") 梯度提升算法
梯度提升算法
簡化復(fù)雜的算法
動(dòng)機(jī)
盡管大多數(shù)的Kaggle競賽的獲勝者使用了多個(gè)模型的集成,這些集成的模型中,有一個(gè)必定是各種變體的梯度提升算法。舉個(gè)例子,Kaggle競賽:Safe Driver Prediction:https://www.kaggle.com/c/porto-seguro-safe-driver-prediction/discussion/44629#250927,Michael Jahrer的方案,使用了表示學(xué)習(xí),使用了6個(gè)模型的綜合。1個(gè)LightGBM和5個(gè)神經(jīng)網(wǎng)絡(luò)。盡管他的成功歸功他使用了結(jié)構(gòu)化的數(shù)據(jù)進(jìn)行了半監(jiān)督學(xué)習(xí),梯度提升算法也實(shí)現(xiàn)了非常重要的部分。
盡管GBM使用的非常廣泛,許多使用者仍然把這個(gè)東西當(dāng)做一個(gè)黑盒子算法,只是使用預(yù)編譯好的庫跑一跑。寫這篇文章的目的是簡化復(fù)雜的算法,幫助讀者可以直觀的理解算法。我會(huì)解釋原汁原味的梯度提升算法,然后分享一些變種的鏈接。我基于fast.ai的庫做了一個(gè)決策樹的代碼,然后構(gòu)建了一個(gè)自己的簡單的基礎(chǔ)的梯度提升模型。
Ensemble, Bagging, Boosting的簡單描述
當(dāng)我們使用一個(gè)機(jī)器學(xué)習(xí)技術(shù)來預(yù)測目標(biāo)變量的時(shí)候,造成實(shí)際值和預(yù)測值之間的差別的原因有噪聲,方差和偏差。集成方法能夠幫助減少這些因素(除了噪聲,不可約誤差)。
Ensemble是幾個(gè)預(yù)測器在一起(比如求平均),給出一個(gè)最終的結(jié)果。使用ensemble的原因是許多不同的預(yù)測器預(yù)測同一個(gè)目標(biāo)會(huì)比單個(gè)預(yù)測器的效果要好。Ensemble技術(shù)又可以分成Bagging和Boosting。
Bagging是一個(gè)簡單的ensemble的技術(shù),我們構(gòu)建許多獨(dú)立的預(yù)測器/模型/學(xué)習(xí)器,通過模型平均的方式來組合使用。(如權(quán)值的平均,投票或者歸一化平均)
我們?yōu)槊總€(gè)模型使用隨機(jī)抽樣,所以每個(gè)模型都不太一樣。每個(gè)模型的輸入使用有放回的抽樣,所以模型的訓(xùn)練樣本各不相同。因?yàn)檫@個(gè)技術(shù)使用了許多個(gè)不相關(guān)的學(xué)習(xí)器來進(jìn)行最終的預(yù)測,它通過減少方差來減小誤差。bagging的一個(gè)例子是隨機(jī)森林模型。
Boosting在對(duì)模型進(jìn)行ensemble的時(shí)候,不是獨(dú)立的,而是串行的。
這個(gè)技術(shù)使用了這樣的邏輯,后面的預(yù)測器學(xué)習(xí)的是前面的預(yù)測器的誤差。因此,觀測數(shù)據(jù)出現(xiàn)在后面模型中的概率是不一樣的,誤差越大,出現(xiàn)的概率越高。(所以觀測數(shù)據(jù)不是基于隨機(jī)又放回抽樣bootstrap的方式,而是基于誤差)。預(yù)測器可以從決策樹,回歸器,分類器中選取。因?yàn)樾碌念A(yù)測器是從前面的預(yù)測器的誤差中學(xué)習(xí)的,接近實(shí)際的預(yù)測只需要更少的時(shí)間和迭代次數(shù)。但是我們不得不選擇嚴(yán)格的停止策略,否則可能會(huì)出現(xiàn)過擬合。梯度提升算法就是提升算法的一個(gè)例子。
Fig 1.Ensembling
