 微軟DeBERTa登頂SuperGLUE排行榜
微軟DeBERTa登頂SuperGLUE排行榜
在最新的 NLU 測試基準 SuperGLUE 中,微軟提出的 DeBERTa 登頂榜單,并超越人類。
去年 6 月,來自微軟的研究者提出一種新型預訓練語言模型 DeBERTa,該模型使用兩種新技術改進了 BERT 和 RoBERTa 模型。8 月,該研究開源了模型代碼,并提供預訓練模型下載。最近這項研究又取得了新的進展。 微軟最近通過訓練更大的版本來更新 DeBERTa 模型,該版本由 48 個 Transformer 層組成,帶有 15 億個參數。本次擴大規模帶來了極大的性能提升,使得單個 DeBERTa 模型 SuperGLUE 上宏平均(macro-average)得分首次超過人類(89.9 vs 89.8),整體 DeBERTa 模型在 SuperGLUE 基準排名中居于首位,以 90.3 的得分顯著高出人類基線(89.8)。目前該模型以 90.8 的宏平均(macro-average)得分高居 GLUE 基準排名的首位。
SuperGLUE 排行榜,2021 年 1 月 6 日。 DeBERTa 是一種基于 Transformer,使用自監督學習在大量原始文本語料庫上預訓練的神經語言模型。像其他 PLM 一樣,DeBERTa 旨在學習通用語言表征,可以適應各種下游 NLU 任務。DeBERTa 使用 3 種新技術改進了之前的 SOTA PLM(例如 BERT、RoBERTa、UniLM),這 3 種技術是:
分解注意力(disentangled attention)機制;
增強型掩碼解碼器;
一種用于微調的虛擬對抗訓練方法。
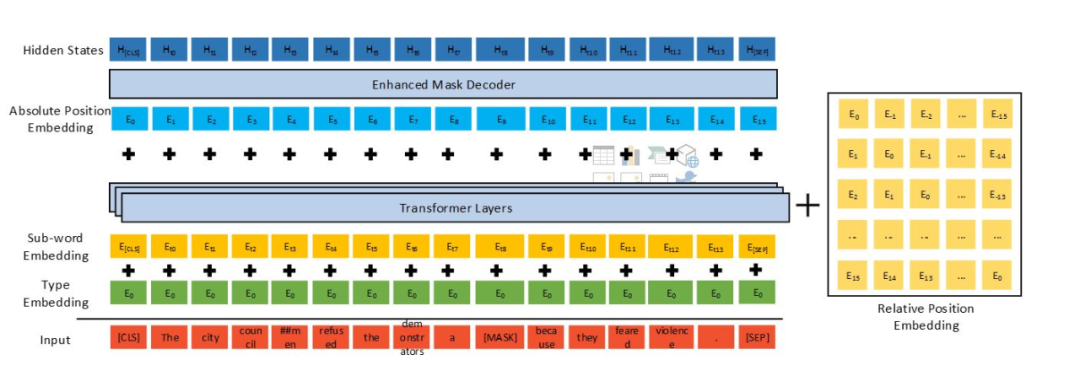
DeBERTa 的架構。 最近該研究在 arXiv 上提交了 DeBERTa 的最新論文,文中詳細介紹了 DeBERTa 模型的方法及最新的實驗結果。
論文鏈接:https://arxiv.org/pdf/2006.03654v2.pdf 下面我們來詳細看一下該模型用到的 3 種新技術。 分解注意力機制 與 BERT 不同,DeBERTa 中每個詞使用兩個對其內容和位置分別進行編碼的向量來表示,使用分解矩陣分別根據詞的內容和相對位置來計算詞間的注意力權重。采用這種方法是因為:詞對的注意力權重(衡量詞與詞之間的依賴關系強度)不僅取決于它們的內容,還取決于它們的相對位置。例如,「deep」和「learning」這兩個詞在同一個句子中接連出現時的依賴關系要比它們出現在不同句子中強得多。 增強型掩碼解碼器 與 BERT 一樣,DeBERTa 也使用掩碼語言建模(MLM)進行了預訓練。DeBERTa 將語境詞的內容和位置信息用于 MLM。分解注意力機制已經考慮了語境詞的內容和相對位置,但并沒有考慮這些詞的絕對位置,但這在很多情況下對于預測至關重要。 例如句子「a new store opened beside the new mall」其中,「store」和「mall」在用于預測時被掩碼操作。盡管兩個詞的局部語境相似,但是它們在句子中扮演的句法作用是不同的。(例如,句子的主角是「store」而不是「mall」)。
