 機器學習中流式數據處理的使用場景及相關技術介紹
機器學習中流式數據處理的使用場景及相關技術介紹
在工業界,當我們提到實時數據機器學習時,常常可以聽到如下討論:
他們希望有一個模型,這個模型利用最近歷史信息來進行預測分析。舉一個天氣的例子,如果最近幾天都是晴天,那么未來幾天極小概率會出現雨雪和低溫天氣
這個模型還需要是可更新的。當數據流經系統時,模型是可以隨之進化升級。舉個例子,隨著業務規模的擴大,我們希望零售銷售模型仍然保持準確。
實時機器學習應用是人工智能真正落地服務化的關鍵一步,因為工業界大部分場景下數據都是實時產生的。因此作為一名合格的人工智能領域專家,掌握流式場景下的算法設計必不可少。 本文主要介紹流式數據處理的使用場景、相關技術,并從服務管理的角度,介紹了針對流式計算服務的設計及關鍵指標。主要面向希望了解流式計算、服務管理的朋友們。
流式計算的使用場景
01
首先,當前業界已經有非常多數據處理的方式了,為什么還需要流式數據處理?要回答這個問題,我們先回顧一下傳統的的數據處理架構。 傳統的數據處理架構是一種典型的以數據庫為中心,適應存儲事務性數據處理的場景。由于數據處理能力優先,在該架構下,往往數據都是以批量的方式進行處理,例如:批量寫入數據庫、批量讀取數據庫進行數據處理。這種架構在面對實時性較低的場景中較為有效,但是在對實時性較高的場景則不太有效,例如:自動駕駛場景、工業機器人場景、基于會話的用戶統計等。
因此,流式計算或流式數據處理被提出。其實流處理它最接近數據產生的自然規律,只不過過去我們沒有流處理能力,只能做一些特殊的處理才能真正地使用流數據,比如將流數據攢成批量數據再處理,不然無法進行大規模的計算。使用流數據并不新鮮,新鮮的是我們有了新技術,從而可以大規模、靈活、自然和低成本地使用它們。 流式處理的核心目標有以下三點:
低延遲:近實時的數據處理能力
高吞吐:能處理大批量的數據
可以容錯:在數據計算有誤的情況下,可容忍錯誤,且可更正錯誤
流式處理框架
02
典型的流處理框架結合了消息傳輸層技術以及流處理層技術。具體如圖所示:
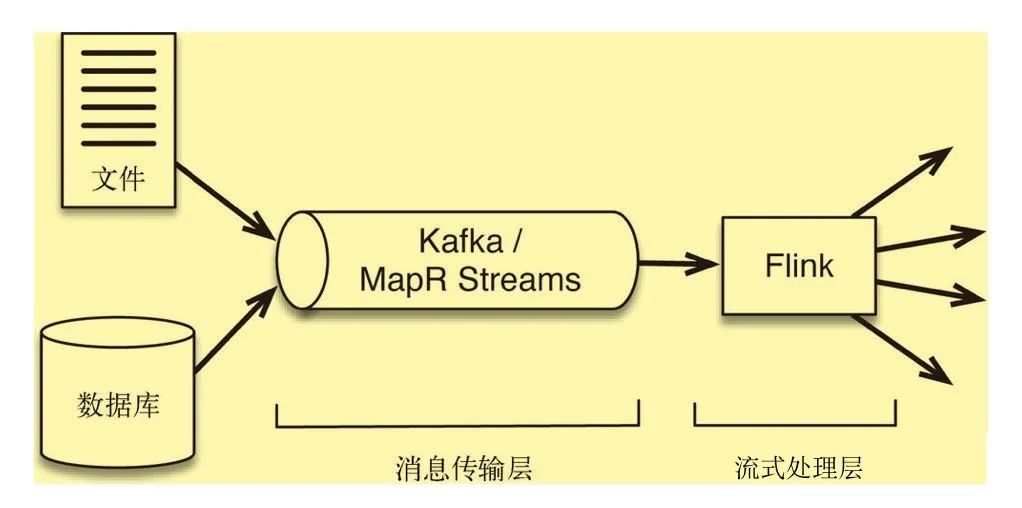
消息傳輸層的引入流處理層提供了以下支持:
消息傳輸層的一個作用是作為流處理層上游的安全隊列,它相當于緩沖區,可以將事件數據作為短期數據保留起來,以防數據處理過程發生中斷
具有持久性的好處之一是消息可以重播。實現時間穿梭
