") 如何在C代碼中插入寄存器?
如何在C代碼中插入寄存器?
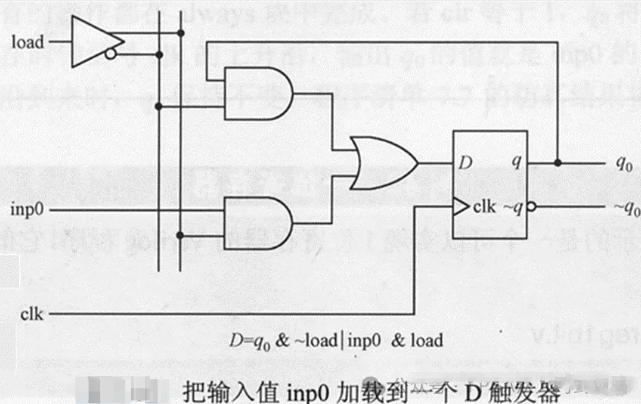
對(duì)于邏輯級(jí)數(shù)較高的路徑,常用的方法之一是在其中插入流水寄存器,將路徑打斷,從而降低邏輯延遲,這在HDL代碼中實(shí)現(xiàn)起來比較容易。此外,從RTL代碼風(fēng)格角度講,對(duì)于關(guān)鍵模塊,設(shè)計(jì)時(shí)常將其輸入/輸出端口寄存。這起到了隔離關(guān)鍵路徑的作用。
但是,如果使用的RTL代碼是HLS轉(zhuǎn)換生成的,例如使用Vitis HLS綜合的,其可讀性較差,想要在其生成的HDL代碼中插入寄存器就變得比較困難。為此,我們想到了能否在C代碼中插入寄存器,并保證Vitis HLS綜合后的結(jié)果是寄存器。
這要解決四個(gè)問題:一是這樣的C代碼要具備一定的可復(fù)用性,比如,以模板函數(shù)的形式呈現(xiàn)。二是這樣的C代碼是參數(shù)化的,尤其是數(shù)據(jù)類型,因?yàn)樾枰拇娴臄?shù)據(jù)其數(shù)據(jù)類型不盡相同。這仍然可以借助模板函數(shù)實(shí)現(xiàn)。三是保證這個(gè)函數(shù)不被優(yōu)化合并掉。因?yàn)檫@個(gè)函數(shù)功能比較單一,輸出等于輸入,這就要用到INLINE的功能。四是C語言是不具備時(shí)序特征的,要實(shí)現(xiàn)輸出與輸入的延遲,就要借助相應(yīng)的pragma,我們想到了Latency。
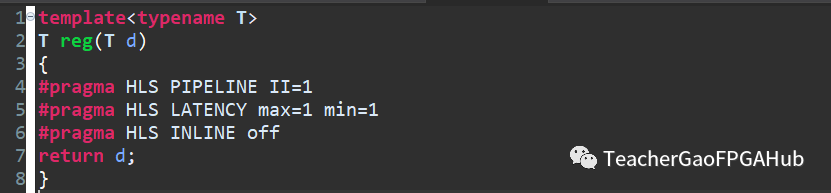
在此基礎(chǔ)上,我們構(gòu)造了下面的C++代碼。不難看出,這是一個(gè)模板函數(shù),數(shù)據(jù)類型是參數(shù)化的,使用了三個(gè)pragma。其中PIPELINE用于限定II為1,LATENCY用于限定延遲為1,INLINE用于防止該函數(shù)被合并。
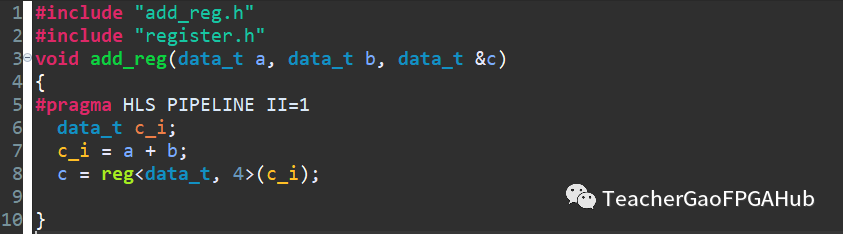
看一個(gè)具體的使用案例,如下圖所示代碼。功能很簡(jiǎn)單,就是實(shí)現(xiàn)兩個(gè)數(shù)的相加。這里對(duì)兩個(gè)輸入數(shù)據(jù)a和b分別做了寄存,同時(shí)對(duì)結(jié)果c也做了寄存。最終的綜合報(bào)告顯示Latency為2,和我們預(yù)期的一致。對(duì)于生成的HDL代碼,將其添加到Vivado中進(jìn)行綜合,綜合后的結(jié)果也是符合預(yù)期的。