這些句法上的細微差別在很大程度上取決于詞在句子中的絕對位置,因此考慮單詞在語言建模過程中的絕對位置是非常重要的。DeBERTa 在 softmax 層之前合并了絕對詞位置嵌入,在該模型中,模型根據詞內容和位置的聚合語境嵌入對被掩碼的詞進行解碼。 規模不變的微調 虛擬對抗訓練是一種提升模型泛化性的正則化方法。它通過提高模型對對抗樣本(adversarial examples)的魯棒性來實現這一點,其中對抗樣本是通過對輸入進行細微的干擾而創建的。對模型進行正則化,以便在給出一種特定任務樣本時,該模型產生的輸出分布與在該樣本的對抗型干擾版本上產生的輸出分布相同。對于 NLU 任務,干擾被用于詞嵌入,而不是原始的詞序列。
但是,嵌入向量的值范圍(范數)在不同的詞和模型上有所不同。對于具有數十億個參數的較大模型,方差會比較大,從而導致對抗訓練不穩定性。受層歸一化的啟發,為了提高訓練穩定性,該研究開發了一種規模不變的微調(Scale-Invariant-Fine-Tuning (SiFT))方法,該方法將干擾用于歸一化的詞嵌入。 實驗 該研究用實驗及結果評估了 DeBERTa 在 NLU 和 NLG 的各種 NLP 任務上的性能。 在 NLU 任務上的主要結果 受此前 BERT、 RoBERTa 和 XLNet 等論文的影響,該研究使用大型模型和基礎模型進行結果展示。 大型模型性能結果如下表所示:
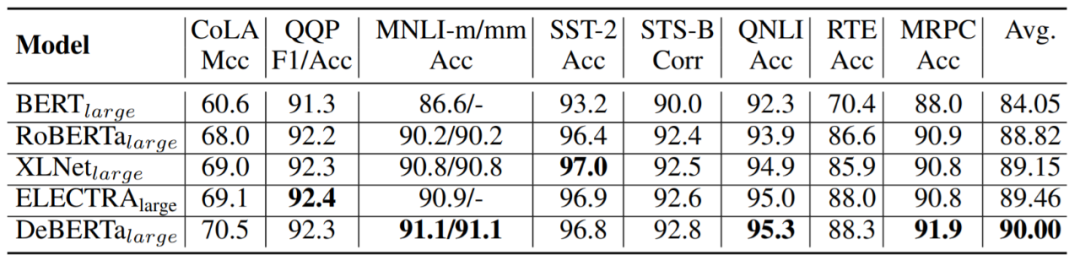
表 1:在 GLUE 開發集上的結果對比。 表 1 總結了 8 個 GLUE 任務的結果,其中將 DeBERTa 與具有類似 transformer 結構的一些模型進行了比較,這些模型包括 BERT、 RoBERTa、XLNet、ALBERT 以及 ELECTRA。注意,RoBERTa、 XLNet 以及 ELECTRA 訓練數據的大小為 160G,而 DeBERTa 訓練數據大小為 78G。 該研究還對 DeBERTa 進行了一些其他的基準評估:
問答:SQuAD v1.1、SQuAD v2.0、RACE、ReCoRD 以及 SWAG;
自然語言推理:MNLI;
命名體識別(NER):CoNLL-2003。
結果如表 2 所示。
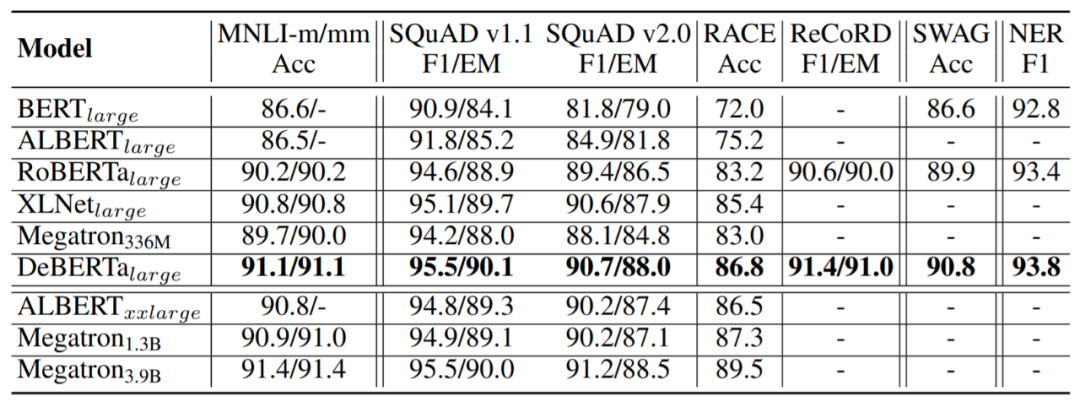
表 2:在 MNLI in/out-domain、 SQuAD v1.1、 SQuAD v2.0、 RACE、 ReCoRD、 SWAG、 CoNLL 2003 NER 開發集上的結果展示。 基礎模型性能比較 基礎模型預訓練的設置與大型模型的設置類似,基礎模型結構遵循 BERT 的基礎模型結構,性能評估結果如表 3 所示。