在當前典型的流處理技術中,有這么幾類:
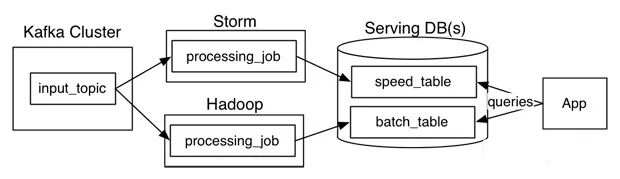
Lambda架構
基于Lambda架構,實現了離線計算的精確性的同時,且獲得了流式數據處理的實時性。但是,由于要開發同樣邏輯的代碼,開發、維護成本高
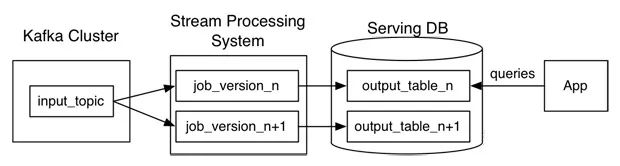
Kappa架構為了解決lambda架構中維護兩套同樣邏輯的代碼,kappa架構提出使用流式處理解決上述問題。當需要重新處理、計算數據時,使用另一個流程處理的作業(可以是相同的、優化的版本)進行數據處理。
spark streaming
基于小批量進行數據處理
Flink
以上幾種技術中,flink既可以實現低延遲、高吞吐,還可以實現容錯。
Flink概況
03
Flink技術除支持流處理外,還支持批處理,其架構如下圖所示:
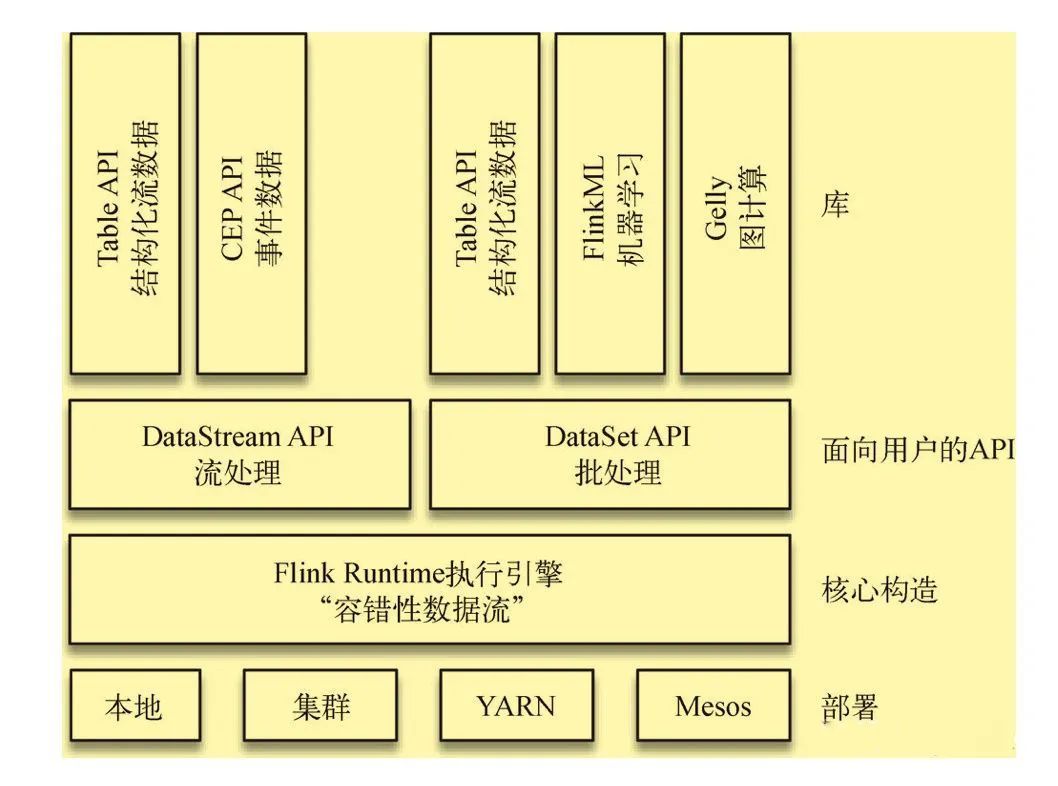
另外,Flink具有分布式的特點,具體體現在它能夠在成百上千臺機器上運行,它將大型的計算任務分成許多小的部分,每個機器執行一個部分。 Flink能夠自動地確保在發生機器故障或者其他錯誤時計算能持續進行,或者在修復bug或進行版本升級后有計劃地再執行一次。這種能力使得開發人員不需要擔心失敗。 Flink本質上使用容錯性數據流,這使得開發人員可以分析持續生成且永遠不結束的數據(即流處理)。因為不用再在編寫應用程序代碼時考慮如何解決問題,所以工程師的時間得以充分利用,整個團隊也因此受益。好處并不局限于縮短開發時間,隨著靈活性的增加,團隊整體的開發質量得到了提高,運維工作也變得更容易、更高效。Flink讓應用程序在生產環境中獲得良好的性能。
總體來說,Flink的主要特性:
符合產生數據的自然規律:支持流式數據處理
發生故障后仍保持準確:具體容錯機制(exactly once)
及時給出所需結果:低延遲、實時性強
時間概念
在流數據處理的體系中,時間是一個重要的概念。總體來說,可分為以下三種時間:
事件時間:即事件實際發生的時間。更準確地說,每一個事件都有一個與它相關的時間戳,并且時間戳是數據記錄的一部分(比如手機或者服務器的記錄)。事件時間其實就是時間戳。處理時間,即事件被處理的時間。
處理時間:其實就是處理事件的機器所測量的時間
攝取時間:也叫作進入時間。它指的是事件進入流處理框架的時間