Fig 2.Bagging (independent models) & Boosting (sequential models).Reference:https://quantdare.com/what-is-the-difference-between-bagging-and-boosting/
梯度提升算法
梯度提升是一個(gè)機(jī)器學(xué)習(xí)技術(shù),用來做回歸和分類的問題,通過組合弱預(yù)測模型如決策樹,來得到一個(gè)強(qiáng)預(yù)測模型。(維基百科定義)
監(jiān)督學(xué)習(xí)算法的目標(biāo)是定義一個(gè)損失函數(shù),然后最小化它。我們來看看,數(shù)學(xué)上梯度提升算法是怎么工作的。比如我們使用均方誤差(MSE)作為損失函數(shù):
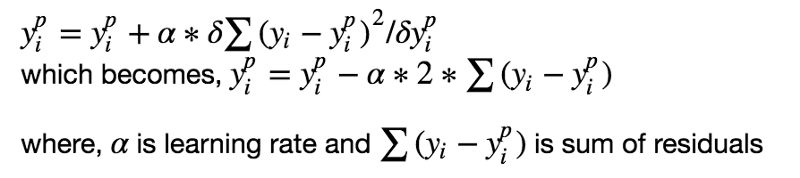
我們希望我們的預(yù)測讓我們的損失函數(shù)最小。通過使用梯度提升算法,基于一個(gè)學(xué)習(xí)率來更新我們的預(yù)測,我們會(huì)發(fā)現(xiàn)一個(gè)讓MSE最小的值。

所以,我們基本上是在更新預(yù)測,讓殘差的和接近于0(或者最小),這樣預(yù)測的值就和實(shí)際的值足夠的接近了。
梯度提升背后的直覺
梯度提升背后的邏輯很簡單,(可以很直觀的理解,不用數(shù)據(jù)公式)。我希望讀這篇文章的人能夠熟悉一下簡單的線性回歸模型。
線性回歸模型的一個(gè)基本的假設(shè)是殘差是0,也就是說,參數(shù)應(yīng)該在0的周圍分散。
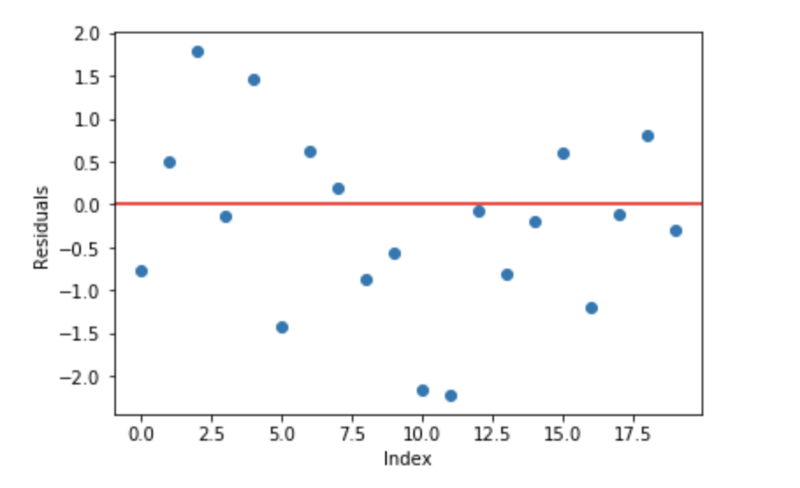
現(xiàn)在,把這些殘差作為誤差提交到我們的預(yù)測模型中。盡管,基于樹的模型(將決策樹作為梯度提升的基礎(chǔ)模型)不是基于這個(gè)假設(shè),但是如果我們對(duì)這個(gè)假設(shè)進(jìn)行邏輯思考,我們也許能提出,如果我們能發(fā)現(xiàn)在0的周圍的殘差一些模式,我們可以利用這個(gè)模式來擬合模型。
所以,梯度提升背后的直覺就是重復(fù)的利用殘差中的模式利用弱預(yù)測器來加強(qiáng)模型,讓模型變得更好。一旦我們到了一個(gè)階段,殘差不具有任何的模式,無法進(jìn)行建模,我們就可以停止了(否則會(huì)導(dǎo)致過擬合)。從算法的角度講,我們在最小化損失函數(shù),直到測試損失達(dá)到最小。
總結(jié)一下:
我們首先使用一個(gè)簡單的模型對(duì)數(shù)據(jù)進(jìn)行建模,分析數(shù)據(jù)的誤差。
這些誤差表示數(shù)據(jù)點(diǎn)使用簡單的模型很難進(jìn)行擬合。
然后對(duì)于接下來的模型,我們特別的專注于將那些難于擬合的數(shù)據(jù),把這些數(shù)據(jù)預(yù)測正確。
最后,我們將所有的預(yù)測器組合起來,對(duì)于每個(gè)預(yù)測器給定一個(gè)權(quán)重。
擬合梯度提升模型的步驟
我們來模擬一些數(shù)據(jù),如下面的散點(diǎn)圖所示,一個(gè)輸入,一個(gè)輸出。
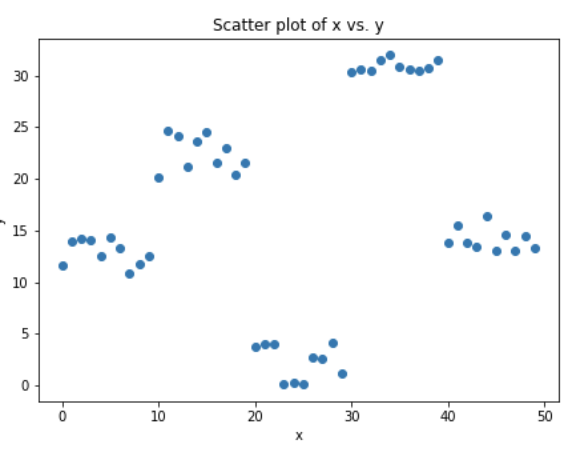
上面的數(shù)據(jù)是通過下面的python代碼生成的。
x = np.arange(0,50) x = pd.DataFrame({'x':x}) # just random uniform distributions in differnt range y1 = np.random.uniform(10,15,10) y2 = np.random.uniform(20,25,10) y3 = np.random.uniform(0,5,10) y4 = np.random.uniform(30,32,10) y5 = np.random.uniform(13,17,10) y = np.concatenate((y1,y2,y3,y4,y5)) y = y[:,None]
