 讓長短期記憶人工神經網絡重返巔峰
讓長短期記憶人工神經網絡重返巔峰
1.開篇
去年年底,各大榜單上風起云涌,各路英雄在榜單上為了分數能多個0.01而不停的躁動,迫不及待地想要向外界秀秀自己的肌肉。
怎么回事呀,小老弟?
我們打開了中文NLP知名的評測網站CLUE,卻看到……
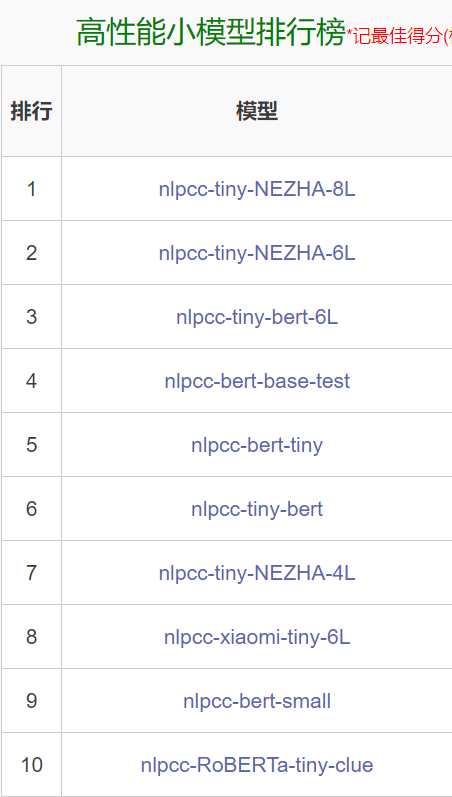
怎么全是Bert和它的兄弟?
遙想4年前,還全是RNN,LSTM和CNN的天下,怎么轉眼都不見了?LSTM不禁長嘆:年輕人,不講武德!欺負我這個25歲的老同志。
那么有沒有辦法讓LSTM重新煥發青春呢?有!知識蒸餾!
2.什么是知識蒸餾?
知識蒸餾的思想很簡單,就是讓一個教師模型來指導學生模型,讓學生模型學到教師模型的知識,而知識蒸餾的的核心也就是知識。
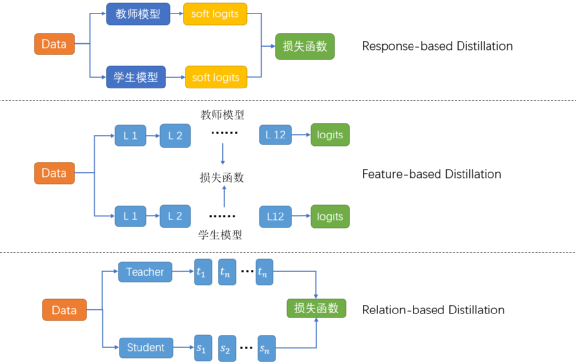
依據蒸餾所用的知識,可以把蒸餾分成三種:
Response-based Distillation:學學教師最后的輸出就夠我喝一壺了。
Feature-based distillation:中間層的知識也不能放過,畢竟神經網絡最擅長的就是學習到層級信息。
Relation-based distillation:這些表面的知識完全不夠,還要深挖層與層之間的關系,樣本與樣本之間的關系。
而這些知識之所以有效,主要是因為隱含的特征 (dark knowledge) 無法在數據層面表示出來,模型可以學習到這些特征。One-hot 無法衡量類間的區別,知識蒸餾一定程度上起到了標簽平滑的作用。比如說馬,驢和樹他們在標注上都是不同的,通過one-hot表示呈現的區別也一致,很顯然,馬和驢的相似性強于馬和樹,而我們的標注無法衡量這種相似性,但是我們的教師模型卻可以學到這樣的知識。
細看這些年的BERT蒸餾都是這些套路:
DistilBERT: 學學教師最后的輸出就夠我喝一壺了
PKDBERT: 中間層的我也都要學
TinyBERT: embedding層的知識呢?我全都要!
TinyBERT對于知識的態度
既然能用蒸餾訓練出一個性能強悍的小BERT,那可不可以用同樣的方法來蒸餾LSTM,讓他煥發第二春呢?
3.師夷長技以制夷
蒸餾的第一步是要選取一個表現優秀的教師模型,NER大榜的TOP1被RoBERTa搶先了,于是我們也選取RoBERTa作為我們的教師模型,在驗證集上得分81.55。同時,在同樣的訓練集下訓練雙向LSTM,得分68.56。兩者F1得分差距較大,直接嘗試response-baseddistillation:
| 模型 | NER F1 (Valid) |
| Roberta | 81.55 |
| LSTM (Baseline) | 68.56 |
| LSTM (蒸餾) | 71.01 |
得分有所提升,但是和榜單上那個78、79的相比還是有很大的距離。這可怎么辦?
這可怎么辦?
