


今天早上在reddit上刷到一張非常形象mó xìng的圖,
那就讓我們來整理一下深度學習中離不開的激活函數!
激活函數(Activation Function)是一種添加到人工神經網絡中的函數,旨在幫助網絡學習數據中的復雜模式。類似于人類大腦中基于神經元的模型,激活函數最終決定了要發射給下一個神經元的內容。
在人工神經網絡中,一個節點的激活函數定義了該節點在給定的輸入或輸入集合下的輸出。標準的計算機芯片電路可以看作是根據輸入得到開(1)或關(0)輸出的數字電路激活函數。因此,激活函數是確定神經網絡輸出的數學方程式,本文概述了深度學習中常見的十種激活函數及其優缺點。
首先我們來了解一下人工神經元的工作原理,大致如下:
上述過程的數學可視化過程如下圖所示:
1. Sigmoid 激活函數
Sigmoid 函數的圖像看起來像一個 S 形曲線。
函數表達式如下:
在什么情況下適合使用 Sigmoid 激活函數呢?
Sigmoid 函數的輸出范圍是 0 到 1。由于輸出值限定在 0 到 1,因此它對每個神經元的輸出進行了歸一化;
用于將預測概率作為輸出的模型。由于概率的取值范圍是 0 到 1,因此 Sigmoid 函數非常合適;
梯度平滑,避免「跳躍」的輸出值;
函數是可微的。這意味著可以找到任意兩個點的 sigmoid 曲線的斜率;
明確的預測,即非常接近 1 或 0。
Sigmoid 激活函數有哪些缺點?
傾向于梯度消失;
函數輸出不是以 0 為中心的,這會降低權重更新的效率;
Sigmoid 函數執行指數運算,計算機運行得較慢。
2. Tanh / 雙曲正切激活函數
tanh 激活函數的圖像也是 S 形,表達式如下:
tanh 是一個雙曲正切函數。tanh 函數和 sigmoid 函數的曲線相對相似。但是它比 sigmoid 函數更有一些優勢。
首先,當輸入較大或較小時,輸出幾乎是平滑的并且梯度較小,這不利于權重更新。二者的區別在于輸出間隔,tanh 的輸出間隔為 1,并且整個函數以 0 為中心,比 sigmoid 函數更好;
在 tanh 圖中,負輸入將被強映射為負,而零輸入被映射為接近零。
注意:在一般的二元分類問題中,tanh 函數用于隱藏層,而 sigmoid 函數用于輸出層,但這并不是固定的,需要根據特定問題進行調整。
3. ReLU 激活函數
ReLU 激活函數圖像如上圖所示,函數表達式如下:

