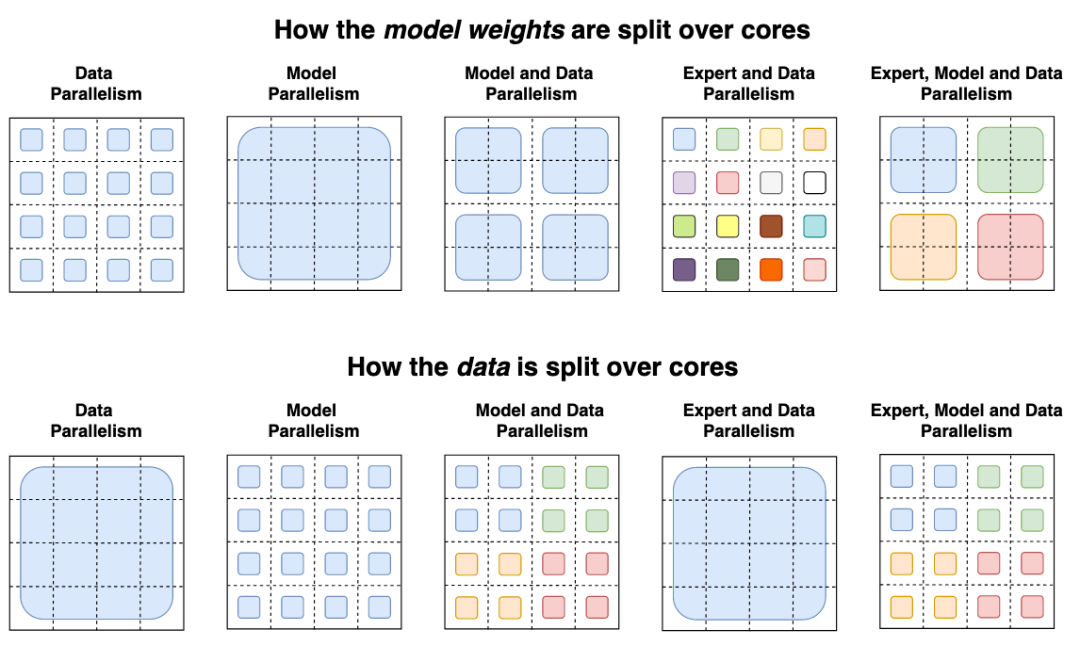
圖:數據和權重劃分策略
在研究人員的分布式訓練設置中,他們的模型將不同的權重分配到不同的設備上,因此,雖然權重會隨著設備數量的增加而增加,但是每個設備卻可以保持可管理的內存和計算足跡。
在一項實驗中,研究人員使用了32個TPU核,在“Colossal Clean Crawled Corpus”,也就是 C4 數據集上,預先訓練了幾種不同的Switch Transformer模型。
C4是一個750gb大小的數據集,包含從Reddit、Wikipedia和其他web資源上獲取的文本。
研究人員讓這些Switch Transformer模型去預測有15%的單詞被掩蓋的段落中遺漏的單詞,除此之外,還為模型布置了許多其他挑戰,如檢索文本來回答一系列越來越難的問題等等。
研究人員聲稱,和包含3950億個參數和64名專家的更小的模型(Switch-XXL)相比,他們發明的擁有2,048名專家的1.6萬億參數模型(Switch-C)則“完全沒有訓練不穩定性”。
然而,在SQuAD的基準測試上,Switch-C的得分卻更低(87.7),而Switch-XXL的得分為89.6。
對此,研究人員將此歸因于微調質量、計算要求和參數數量之間的不明確關系。
在這種情況下,Switch Transformer還是在許多下游任務上的效果有了提升。例如,根據研究人員的說法,在使用相同數量的計算資源的情況下,它可以使預訓練的速度提高了7倍以上。
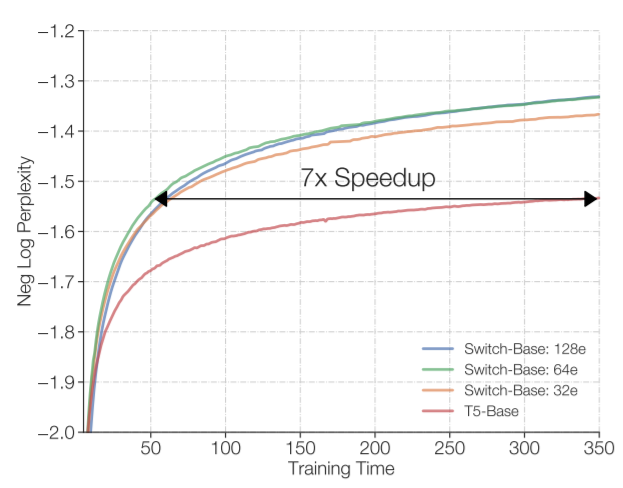
圖:所有模型均在32個TPU上進行訓練
同時研究人員證明,大型稀疏模型可以用來創建更小、更稠密的模型,這些模型可以對任務進行微調,其質量增益只有大型模型的30% 。
在一個測試中,一個 Switch Transformer 模型被訓練在100多種不同的語言之間進行翻譯,研究人員觀察到其中101種語言都得到了“普遍的改善”,91% 的語言受益于超過baseline模型4倍以上的速度。
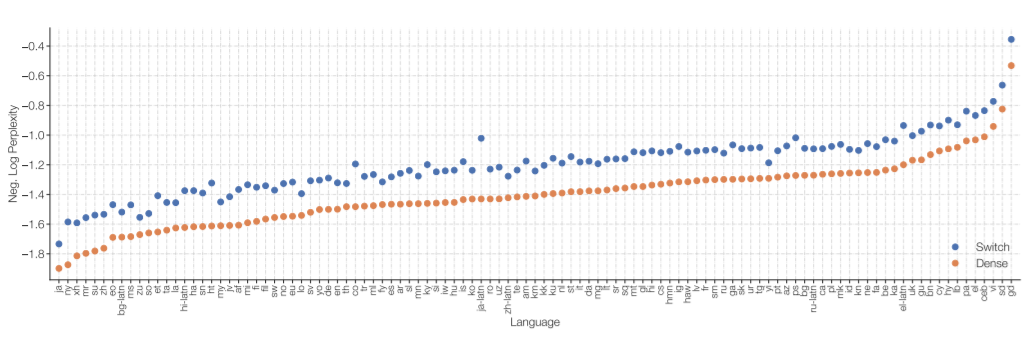
圖:101種語言的多語言預訓練
研究人員在論文中寫道: “雖然這項工作主要集中在超大型模型上,但我們也發現,只有兩個專家的模型能夠提高性能,同時很容易適應常用 GPU 或 TPU 的內存約束。”