1.擬合一個(gè)簡單的線性回歸模型或者決策樹模型(在我的代碼中選擇了決策樹)[x作為輸入,y作為輸出]
xi = x # initialization of input yi = y # initialization of target # x,y --> use where no need to change original y ei = 0 # initialization of error n = len(yi) # number of rows predf = 0 # initial prediction 0 for i in range(30): # loop will make 30 trees (n_estimators). tree = DecisionTree(xi,yi) # DecisionTree scratch code can be found in shared github/kaggle link. # It just create a single decision tree with provided min. sample leaf tree.find_better_split(0) # For selected input variable, this splits (
2.計(jì)算誤差,實(shí)際的目標(biāo)值,最小化預(yù)測目標(biāo)值[e1= y - y_predicted1 ]
3.把誤差作為目標(biāo)值,擬合新的模型,使用同樣的輸入數(shù)據(jù)[叫做e1_predicted]
4.將預(yù)測的誤差加到之前的預(yù)測之中[y_predicted2 = y_predicted1 + e1_predicted]
5.在剩下的殘差上擬合另一個(gè)模型,[e2 = y - y_predicted2],重復(fù)第2到第5步,直到開始過擬合,或者殘差的和開始不怎么變換。過擬合可以通過驗(yàn)證數(shù)據(jù)上的準(zhǔn)確率來發(fā)現(xiàn)。
# predictions by ith decisision tree predi = np.zeros(n) np.put(predi, left_idx, np.repeat(np.mean(yi[left_idx]), r)) # replace left side mean y np.put(predi, right_idx, np.repeat(np.mean(yi[right_idx]), n-r)) # right side mean y predi = predi[:,None] # make long vector (nx1) in compatible with y predf = predf + predi # final prediction will be previous prediction value + new prediction of residual ei = y - predf # needed originl y here as residual always from original y yi = ei # update yi as residual to reloop
為了幫助理解劃線部分的概念,這里有個(gè)鏈接,有完整的梯度提升模型的實(shí)現(xiàn) [[Link: Gradient Boosting from scratch]](https://www.kaggle.com/grroverpr/gradient-boosting-simplified/)。????????????