表 3:在 MNLI in/out-domain (m/mm)、SQuAD v1.1 和 v2.0 開發集上的結果對比。 生成任務結果比較 該研究在數據集 Wikitext-103 上,進一步對帶有自回歸語言模型 (ARLM) 的 DeBERTa 模型進行了評估。

表 4:在 Wikitext-103 數據集上,不同語言模型對比結果。 DeBERTa_base 在開發集和測試集上都獲得了比較好的 PPL 結果,MLM 和 ARLM 聯合訓練進一步降低了 PPL,這展示了 DeBERTa 的有效性。 模型分析 消融實驗:為了驗證實驗設置,該研究從頭開始預訓練 RoBERTa 基礎模型。并將重新預訓練的 RoBERTa 稱為 RoBERTa-ReImp_base。為了研究 DeBERTa 模型不同部分對性能的影響,研究人員設計了三種變體:
EMD 表示沒有 EMD 的 DeBERTa 基礎模型;
C2P 表示沒有內容到位置 term 的 DeBERTa 基礎模型;
P2C 表示沒有位置到內容 term 的 DeBERTa 基礎模型。由于 XLNet 也使用了相對位置偏差,所以該模型與 XLNet + EMD 模型比較接近。

表 5 總結了 DeBERTa 基礎模型消融實驗在四個基準數據集上的結果。 預訓練效率 為了研究模型預訓練的收斂性,該研究以預訓練 step 數的函數的形式可視化微調下游任務的性能,如圖 1 所示,對于 RoBERTa ReImp 基礎模型和 DeBERTa 基礎模型,該研究每 150K 個預訓練 step 存儲一個檢查點,然后對兩個有代表性的下游任務(MNLI 和 SQuAD v2.0)上的檢查點進行微調,之后分別報告準確率和 F1 得分。
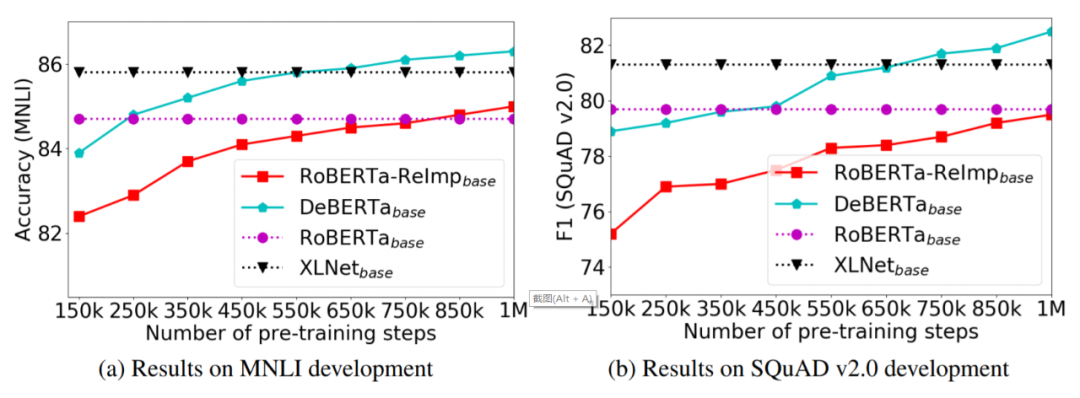
