") 自然語言處理BERT中CLS的效果如何?
自然語言處理BERT中CLS的效果如何?
要說自然語言處理在18年最?yuàn)Z目閃耀的是什么事情,那當(dāng)屬 BERT 刷新各個(gè)任務(wù)的記錄了,至今已經(jīng)過去了近兩年半的時(shí)間,但其影響力未曾衰減,無論學(xué)術(shù)界還是工業(yè)界,很多的工作與部署都圍繞其展開,對(duì)很多的下游任務(wù)都有舉足輕重的作用,真的是里程碑啊。
相信大家都有過BERT、ALBERT等預(yù)訓(xùn)練語言模型應(yīng)用在自己任務(wù)上的實(shí)踐經(jīng)歷,可能是情感分析、分類、命名實(shí)體識(shí)別、閱讀理解、相似度計(jì)算等等,使用的方法也無非是在自己任務(wù)上 fine-tune 或者作為預(yù)訓(xùn)練Embedding,使用的預(yù)訓(xùn)練模型大多是公開的,大佬們(財(cái)大氣粗、資源無數(shù))訓(xùn)練好的。(有錢真好)
在用預(yù)訓(xùn)練模型的時(shí)候,根據(jù)任務(wù)的不同,用到信息也不同,有的需要是詞表示,比如命名實(shí)體識(shí)別、詞性標(biāo)注等任務(wù),有的需要的是句子表示,比如分類、句子語意匹配等。這里我要說的句子表示這一類的任務(wù),大家經(jīng)常會(huì)用到的 [CLS] 特征信息作為句子向量表示,CLS 作為 BERT/ALBERT序列信息中特殊的一個(gè)存在,在最開始設(shè)計(jì)模型的時(shí)候便考慮將其作為后續(xù)文本分類的表示,然而直接使用 CLS 的效果真的會(huì)滿足我們的預(yù)期嘛?相信大家在實(shí)踐的過程中都有所體會(huì)~,另外 ALBERT 和 BERT 在下游任務(wù)應(yīng)用上面孰好孰壞,是否有一個(gè)定論?
我最近看到了一篇 Arxiv 的文章,題目是 《Evaluation of BERT and ALBERT Sentence Embedding Performance on Downstream NLP Tasks》,這篇文章在 BERT/ALBERT 提取信息作為句子信息表示應(yīng)用在下游任務(wù),對(duì)其效果進(jìn)行了評(píng)測,或許會(huì)解答我們實(shí)踐中的疑惑,也或者會(huì)給我們一些預(yù)訓(xùn)練模型在下游任務(wù)應(yīng)用的啟發(fā),讓我們來看下~
評(píng)測對(duì)比
有一系列的對(duì)比實(shí)驗(yàn),來看在下游任務(wù)上面的效果~
[CLS] embeddings
CLS 通過 Self-Attention 機(jī)制來獲取句子級(jí)別的信息表示,在不同的任務(wù)上 Fine-tune 之后,CLS 會(huì)捕捉特定環(huán)境下的上下文信息表示。
Pooled embeddings
將文本中的所有詞做 Avg-pooling 或者 max-pooling。
Sentence-X(SBERT/ALBERT)
BERT 在語義相似度任務(wù)上面也取得了很不錯(cuò)的效果,然后其內(nèi)部的結(jié)構(gòu)在計(jì)算過程中會(huì)導(dǎo)致非常耗時(shí),不適合做語義相似度匹配任務(wù),特別是在工業(yè)界,BERT 的耗時(shí)無法滿足上線的需要。針對(duì)這個(gè)問題,有人提出 Sentence-BERT,采用孿生網(wǎng)絡(luò)模型框架,將不同的句子輸入到參數(shù)共享的兩個(gè)BERT模型中,獲取句子信息表示,用于語義相似度計(jì)算,最終相比BERT效率大大提升,滿足工業(yè)界線上需要。SBERT 從65小時(shí)降到5秒,具體詳見參考資料2。
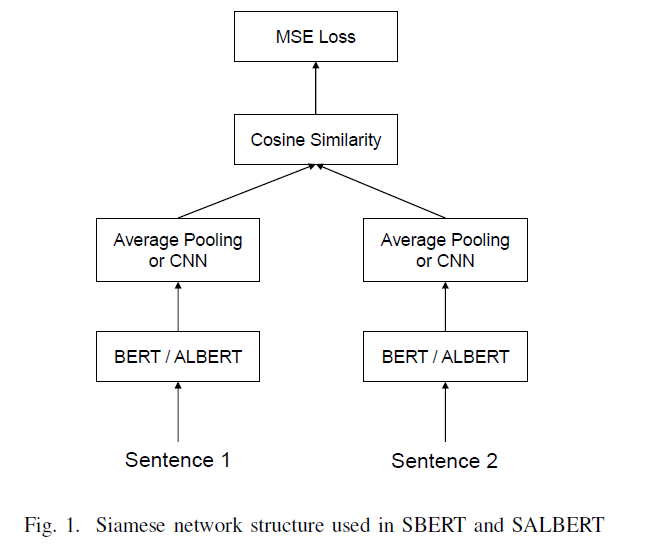