梯度提升樹的可視化工作
藍(lán)色的點(diǎn)(左邊)是輸入(x),紅色的線(左邊)是輸出(y)顯示了決策樹的預(yù)測值,綠色的點(diǎn)(右邊)顯示了第i次迭代的殘差vs.輸入(x),迭代表示擬合梯度提升樹的了序列的順序。
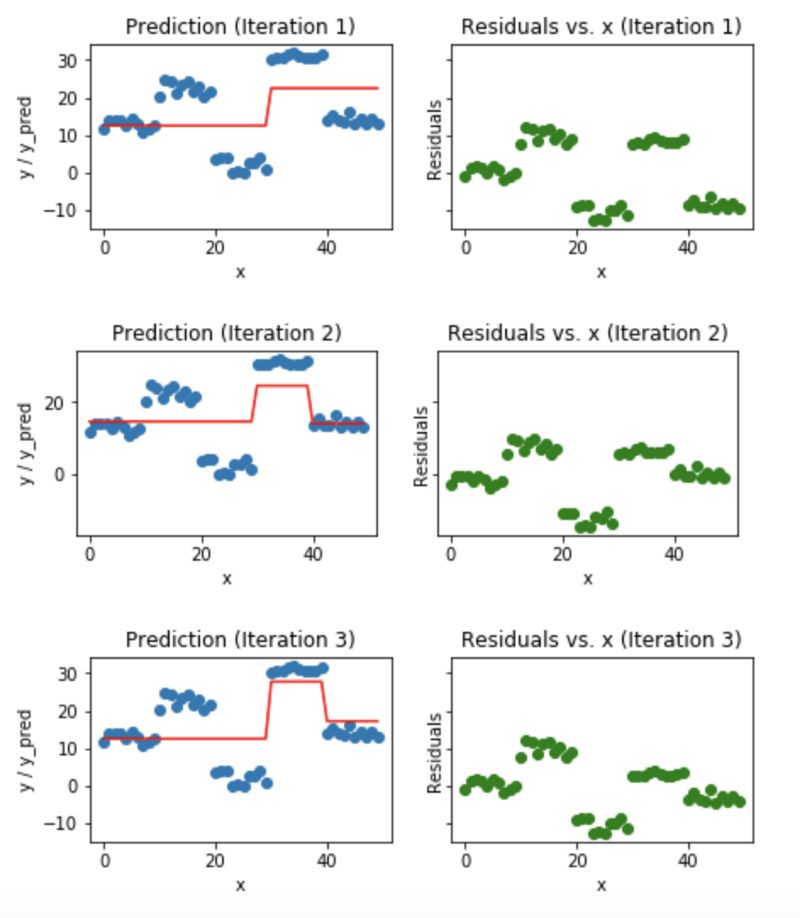
Fig 5.Visualization of gradient boosting predictions (First 4 iterations)
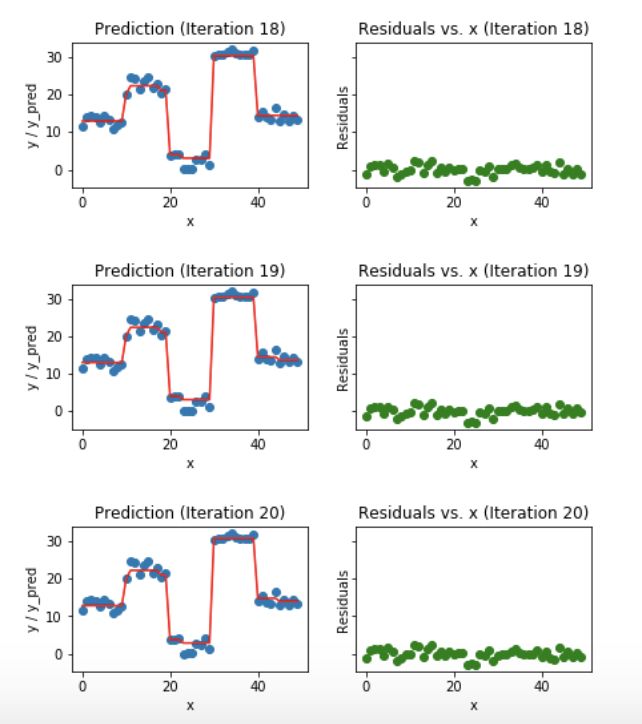
Fig 6.Visualization of gradient boosting predictions (18th to 20th iterations)
我們發(fā)現(xiàn)過了20個(gè)迭代,殘差變成了0附近的隨機(jī)分布(我不會(huì)說是隨機(jī)正態(tài)分布),我們的預(yù)測也非常接近于實(shí)際值。這時(shí)可以停止訓(xùn)練模型了,否則要開始過擬合了。
我們來看看,50個(gè)迭代之后的樣子:
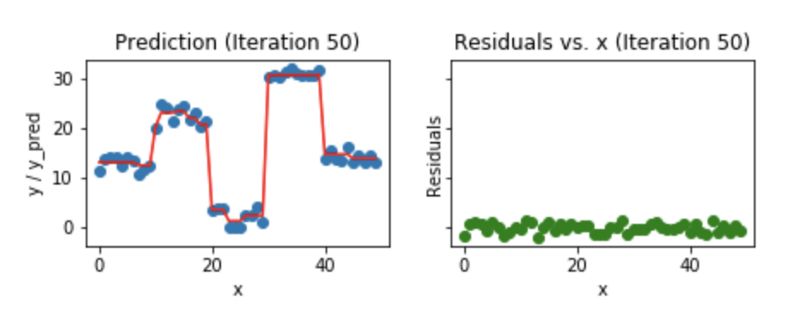
Fig 7. Visualization of gradient boosting prediction (iteration 50th)
我們發(fā)現(xiàn),即使是50個(gè)迭代之后,殘差vs. x的圖和我們看到的20個(gè)迭代的圖也沒太大區(qū)別。但是模型正在變的越來越復(fù)雜,預(yù)測結(jié)果在訓(xùn)練數(shù)據(jù)上出現(xiàn)了過擬合。所以,最好是在20個(gè)迭代的時(shí)候就停止。
用來畫圖的python代碼。
# plotting after prediction xa = np.array(x.x) # column name of x is x order = np.argsort(xa) xs = np.array(xa)[order] ys = np.array(predf)[order] #epreds = np.array(epred[:,None])[order] f, (ax1, ax2) = plt.subplots(1, 2, sharey=True, figsize = (13,2.5)) ax1.plot(x,y, 'o') ax1.plot(xs, ys, 'r') ax1.set_title(f'Prediction (Iteration {i+1})') ax1.set_xlabel('x') ax1.set_ylabel('y / y_pred') ax2.plot(x, ei, 'go') ax2.set_title(f'Residuals vs. x (Iteration {i+1})') ax2.set_xlabel('x') ax2.set_ylabel('Residuals')
我希望這個(gè)博客可以幫助你對(duì)梯度提升算法的工作有一個(gè)基本的直覺。為了理解梯度提升回歸算法的細(xì)節(jié),我強(qiáng)烈建議你讀一讀下面這些文章。
