

Hadoop到目前為止發展已經有10余年,版本經過無數次的更新迭代,目前業內大家把Hadoop大的版本分為Hadoop1.0、Hadoop2.0、Hadoop3.0 三個版本。
一、Hadoop 簡介
Hadoop版本剛出來的時候是為了解決兩個問題:一是海量數據如何存儲的問題,一個是海量數據如何計算的問題。Hadoop的核心設計就是HDFS和 Mapreduce.HDFS解決了海量數據如何存儲的問題, Mapreduce解決了海量數據如何計算的問題。HDFS的全稱:Hadoop Distributed File System。
二、分布式文件系統
![]()
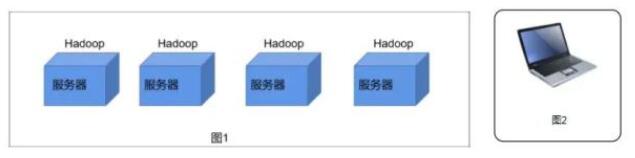
圖片 HDFS其實就可以理解為一個分布式文件系統,可以看如圖1所示有4個服務器是不是都有他自己的文件系統都可以進行存儲數據,假設每個服務器的存儲空間存儲10G的數據。假設數據量很小的時候存儲10G的數據還是ok的當數據量大于服務器的存儲空間時是不是單個服務器就沒法存儲了。 我們是不是可以在服務器中部署一個Hadoop這樣就能構建出一個集群(超級大電腦)。這樣就存儲 4*10=40G的數據量,這樣我們面向用戶時是不是只有一臺超級大的電腦相當于一個分布式文件系統。
HDFS是一個主從的架構、主節點只有一個NemeNode。從節點有多個DataNode。
三、HDFS 架構
![]()
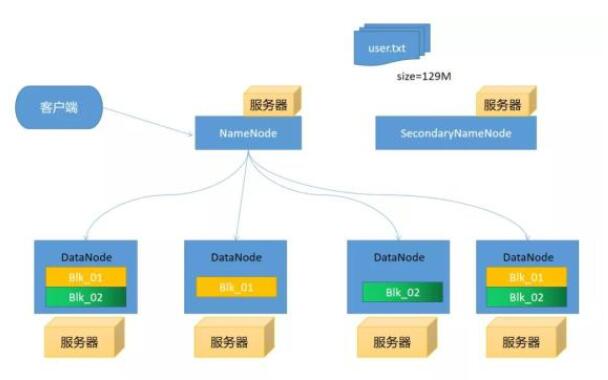
圖片 假設我們這里有5臺服務器每臺服務器都部署上Hadoop,我們隨便選擇一臺服務器部署上NameNode剩下服務器部署上DataNode。
客戶端上傳文件時假設文件大小為129MHDFS默認切分的大小為128M這時就會產生出2個blkNameNode去通知DataNode上傳文件(這里有一定的策略),我們就假設就將這幾個文件分別存儲在4個服務器上。為什們要進行分別存儲在,假設DataNode服務器有一天突然掛掉了我們是不是還可通過DataNode4或2和3進行讀取數據,這樣是不是就防止數據丟失。
NameNode
管理元數據信息(文件目錄樹):文件與Block塊,Block塊與DataNode主機關系 NameNode為快速響應用戶操作,所以把元數據信息加載到內存里
DataNode
存儲數據,把上傳的數據劃分固定大小文件塊(Block)在Hadoop2.73之前是64M之后改為了128M 為了保證數據安全,每個文件默認都是三個副本
SecondaryNamenode
周期性的到NameNode節點拉取Edtis和fsimage文件,將這兩個文件加入到內存進行 然后將這兩個文件加入到內存中進行合并產生新的fsimage發送給NameNode。
四、HDFS寫入數據流程
客戶端會帶著文件路徑向NameNode發送寫入請求通過 RPC 與 NameNode 建立通訊, NameNode 檢查目標文件,返回是否可以上傳; Client 請求第一個 block 該傳輸到哪些 DataNode 服務器上; NameNode 根據副本數量和副本放置策略進行節點分配,返回DataNode節點,如:A,B,C Client 請求A節點建立pipeline管道,A收到請求會繼續調用B,然后B調用C,將整個pipeline管道建立完成后,逐級返回消息到Client; Client收到A返回的消息之后開始往A上傳第一個block塊,block塊被切分成64K的packet包不斷的在pepiline管道里傳遞,從A到B,B到C進行復制存儲 當一個 block塊 傳輸完成之后,Client 再次請求 NameNode 上傳第二個block塊的存儲節點,不斷往復存儲 當所有block塊傳輸完成之后,Client調用FSDataOutputSteam的close方法關閉輸出流,最后調用FileSystem的complete方法告知NameNode數據寫入成功
五、HDFS讀取數據流程
客戶端會先帶著讀取路徑向NameNode發送讀取請求,通過 RPC 與 NameNode 建立通訊,NameNode檢查目標文件,來確定請求文件 block塊的位置信息 NameNode會視情況返回文件的部分或者全部block塊列表,對于每個block塊,NameNode 都會返回含有該 block副本的 DataNode 地址 這些返回的 DataNode 地址,會按照集群拓撲結構得出 DataNode 與客戶端的距離,然后進行排序,排序兩個規則:網絡拓撲結構中距離 Client 近的排靠前;心跳機制中超時匯報的 DN 狀態為 STALE,這樣的排靠后; Client 選取排序靠前的 DataNode 調用FSDataInputSteam的read方法來讀取 block塊數據,如果客戶端本身就是DataNode,那么將從本地直接獲取block塊數據 當讀完一批的 block塊后,若文件讀取還沒有結束,客戶端會繼續向NameNode 獲取下一批的 block 列表,繼續讀取 所有block塊讀取完成后,Client調用FSDataInputStream.close()方法,關閉輸入流,并將讀取來所有的 block塊合并成一個完整的最終文件
六、HDFS缺陷
注意:早期版本
單點問題 內存受限
總結
上述給大家講解了簡單的HDFS架構,我在最后面留了一個小問題,我會在下期通過畫圖的方式給大家講解,我在這里為大家提供大數據的資料需要的朋友可以去下面GitHub去下載,信自己,努力和汗水總會能得到回報的。
責任編輯:YYX
-
數據
+關注
關注
8文章
7246瀏覽量
91143 -
存儲
+關注
關注
13文章
4507瀏覽量
87111 -
HDFS
+關注
關注
1文章
31瀏覽量
9838
發布評論請先 登錄
如何從CYUSB3014-BZXCT讀取/寫入EEPROM固件?
如何用c#使用ST25R3911DISCOComm.dll來讀取和寫入NDEF區的數據?
請問如何使S32K312 FLEXCAN的以下區域在寫入后讀取與寫入不同?
nt3h211通過I2C向EEPROM寫入數據,但NFC工具無法讀取寫入的數據,為什么?
NVIDIA Blackwell數據手冊與NVIDIA Blackwell架構技術解析
如何用c#使用ST25R3911DISCOComm.dll來讀取和寫入NDEF區的數據?
影響25Q20D閃存芯片寫入速度和使用壽命的因素有哪些?