ReLU 函數是深度學習中較為流行的一種激活函數,相比于 sigmoid 函數和 tanh 函數,它具有如下優點:
當輸入為正時,不存在梯度飽和問題。
計算速度快得多。ReLU 函數中只存在線性關系,因此它的計算速度比 sigmoid 和 tanh 更快。
當然,它也有缺點:
Dead ReLU 問題。當輸入為負時,ReLU 完全失效,在正向傳播過程中,這不是問題。有些區域很敏感,有些則不敏感。但是在反向傳播過程中,如果輸入負數,則梯度將完全為零,sigmoid 函數和 tanh 函數也具有相同的問題;
我們發現 ReLU 函數的輸出為 0 或正數,這意味著 ReLU 函數不是以 0 為中心的函數。
4. Leaky ReLU
它是一種專門設計用于解決 Dead ReLU 問題的激活函數:
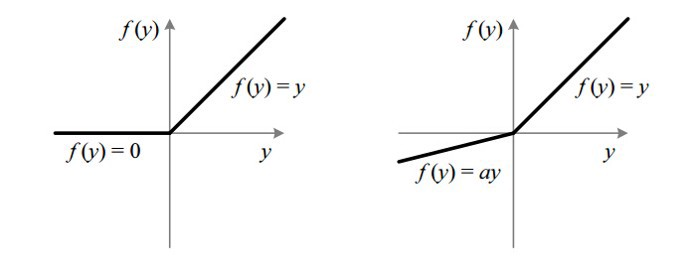
ReLU vs Leaky ReLU
為什么 Leaky ReLU 比 ReLU 更好?
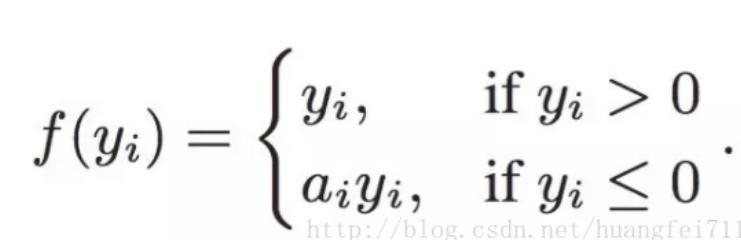
Leaky ReLU 通過把 x 的非常小的線性分量給予負輸入(0.01x)來調整負值的零梯度(zero gradients)問題;
leak 有助于擴大 ReLU 函數的范圍,通常 a 的值為 0.01 左右;
Leaky ReLU 的函數范圍是(負無窮到正無窮)。
注意:從理論上講,Leaky ReLU 具有 ReLU 的所有優點,而且 Dead ReLU 不會有任何問題,但在實際操作中,尚未完全證明 Leaky ReLU 總是比 ReLU 更好。
5. ELU
ELU vs Leaky ReLU vs ReLU
ELU 的提出也解決了 ReLU 的問題。與 ReLU 相比,ELU 有負值,這會使激活的平均值接近零。均值激活接近于零可以使學習更快,因為它們使梯度更接近自然梯度。
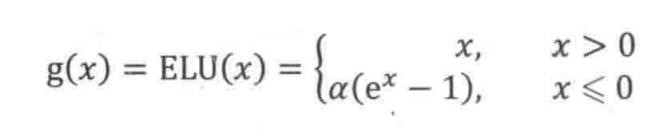
顯然,ELU 具有 ReLU 的所有優點,并且:
沒有 Dead ReLU 問題,輸出的平均值接近 0,以 0 為中心;
ELU 通過減少偏置偏移的影響,使正常梯度更接近于單位自然梯度,從而使均值向零加速學習;
ELU 在較小的輸入下會飽和至負值,從而減少前向傳播的變異和信息。
一個小問題是它的計算強度更高。與 Leaky ReLU 類似,盡管理論上比 ReLU 要好,但目前在實踐中沒有充分的證據表明 ELU 總是比 ReLU 好。
6. PReLU(Parametric ReLU)
PReLU 也是 ReLU 的改進版本:
看一下 PReLU 的公式:參數α通常為 0 到 1 之間的數字,并且通常相對較小。
如果 a_i= 0,則 f 變為 ReLU
如果 a_i》 0,則 f 變為 leaky ReLU
如果 a_i 是可學習的參數,則 f 變為 PReLU
PReLU 的優點如下:
在負值域,PReLU 的斜率較小,這也可以避免 Dead ReLU 問題。
與 ELU 相比,PReLU 在負值域是線性運算。盡管斜率很小,但不會趨于 0。
7. Softmax
Softmax 是用于多類分類問題的激活函數,在多類分類問題中,超過兩個類標簽則需要類成員關系。對于長度為 K 的任意實向量,Softmax 可以將其壓縮為長度為 K,值在(0,1)范圍內,并且向量中元素的總和為 1 的實向量。
