 基于0MAP5912芯片實現SVM語音識別程序的應用開發
基于0MAP5912芯片實現SVM語音識別程序的應用開發
隨著語音識別和語音合成技術的不斷更新與發展,將語音識別技術應用于嵌入式產品中已得到廣泛應用。SVM(支持向量機)作為統汁概率模型已經被證明是一種很好的識別模型。OMAP5912處理器是由TI公司的TMS320C55X型DSP內核與低功耗、增強型ARM926EJ-S微處理器組成的雙核應用處理器。ARM核可滿足控制和接口方面的需要,DSP核以其低功耗高性能來實現多媒體應用。目前存 0MAP平臺上實現的多媒體應用有語音、音頻、圖像、視頻等。在實驗室開發的基于0MAP5912嵌入式語音識別系統上進行基于SVM的語音識別程序開發。
1 SVM多類分類方法
SVM最初是為處理兩類分類問題而設計的,如何有效地處理多類分類問題目前仍是一個持續研究的課題。采用SVM中的“一對一”方法實現多類分類,下面對這種方法進行簡單介紹。
S.Knerr等在1990年首次介紹了“一對一”方法。J.Friedman在1996年和U KreBel在1999年分別首次在支持向量機中使用這種方法。它需要構造k(k-1)/2個分類器,每個分類器由特定的某兩類訓練樣本訓練得到,判定測試樣本的類別時,結合所有兩類分類器對測試樣本類別的判定意見,采用“投票法”的策略,并認為得票數最多(Max Wins)的類別就是測試樣本所屬的類別。具體如下:考慮K類的分類問題,設訓練集
首先對所有的(i,j)∈{(i,j)|i≤j,i,j=1,…,K}進行運算:從訓練集
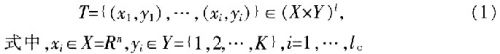
中抽取所有y=i和y=j的樣本點。基于這些樣本點組成一個訓練集Ti-j,每個兩類分類SVM解決問題
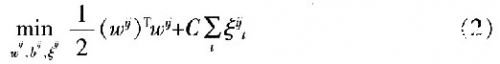
約束條件為:
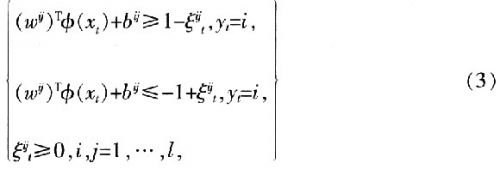
通過求解式(3)的最優化問題得到k(k-1)/2個決策函數,如果函數
![]()
判斷x屬于i類,則i類的得票數增加1;否則j類的得票數增加1。最終判定得票數最多的類別就是測試樣本x所屬的類別。
“一對一”方法的特點是訓練時需要構造k(k-1)/2個分類器,預測時則采用投票選擇策略。這樣做的優點是:每一個分類問題的規模較小,需要求的問題較簡單,樣本數量不很大時訓練速度較快,而且由于類別有較少的重合,改善了樣本拒分、錯分的范同;缺點是:投票法可能存在得票相同的類,即可能存在一個樣本同時屬于多個類的情況。這可以使用其他方法解決,這里重點研究SVM算法在0MAP上的實現。
2 嵌入式系統開發環境的搭建
0MAP5912處理器是由TI公司的TMS320C55x型DSP內核 (192 MHz)與低功耗、增強型ARM926EJ-S微處理器(192 MHz)組成的雙核應用處理器,采用0.13μm CMOS工藝制造。TMS320C55x型DSP可提供對低功耗應用的實時多媒體處理的支持;ARM926EJ-S MPU可滿足控制和接口方面的處理需要。基于雙核結構的0MAP5912具有極強的運算能力和極低的功耗,采用開放式、易于開發的軟件設施,支持廣泛的操作系統。嵌入式系統開發在解決了硬件平臺的設計和操作系統的搭建后就需要考慮應用程序如何編譯、主機如何與開發板通信、程序如何調試、程序如何下載到開發板這幾個方面的問題。
2.1 通信環境
采用minicom通信終端程序,通過minicom可以設置、監視串口工作狀態,接收、顯示串口收到的信息、并且在宿主機和開發板之間傳遞數據和控制指令,從而實現通過宿主機上調試開發板的目的。
設置minicom參數值如下:“Serial Device”為/dev/ttyrSO(使用串口1);主機串口波特率為:115 200;數據位為:8位;停止位為:1位;奇偶校驗位為:無;數據流控制為:無。完成后保存設置重啟Minicom。
2.2 程序下載環境
在程序開發期間,經常需要把程序下載到開發板上進行測試,采用通用開發模式:將宿主機和開發板通過以太網連接,在宿主機上運行minicom作為開發板的顯示終端,通過NFS(Network File System,網絡文件系統)來掛載宿主機硬盤,讓應用程序直接運行在開發板上。
2.3 交叉編譯環境的建立
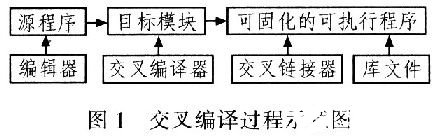
宿主機系統為Ubuntu version 2.6.27,將交叉編譯工具arm-linux-gcc-3.4.1解壓縮到/usr/local/arm目錄下,然后在終端執行命令:#gedit/root/.bashrc,修改/root/.bashrc文件,在文件中加入export PATH=“$PATH:/sbin:/usr/local/arm/3.4.1/bin:/usr/local/bin:/usr/local”,最后在終端執行命令#source.bashrc.至此,交叉編譯環境搭建完成。資源文件和庫文件都
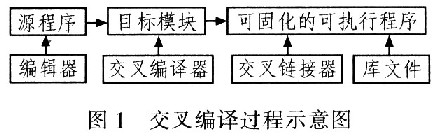
安裝在/usr/local/arm/3.4.1/arm-linux目錄下。交叉編譯過程如圖l所示。
2.4 安裝NFS《Network File System)
在開發階段采用NFS比較方便,這樣開發板的根文件系統可以放在宿主機上,然后通過NFS來掛載和運行。內核同樣也可放在宿主機上,然后由引導器使用 TFTP(Trivial FileTransferProtocol)協議通過以太網來獲取。開發板同時具有以太網口和串口,且以太網連接的傳輸速度遠比串口連接要快,因此,用以太網接口下載內核和根文件系統,而串口作為調試和控制臺來使用。