適用于Oracle的SSIS數據流組件:提供快速導入及導出功能

芯片封測架構和芯片封測流程
使用STM32的spi與AFE4400通信,每寫入或讀取一個數據都需要等待幾百微秒后才能繼續操作否則讀取的數據都是0,為什么?
使用ads1219這款模數轉換器,讀寫流程和使用single-shot模式和continuous的區別是什么?
請問TLV320AIC3254EVM-K怎么讀取音頻數據流?
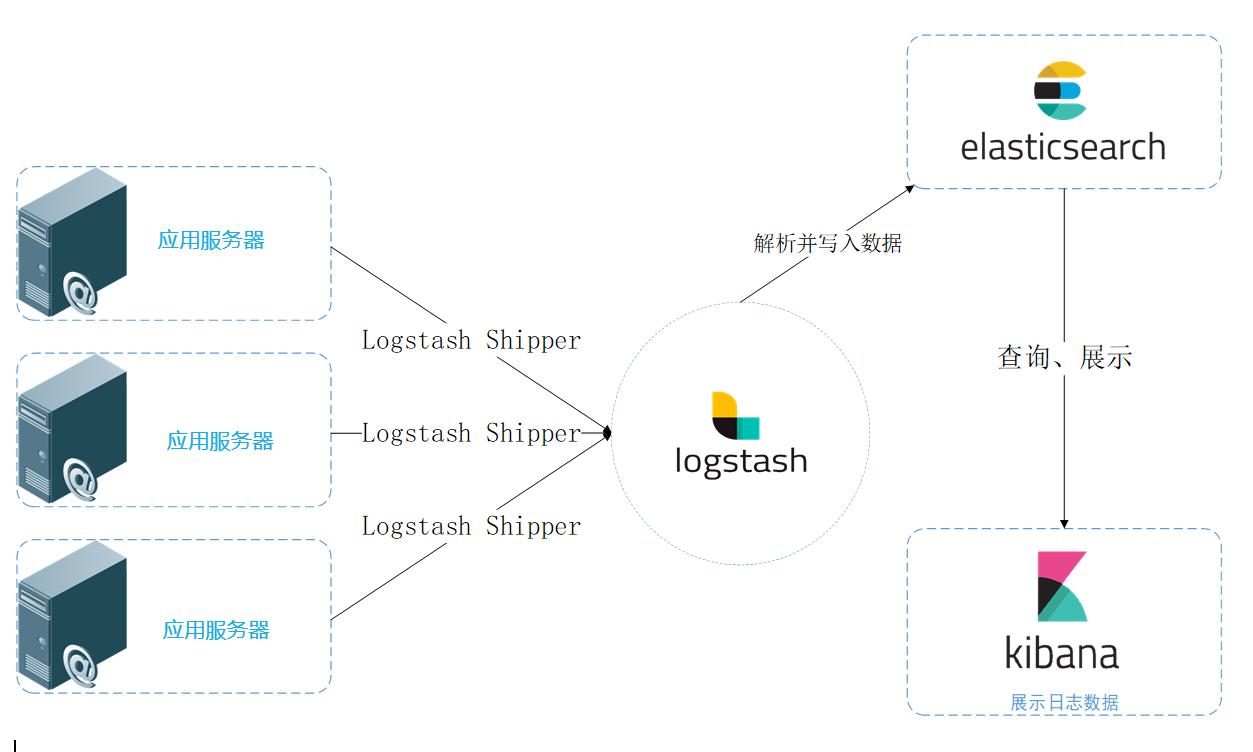
統一日志數據流圖





 工商網監
工商網監

評論