 如何處理服務存在內存泄漏問題?
如何處理服務存在內存泄漏問題?
上周像往常一樣例行檢查線上機器性能,突然發現一個服務的內存使用率是這樣的:
很顯然該服務存在內存泄漏問題,趕緊排查問題。
問題排查
首先確定內存泄漏問題出現的時間,發現在該時間點的上線有兩次代碼提交,其中一個就是我的。于是立刻排查這兩次代碼的改動,確定了另一個同事的代碼不可能會有內存問題后(因為另一個同事的上線僅僅修改了配置)我知道肯定是自己的代碼出現了問題。
確定了問題所在后趕緊把自己的代碼回滾掉,接下來就可以放心debug了。
Debug
什么是內存泄漏?
簡單的講就是程序員申請的內存在使用完后沒有還給操作系統,由于筆者使用的是C++語言,因此內存泄漏一般是這樣的:
obj* o = new obj(); ... // 使用完obj后沒有delete掉
肯定有什么地方申請了內存后沒有調用delete釋放內存。
在這里介紹一下筆者的代碼改動,我的任務其實是重構一段代碼,把這段代碼并行化。也就是舊的邏輯是在一個線程中串行執行的,現在我要把這段邏輯放到兩個線程中并行執行,這是最讓人頭疼的任務之一,并行化改造是比較容易出bug的。
接下來梳理了一遍中所有內存的申請和釋放,這其中包括:
使用new/delete分配釋放的內存
使用內存池分配釋放的內存
仔細梳理一遍后沒有發現任何問題,該釋放的內存都已經釋放掉了,這時筆者已經開始懷疑人生了 :) ,很顯然還有一段沒有注意到的地方出現了問題,這是必然的,雖然知道問題必然出現在改動的這些代碼里但是我并不能確定出現的位置。
沒有辦法,到這里基本上已經要放棄自己人肉debug了,想利用一些內存檢測工具來幫助自己確定問題。
常見的內存泄漏檢測工具包括valgrind、gperftools等,valgrind的好處在于無需重新編譯代碼即可進行內存檢測,但是缺點是會使得程序運行非常緩慢,官方文檔給的說法是會比正常的程序運行慢20-30倍;gperftools則需要重新編譯可執行程序。這些工具需要下載安裝測試,其中還涉及到申請機器權限等問題,筆者覺得還是比較麻煩,況且這個問題也不是大海撈針一樣,問題肯定出在了并行化的這段代碼中。
到這里我決定再換一個思路來排查問題,既然代碼重構后開始并行執行,那么出現問題大概率是因為多線程問題,遇到多線程問題首先重點排查的就是線程間的共享數據。
多線程問題的關鍵——共享數據
我們知道如果線程之間沒有共享數據那么就不會有線程安全問題,我們使用的鎖、信號量、條件變量等其實都是用來保護共享數據的,比如鎖通常是用來包括臨界區的,臨界區中的代碼操作的就是線程共享數據;信號量使用的一個經典場景就是生產者消費者問題,生產者線程以及消費者線程都會操作同一個隊列,這里的隊列就是共享數據。
沿著這個思路開始找在兩個線程中都使用到的共享數據,果不其然,在一個角落中發現了這樣一段代碼:
auto* pb = global->mutable_obj();
這是分配protobuf對象的一段代碼,protobuf是Google開發是一種類似于JSON、XML的技術,因此常用于網絡通信和數據交換等場景,比如RPC等。
如果你不了解protobuf也沒有關系,實際上上面的這段代碼的要做的事情是這樣的:
if (global->obj == NULL) { global->obj = new obj();}return global->obj;
值得注意的是這段代碼現在會在兩個線程中執行,顯然問題就出現在了這里。
那么問題是怎么出現的呢?