“我們不能完全保證模型的質量,但是通過將稀疏模型蒸餾成稠密模型,同時達到專家模型質量增益的30%的情況下 ,是可以達到10到100倍壓縮率的。”
在未來的工作中,研究人員計劃將Switch Transformer應用到新的和跨越不同的模態中去,包括圖像和文本。他們認為,模型稀疏性可以賦予各種不同媒介以及多模態模型一些優勢。
在論文的最后,Google的研究人員還表示:
總的來說,Switch Transformers是一個可擴展的,高效的自然語言學習模型。
通過簡化MoE,得到了一個易于理解、易于訓練的體系結構,該結構還比同等大小的密集模型具有更大的采樣效率。
這些模型在一系列不同的自然語言任務和不同的訓練機制中,包括預訓練、微調和多任務訓練,都表現出色。
這些進步使得使用數千億到萬億參數訓練模型成為可能,相對于密集的T5基準,這些模型可以實現顯著的加速。
谷歌的研究人員表示,希望他們的工作能夠激勵稀疏模型成為一種有效的架構,并鼓勵研究人員和實踐者在自然語言任務中考慮這些靈活的模型。
原文標題:1.6萬億參數,秒殺GPT-3!谷歌推出超級語言模型Switch Transformer,比T5快4倍
文章出處:【微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
谷歌
+關注
關注
27文章
6164瀏覽量
105309 -
人工智能
+關注
關注
1791文章
47200瀏覽量
238270 -
模型
+關注
關注
1文章
3229瀏覽量
48810
原文標題:1.6萬億參數,秒殺GPT-3!谷歌推出超級語言模型Switch Transformer,比T5快4倍
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大語言模型開發語言是什么
Jim Fan展望:機器人領域即將迎來GPT-3式突破
谷歌發布新型大語言模型Gemma 2
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
微軟發布phi-3AI模型,性能超越GPT-3.5
Meta推出最強開源模型Llama 3 要挑戰GPT

新火種AI|秒殺GPT-4,狙殺GPT-5,橫空出世的Claude 3振奮人心!

OpenAI推出ChatGPT新功能:朗讀,支持37種語言,兼容GPT-4和GPT-3
谷歌模型軟件有哪些功能
Rambus HBM3內存控制器IP速率達到9.6 Gbps






 工商網監
工商網監
評論