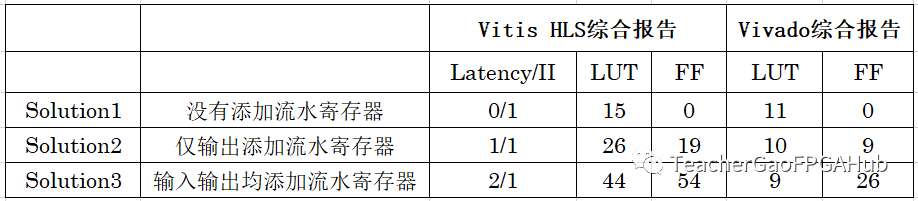
這里,我們對(duì)比一下三種情形。情形1:不添加流水寄存器;情形2:僅對(duì)輸出添加流水寄存器;情形3:輸入輸出均添加流水寄存器。Vitis HLS綜合結(jié)果以及其生成的HDL代碼在Vivado下的綜合結(jié)果對(duì)比如下圖所示。首先,可以看到Latency符合預(yù)期,同時(shí)II始終為1;其次,Vivado下綜合后的資源利用率與Vitis HLS的結(jié)果是不一致的。這一點(diǎn)也很容易理解,因?yàn)閂ivado綜合時(shí)會(huì)有很多優(yōu)化。
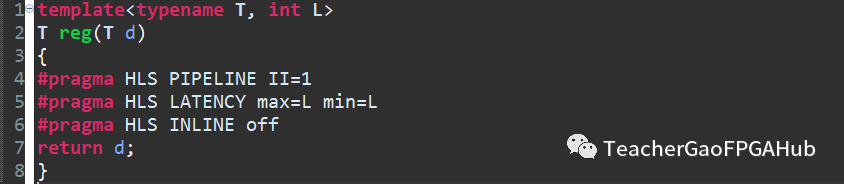
進(jìn)一步,我們看到這里的延遲為1,如果需要兩級(jí)延遲,就要兩次調(diào)用模板函數(shù)。能否將延遲的時(shí)鐘周期也設(shè)置成參數(shù)呢?答案是肯定的,如下圖代碼所示。這里定義了L,用來管理延遲的時(shí)鐘周期個(gè)數(shù),對(duì)應(yīng)pragma Latency的min和max值。
原文標(biāo)題:在C代碼中插入寄存器
文章出處:【微信公眾號(hào):Lauren的FPGA】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
寄存器
+關(guān)注
關(guān)注
31文章
5357瀏覽量
120697 -
C語言
+關(guān)注
關(guān)注
180文章
7608瀏覽量
137157 -
代碼
+關(guān)注
關(guān)注
30文章
4803瀏覽量
68755
原文標(biāo)題:在C代碼中插入寄存器
文章出處:【微信號(hào):Lauren_FPGA,微信公眾號(hào):FPGA技術(shù)驛站】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
ADS1299如何在寄存器中配置右腿驅(qū)動(dòng)?
PCM5142如何在FPGA中通過SPI配置寄存器?
寄存器間接尋址和寄存器尋址的區(qū)別
微處理器中寄存器的作用
寄存器的類型和作用
寄存器的輸入輸出方式
寄存器故障分析
寄存器是什么意思?寄存器是如何構(gòu)成的?
寄存器尋址和直接尋址的區(qū)別
寄存器尋址的實(shí)現(xiàn)方式
寄存器分為基本寄存器和什么兩種
如何根據(jù)自己設(shè)計(jì)中的寄存器配置總線定義來生成一套寄存器配置模版





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論