2.4.1安裝NFS
Ubuntu上默認是沒有NFS服務的,首先要安裝NFS服務程序,#sudo apt-get install nfs-kernel-server,使宿主機相當于NFS服務器。同樣地,開發板作為NFS的客戶端,需要安裝NFS客戶端程序:#sudo apt-get install nfs-commmon。
2.4.2 配置portmap服務
nfs-common和nfs-kernel-setver都依賴于portmap,所以需要配置portmap。#sudo dpkg-reconfigure portmap,對Shouldportmap be bound to the loopback address?選N。
在/etc/hosts.deny和/etc/hosts.allow兩文件中設置對portmap的訪問:首先在/etc/hosts.deny中,禁止所有用戶對portmap的訪問,然后在/etc/hosts.allow中,允許特定用戶對portmap進行訪問。文件修改完后執行#sudo/etc/init.d/pottmap restart,重啟portmap daemon使改動后的內容生效。
2.4.3 配置/etc/exports
NFS掛載目錄及權限由/etc/expotts文件定義。在該文件最后添加語句:
/data/rootfs2.6 192.168.0.*(rw,sync,no_root_squash)
使192.168.O.*網段內的NFS客戶端能夠共享NFS服務器/data/rootfs2.6目錄內容,不僅有瀆寫權限,而且進入/data/rootfs-2.6目錄后的身份為root。更新配置,重啟NFS服務。
#sudo exportfs-r
#sudo/etc/init.d/nfs-kernel-server restait
2.4.4 拷貝根文件系統
拷貝根文件系統到/data/rootfs2.6目錄下,這時就可以啟動minicom,作為虛擬終端,可以通過它來操作開發板。
2.5 修改開發板啟動項
bootargs參數設置Linux系統啟動時掛載在NOR Flash上的JFFS2根文件系統。掛載宿主機上的網絡文件系統,則bootargs參數應設置
setenv bootargs=console=ttyS0,115200n8 noinitrd rw ip=192.168.0.158 root=/dev/nfs nfsroot=192.168.0.204:/data/rootfs2.6.nolock mem=62M
#sayenv保存設置后重啟u-boot,之后將順利進入到開發板,調試應用程序。
3 實驗及結果分析
基于VC++6.0編程實現一種多類分類SVMs算法,PC機環境為Ubuntu version 2.6.27,開發板為Omap5912的ARM926ej-s,其環境為Lin-ux version 2.6.18;Boot Loader采用u-boot version 1.1.6;交叉編譯工具鏈arm-linux-gcc version3.4.1。
采用16個人分別對50個詞的孤立詞發音,在不同信噪比下(15、20、25、30 dB和無噪音)得到的語音數據作為樣本,采用由MFCC特征提取算法得到的特征參數作為識別網絡的輸入。語音信號采樣率為11.025 kHz,幀長N=256點,幀移M=128點。詞匯量分別為10、20、30、40和50個詞。訓練樣本由9人每人對每詞在15、20、25、30 dB、無噪音下發音3次得到。測試樣本由另外7人在相應SNR下對每詞發音3次得到。識別算法采用RBF核函數的SVM算法,采用交叉驗證和網格搜索法進行核參數選擇并建立模型,對測試樣本進行分類識別。核函數參數取最優為(c,y)=(32.0,O.000 122 070 312 5)。實驗結果見表l所示,識別率均在95%以上。表1中同時列出同樣條件下使用HMM識別網絡的識別結果。
HMM模型是典型的語音識別模型,它是目前語音識別效果最好的少數幾種方法之一。在相同特征參數下將SVM與HMM模型進行對比,從實驗結果看出:1)SVM比HMM模型具有更高的識別率;2)比較相同信噪比和詞匯量下的測試精度,可發現HMM模型的測試精度有明顯下降,而SVM的測試結果下降較少,說明SVM比HMM模型具有更強推廣性。
4 結束語
提出一種基于SVM的0MAP5912非特定人嵌入式語音識別系統的實現方法。在搭建的開發環境下運用SVM算法巾的“一對一”方法進行語音識別,獲得良好結果。通過實驗可以得出,對中小詞匯量采用MFCC特征參數,“一對一”SVM作為后端識別方法可以得到較好的識別結果,比傳統的HMM模型有明顯優勢。同時SVM算法作為應用程序集成到0MAP5912嵌入式系統里,存儲量需求小,能夠滿足實用要求。
責任編輯:gt
-
處理器
+關注
關注
68文章
19259瀏覽量
229652 -
ARM
+關注
關注
134文章
9084瀏覽量
367387 -
嵌入式
+關注
關注
5082文章
19104瀏覽量
304815
發布評論請先 登錄
相關推薦
無線語音遙控智能車設計與實現
求大佬分享一種基于SVM的0MAP5912非特定人嵌入式語音識別系統的實現方法
[CB5654智能語音開發板測評] 語音識別開發板的比較
智能肩頸按摩儀離線語音識別芯片方案
基于SVM的0MAP5912非特定人嵌入式語音識別系統的實現
OMAP5912雙核通信及數字音頻系統實現







 工商網監
工商網監
評論