圖 1:DeBERTa 及其相似模型在 MNLI 、 SQuAD v2.0 開發集上的預訓練性能曲線。 擴展至 15 億參數 更大的預訓練模型會顯示出更好的泛化結果。因此,該研究建立了一個擁有 15 億個參數的 DeBERTa,表示為 DeBERTa_1.5B,該模型有 48 層。在 160G 預訓練數據集上訓練 DeBERTa_1.5B,并且使用數據集構造了一個大小為 128K 的新詞匯表。
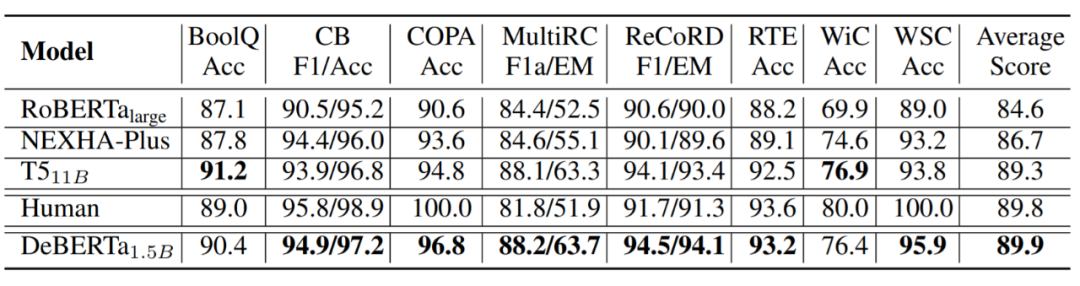
表 6:DeBERTa_1.5B 和其他幾種模型在 SuperGLUE 測試集上的結果。
原文標題:NLU新里程碑,微軟DeBERTa登頂SuperGLUE排行榜,顯著超越人類
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
微軟
+關注
關注
4文章
6591瀏覽量
104027 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100720
原文標題:NLU新里程碑,微軟DeBERTa登頂SuperGLUE排行榜,顯著超越人類
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
潤和軟件榮登2024智慧金融企業排行榜單
調用云數據庫更新排行榜單
2024年激光位移傳感器品牌排行榜前十最新名單

IBM入選2024世界物聯網500強排行榜
博泰車聯網五度蟬聯“世界物聯網排行榜500強企業”
安全光幕十大品牌排行榜最新2024年


HarmonyOS開發案例:【排行榜頁面】
2023工業機器人排行榜發布

銳成芯微再次榮登中國IC設計排行榜TOP 10 IP公司榜單

敏芯股份再次入選中國IC設計排行榜TOP10傳感器公司

炬芯科技上榜2024中國IC設計Fabless 100排行榜之TOP10無線連接公司

中穎電子入選Fabless 100排行榜TOP10微控制器公司榜單







 工商網監
工商網監
評論