Flink允許用戶根據所需的語義和對準確性的要求選擇采用事件時間、處理時間或攝取時間定義窗口
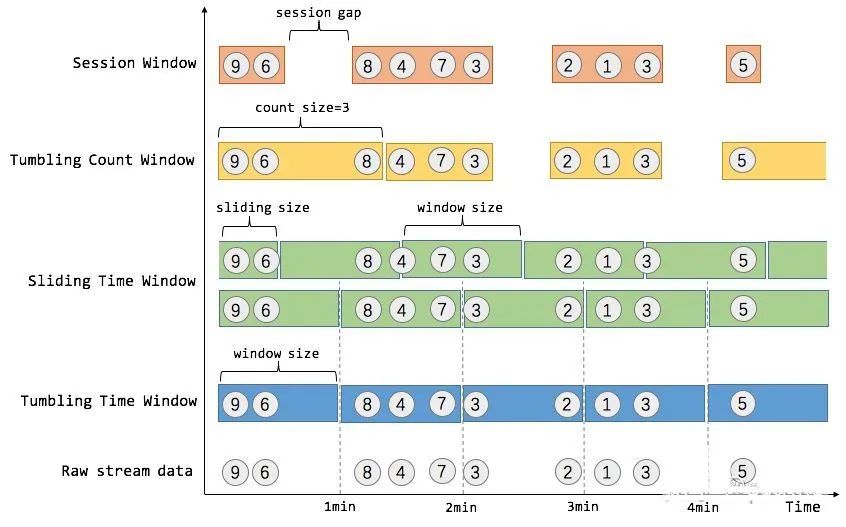
窗口
窗口是一種機制,它用于將許多事件按照時間或者其他特征分組,從而將每一組作為整體進行分析(比如求和)
時間穿梭
流處理器支持事件時間,這意味著將數據流“倒帶”,用同一組數據重新運行同樣的程序,會得到相同的結果
水印
假設第一個窗口從1000開始(即從10時0分0秒開始),需要計算從1000到1000的數值總和。當時間就是記錄的一部分時,我們怎么知道1000已到呢?換句話說,我們怎么知道蓋有時間戳1059的元素還沒到呢?Flink通過水印來推進事件時間。水印是嵌在流中的常規記錄,計算程序通過水印獲知某個時間點已到。
有狀態的計算
流式計算分為無狀態和有狀態兩種情況:
無狀態的計算觀察每個獨立事件,并根據最后一個事件輸出結果。例如,流處理應用程序從傳感器接收溫度讀數,并在溫度超過90度時發出警告。
有狀態的計算則會基于多個事件輸出結果。
數據處理容錯及一致性保障
在有狀態的數據處理中,如何保障數據的一致性是一個關鍵點。保障一致性的方式有以下三種:
at most once:這其實是沒有正確性保障的委婉說法——故障發生之后,計數結果可能丟失
at least once:這表示計數結果可能大于正確值,但絕不會小于正確值。也就是說,計數程序在發生故障后可能多算,但是絕不會少算
exactly once:這指的是系統保證在發生故障后得到的計數結果與正確值一致
Flink如何保證exactlyonce呢?它使用一種被稱為“檢查點”的特性,在出現故障時將系統重置回正確狀態。
有限流處理是無限流處理的一種特殊情況,它只不過在某個時間點停止而已。此外,如果計算結果不在執行過程中連續生成,而僅在末尾處生成一次,那就是批處理(分批處理數據)
原文標題:流式計算、數據處理及相關技術
文章出處:【微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
人工智能
+關注
關注
1791文章
47344瀏覽量
238730 -
機器學習
+關注
關注
66文章
8421瀏覽量
132710
原文標題:流式計算、數據處理及相關技術
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論