Softmax 與正常的 max 函數不同:max 函數僅輸出最大值,但 Softmax 確保較小的值具有較小的概率,并且不會直接丟棄。我們可以認為它是 argmax 函數的概率版本或「soft」版本。
Softmax 函數的分母結合了原始輸出值的所有因子,這意味著 Softmax 函數獲得的各種概率彼此相關。
Softmax 激活函數的主要缺點是:
在零點不可微;
負輸入的梯度為零,這意味著對于該區域的激活,權重不會在反向傳播期間更新,因此會產生永不激活的死亡神經元。
8. Swish
函數表達式:y = x * sigmoid (x)
Swish 的設計受到了 LSTM 和高速網絡中 gating 的 sigmoid 函數使用的啟發。我們使用相同的 gating 值來簡化 gating 機制,這稱為 self-gating。
self-gating 的優點在于它只需要簡單的標量輸入,而普通的 gating 則需要多個標量輸入。這使得諸如 Swish 之類的 self-gated 激活函數能夠輕松替換以單個標量為輸入的激活函數(例如 ReLU),而無需更改隱藏容量或參數數量。
Swish 激活函數的主要優點如下:
「無界性」有助于防止慢速訓練期間,梯度逐漸接近 0 并導致飽和;(同時,有界性也是有優勢的,因為有界激活函數可以具有很強的正則化,并且較大的負輸入問題也能解決);
導數恒 》 0;
平滑度在優化和泛化中起了重要作用。
9. Maxout
在 Maxout 層,激活函數是輸入的最大值,因此只有 2 個 maxout 節點的多層感知機就可以擬合任意的凸函數。
單個 Maxout 節點可以解釋為對一個實值函數進行分段線性近似 (PWL) ,其中函數圖上任意兩點之間的線段位于圖(凸函數)的上方。
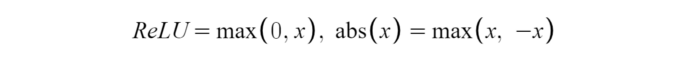
Maxout 也可以對 d 維向量(V)實現:
假設兩個凸函數 h_1(x) 和 h_2(x),由兩個 Maxout 節點近似化,函數 g(x) 是連續的 PWL 函數。
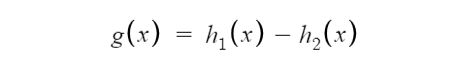
因此,由兩個 Maxout 節點組成的 Maxout 層可以很好地近似任何連續函數。
10. Softplus
Softplus 函數:f(x)= ln(1 + exp x)
Softplus 的導數為
f ′(x)=exp(x) / ( 1+exp? x )
= 1/ (1 +exp(?x ))
,也稱為 logistic / sigmoid 函數。
Softplus 函數類似于 ReLU 函數,但是相對較平滑,像 ReLU 一樣是單側抑制。它的接受范圍很廣:(0, + inf)。
編輯:lyn
-
函數
+關注
關注
3文章
4388瀏覽量
65287 -
深度學習
+關注
關注
73文章
5569瀏覽量
123078
原文標題:深度學習最常用的10個激活函數!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
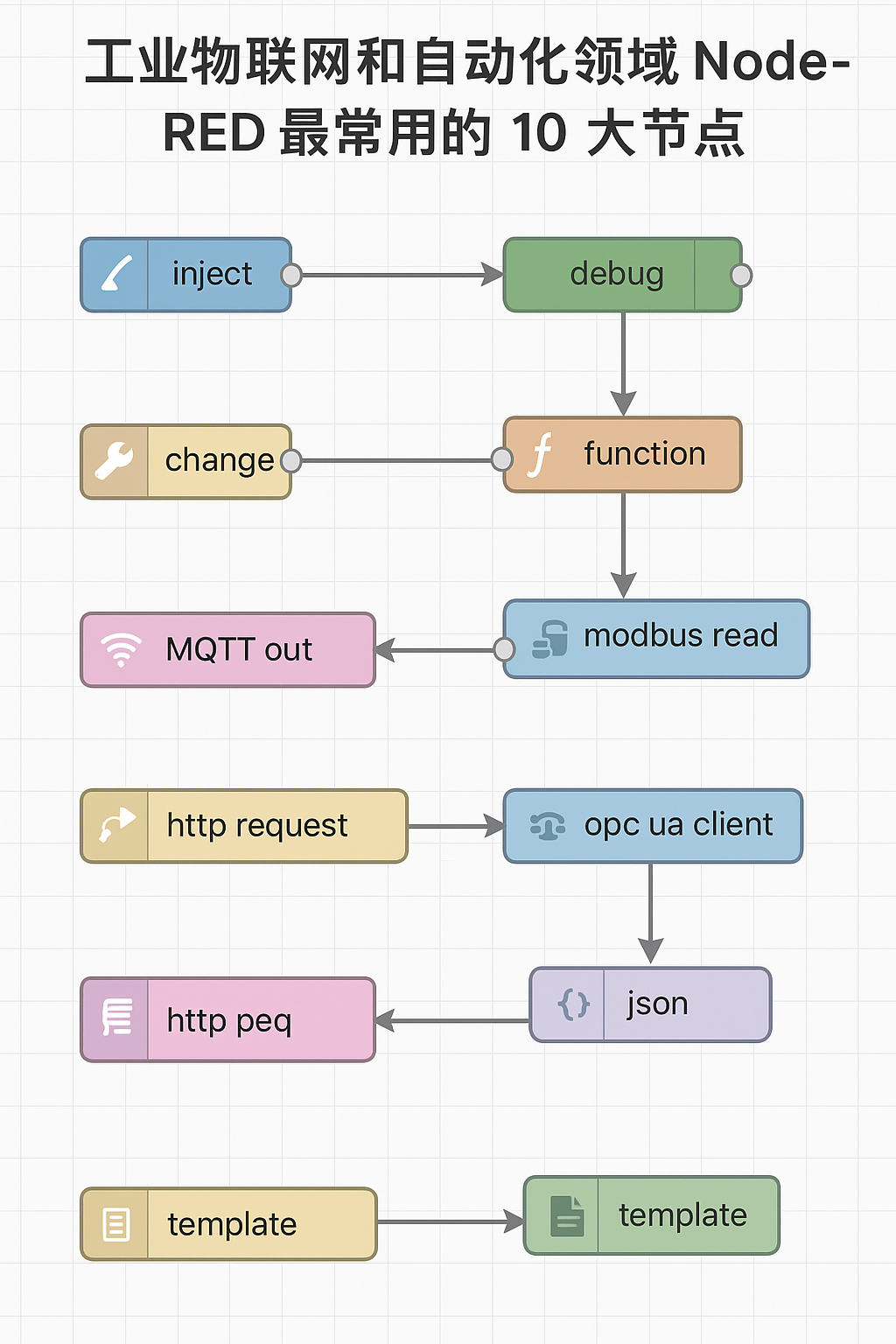
工業物聯網和自動化領域 Node-RED 最常用的 10 大節點,你用過幾個?


深度學習入門:簡單神經網絡的構建與實現
關于4G模組LuatOS開發:通用加解密函數(crypto)|全攻略








 工商網監
工商網監

評論