我們假設有兩個線程,線程A和線程B,當這樣一段代碼在線程AB中同時執行時可能會有以下場景:
線程A拿到global->obj并檢測到此時的global->obj為空,因此決定為其分配內存,但不巧的是此時發生線程切換,線程A在為global->obj分配內存前被暫停運行,如下所示:
if (global->obj == NULL) { <------- 線程切換,線程A被暫停執行 global->obj = new obj();}return global->obj;
線程A被暫停運行后線程B開始執行,這段代碼同樣會在線程B中執行一遍,因此線程B會首先檢查global->obj發現為空,因此為global->obj分配內存,分配完內存后發生線程切換,線程B被暫停運行,如下所示:
if (global->obj == NULL) { global->obj = new obj(); <------- 線程切換,線程B被暫停執行 }return global->obj;
線程B被暫停運行后調度器決定重新運行線程A,此時線程A開始從被中斷的地方繼續運行,還記得線程A是從哪里被中斷的嗎,沒錯,就是在為global->obj分配內存前被中斷的,此時線程A繼續運行,也就是說global->obj = new obj()這段代碼又被執行了一次,雖然線程B已經為global->obj分配了內存。
Oops,典型的內存泄漏,線程B分配的內存再也無法被正常釋放掉了。
至此,我們已經找到了問題的原因,罪魁禍首就是共享數據,關鍵的一點是要意識到你的線程會隨時被中斷執行,CPU會隨時切換到其它線程。
代碼修復也非常簡單,再新增一個變量,兩個線程不在使用共享數據,到這里問題就解決了,從發現問題到完成修復耗時大概4小時。
經驗教訓
代碼的并行化重構是一件非常棘手的任務,很容易出現線程安全問題,解決線程安全問題首先要考慮的不是要不要加鎖,而是多個線程是否真的有必要使用共享數據,沒有必要的話多個線程操作私有數據根本就不會出現線程安全問題。
當出現線程安全問題時,第一時間重點排查線程使用的共享數據。
內存泄漏檢測工具
雖然這些沒有使用檢測工具全靠人肉debug其實還是因為問題排查范圍比較小,如果我們根本就不知道問題出現在了那次代碼改動那么檢測工具就非常重要了,在這里簡單介紹一下valgrind的使用,詳細的介紹請參考官方文檔。
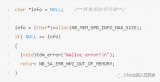
假設有這樣一段問題代碼:
#include
這段代碼中有兩個問題:一個是數據的越界訪問;另一個是內存泄漏。將該程序編譯為myprog。
接下來使用valgrind來檢查該程序,使用以下命令:
valgrind --leak-check=yes myprog
運行完成后valgrind會給出檢測報告,關于程序越界訪問會給出這樣的輸出:
==19182== Invalid write of size 4==19182== at 0x804838F: f (example.c:6)==19182== by 0x80483AB: main (example.c:11)==19182== Address 0x1BA45050 is 0 bytes after a block of size 40 alloc'd==19182== at 0x1B8FF5CD: malloc (vg_replace_malloc.c:130)==19182== by 0x8048385: f (example.c:5)==19182== by 0x80483AB: main (example.c:11)
第一行告訴你代碼中存在Invalid write,也就是無效的寫,并給出了問題出現的位置。
關于內存泄漏問題會給出這樣的輸出:
==19182== 40 bytes in 1 blocks are definitely lost in loss record 1 of 1==19182== at 0x1B8FF5CD: malloc (vg_replace_malloc.c:130)==19182== by 0x8048385: f (example.c:5)==19182== by 0x80483AB: main (example.c:11)
這里第一行報告了內存"definitely lost",也就是說一定會存在內存泄漏,并給出了問題出現的位置。
實際上除了"definitely lost",valgrind還會給出"probably lost"的報告,這兩種報告的含義是這樣的:
"definitely lost":你的程序一定存在內存泄漏問題,修復。
"probably lost":你的程序看起來像是有內存泄漏,有可能你在使用指針完成一些特定操作,因此不一定100%存在問題。
原文標題:一個耗時4小時的內存泄漏問題
文章出處:【微信公眾號:玩轉單片機】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
數據
+關注
關注
8文章
7004瀏覽量
88944 -
服務器
+關注
關注
12文章
9124瀏覽量
85331 -
內存
+關注
關注
8文章
3019瀏覽量
74008
原文標題:一個耗時4小時的內存泄漏問題
文章出處:【微信號:mcu168,微信公眾號:硬件攻城獅】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
服務器cpu占用率高怎么解決
請問比較器不用的引腳如何處理比較好?
如何檢測內存泄漏
NONOS 1.5.3/1.5.4 SSL內存泄漏的原因?
使用system_show_malloc()檢查內存泄漏遇到異常怎么解決?
化工廠液體泄漏識別預警算法







 工商網監
工商網監
評論