CNN-SBERT/SALBERT
在上圖中,SBERT 采用 Avg-pooling 獲取句子向量表示,本文將其替換成 CNN 網(wǎng)絡(luò)結(jié)構(gòu)獲取句子向量表示。
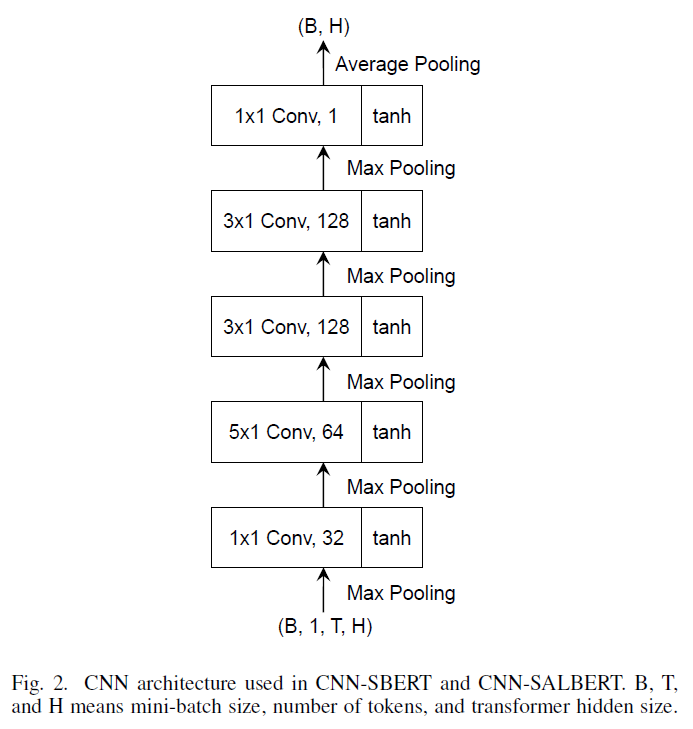
結(jié)果分析
評(píng)測任務(wù)
STS:Semantic Textual Similarity
NLI:Natural Language Inference
評(píng)測指標(biāo)
Pearson and Spearman’s rank coefficients(皮爾遜和斯皮爾曼相關(guān)系數(shù))
評(píng)測數(shù)據(jù)
Semantic Textual Similarity benchmark(STSb)
Multi-Genre Natural Language Inference(MultiNLI)
Stanford Natural Language Inference(SNLI)
上面列出來相關(guān)的評(píng)測任務(wù)、評(píng)測指標(biāo)以及評(píng)測所用到的數(shù)據(jù),下面先給出一張結(jié)果表,然后再詳細(xì)分析~
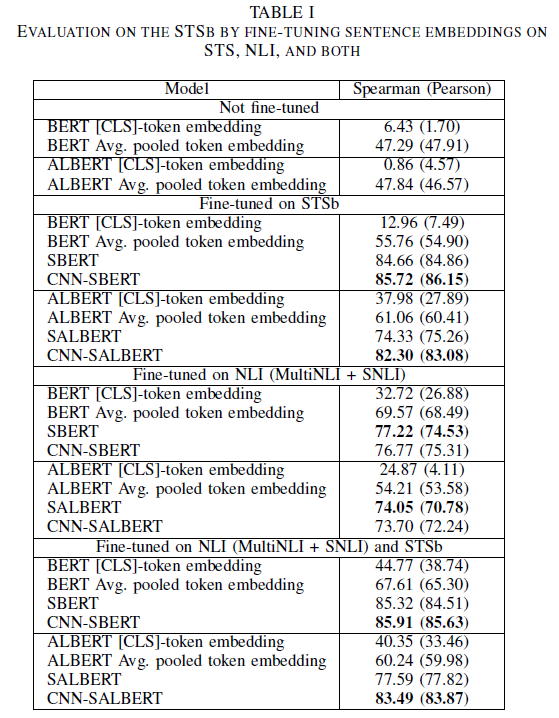
詳細(xì)分析
微調(diào)有效:這個(gè)是符合我們認(rèn)知的,肯定是微調(diào)的效果要好。
CLS 效果:CLS 的效果要遜色很多,無論是在微調(diào)上面,還是不微調(diào)上面,CLS的效果都要遠(yuǎn)遜色于平均池化操作或者其他方法。
不同方法效果:總體上來看,CNN-BERT > SBERT > Avg pooling > CLS
BERT 與 ALBERT:從上圖中大概能夠看出,不微調(diào)的情況下,兩者的效果差不多,但是微調(diào)之后,ALBERT的效果要比BERT差很多,僅僅在STSb上微調(diào)的時(shí)候,CLS 和平均池化的方法要好于BERT。
CNN的效果
從上圖來看,最好的結(jié)果是采用了 CNN 網(wǎng)絡(luò)結(jié)構(gòu),說明 CNN 起到了正向的作用,仔細(xì)觀察發(fā)現(xiàn),CNN 對(duì) ALBERT 的改進(jìn)要遠(yuǎn)大于對(duì) BERT 的改善提高。ALBERT 由于內(nèi)部參數(shù)共享,可能存在不穩(wěn)定性,CNN 網(wǎng)絡(luò)結(jié)構(gòu)或許可以減緩這種不穩(wěn)定性。
下圖也進(jìn)行了一些對(duì)比,在幾個(gè)不同的數(shù)據(jù)集上驗(yàn)證 CNN 的有效性,從最終的 Avg 結(jié)果來看,CNN 網(wǎng)絡(luò)結(jié)構(gòu)對(duì) ALBERT 有改善提升。

以上是根據(jù)實(shí)驗(yàn)結(jié)果進(jìn)行的簡單分析,其中有一些結(jié)論和對(duì)比可以在我們?nèi)粘5膶?shí)踐中借鑒并嘗試,說不定會(huì)有不錯(cuò)的效果~
原文標(biāo)題:【BERT】BERT中CLS效果真的好嘛?這篇文章告訴你答案
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
人工智能
+關(guān)注
關(guān)注
1791文章
47350瀏覽量
238750 -
自然語言
+關(guān)注
關(guān)注
1文章
288瀏覽量
13355
原文標(biāo)題:【BERT】BERT中CLS效果真的好嘛?這篇文章告訴你答案
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論