更多有用的資源
我的github倉庫和kaggle的kernel的鏈接,從頭開始GBM
https://www.kaggle.com/grroverpr/gradient-boosting-simplified/https://nbviewer.jupyter.org/github/groverpr/Machine-Learning/blob/master/notebooks/01_Gradient_Boosting_Scratch.ipynb
一個(gè)直觀和細(xì)致的梯度提升算法的解釋
http://explained.ai/gradient-boosting/index.html
Fast.ai的github倉庫鏈接,從頭開始做決策樹
https://github.com/fastai/fastai
Alexander Ihler的視頻,這視頻幫我理解了很多。
https://youtu.be/sRktKszFmSk
最常用的GBM算法
XGBoost || Lightgbm || Catboost || sklearn.ensemble.GradientBoostingClassifier
責(zé)任編輯:lq
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4772瀏覽量
100838 -
算法
+關(guān)注
關(guān)注
23文章
4615瀏覽量
92979 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8422瀏覽量
132714
原文標(biāo)題:【算法理解】從頭開始理解梯度提升算法
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
梯度科技入選2024云原生企業(yè)TOP50榜單
訓(xùn)練RNN時(shí)如何避免梯度消失
梯度科技和廣西大學(xué)計(jì)算機(jī)與電子信息學(xué)院達(dá)成戰(zhàn)略合作
芯片表面溫度梯度對(duì)功率循環(huán)壽命的影響
圖像識(shí)別算法的提升有哪些
中偉視界:智能監(jiān)控和預(yù)警,靜止超時(shí)AI算法如何提升非煤礦山安全?
神經(jīng)網(wǎng)絡(luò)反向傳播算法的優(yōu)缺點(diǎn)有哪些
有源矩陣數(shù)字微流控芯片,用于生成高分辨率濃度梯度

JPEG LS算法局部梯度值計(jì)算原理
功率放大器在聲波截面梯度場的重建及其在聲波場處理中的應(yīng)用
場強(qiáng)是電勢的梯度如何證明
電場強(qiáng)度相等的地方,電勢梯度一定相等嗎
應(yīng)用大模型提升研發(fā)效率的實(shí)踐與探索






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論