有什么能進一步提升模型能力的方法,想想各類BERT都在幾個T的數據上用幾十塊GPU訓練了幾百個小時,我們的LSTM只用個1萬訓練集當然不可能擊敗他們。我們也要用數據增強!
4.數據增強
CLUE NER的數據集是來源于清華大學開源的數據集THUCTC,所以我們嘗試使用THU-News數據集進行增強。隨機采樣30萬條進行測試。

這個0如此之純粹,讓人一度以為是不是跑錯了代碼,然后連續運行三次,得到的結果都是0!
我們趕緊拿到報告,找到里面的bad case(沒有一條不是bad case),發現結果很直白,所有的預測全是O(非實體)。趕緊找來增強數據集出來看看,看到了這個:
| 他?亦或是她?也許都會有。 |
| 總會有花花修的,¥%……&&() ———當下沖動的想問問她姐姐是誰暴捶一頓…… |
| 今日懸念揭曉,幾家雀躍幾家驚訝,《精靈傳說》正式與大家見面, |
| help item/ヘ兒プアイテム)等等 。 |
| credits作為zynga旗下游戲在facebook平臺上的主要支付方式。 |
| 成為勇士中的王者! |
| 令附: |
| 為了鼓勵大家多交朋友,目前android版本所有禮物都可以無限次免費贈送,現在就去吧! |
| 《馬里奧賽車wii》wii任天堂株式會社 |
| 這是由大眾對文化價值觀認同決定的。2010年有差不多接近1億左右的玩家, |
THU-News新聞數據集-游戲部分
可以看出,大部分樣本一個實體都沒有,和我們的任務完全就不是相同的分布(skewed),用這種數據集來訓練模型,訓練出來的模型將所有的標簽都認為成O(非實體)。
5.那么怎么從這些雜亂的數據集中提取出可以用作增強的數據集呢?
如果讓人工來清洗數據集的話,對于數據增強需要幾十幾百倍的數據,NER標注數據有有一點難度。人工根本行不通!
鑒于我們在使用知識蒸餾訓練模型,那能不能請教師模型來幫忙清洗數據?
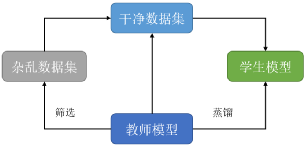
我們進行了個大膽的嘗試,不對數據集進行任何清洗,直接用教師模型對2000萬的雜亂數據集進行推理,然后只保留了教師模型認為包含實體的數據:
| 至少包含一個實體 | 至少包含兩個實體 |
| 甚至吸引了剃了平頭的六番隊隊長朽木白哉~!哈哈哈(大誤~。 | 聯合導演兼主演吳亞橋擔當形象大使的《劍網3》“收費游戲免費玩”高校威武計劃。 |
| 2008年12月“it時代周刊:2008年最具商業價值網站”; | 游戲委員會稱,對游戲的審核需要很長時間,所以像蘋果和谷歌系統旗下的游戲, |
| 嘟嘟的目標是召集100名玩家在三江源辦一場變身舞會,在這里希望大家幫她一起達成愿望。 | 咪兔數位科技旗下《穿越火線online》全新改版“末世錄”正式上線!玩家不僅能體驗到全新的“ |
| 但這一次overkill依然把自己的作品托付給了一家日本公司:soe(索尼娛樂在線)。 | 北美區全球爭霸戰亞軍隊伍tsg對上韓國全球爭霸戰冠軍隊伍shipit,分別采取圣騎、戰士、 |
| 在最初階段,微軟發言人曾表示:“微軟決不允許他人修改自己的產品。 | dice已經抓住使命召喚的這根軟肋了。 |
| infi始終不給soccer拉后紅血單位的機會, | tesl臺灣電競聯盟提供了720p以上的高畫質在線直播、與我視傳媒共同合作,在i‘ |
| 阿里納斯因槍擊隊友事件被游戲除名 | 看完上面這個名單,你可能會說gbasp和ndsi也沒有《馬里奧》游戲首發, |
| 來自世界各地的媒體紛紛希望能夠在e3任天堂展位上,搶先試玩到這款新主機,使得展位大排長龍。今日, | 有玩家說:這真是索任結合啊,游戲是任天堂的,但是按鍵是索尼風格的…… |
| 一統亂世》即將在明日正式登場。今次數據片改版將會開放多部族結盟的“聯盟系統”、爭奪地圖占領權的“ | 最后todd透露,“我們不知道會為《上古卷軸5》制作什么樣的dlc, |
| 始料不及《西游iii》你猜不到的結局 | 并且可以用這個地圖編輯器做出很多目前流行的地圖,塔防、dota等經典地圖都可以在《星際2》 |
教師模型輔助清洗后的數據
教師模型為我們選擇的這份數據集干凈的多,不包含無實體,無意義的句子。但是作為交換,原來的2000萬數據集只剩下110萬左右。
利用篩選后的數據集訓練模型,得到:
| 模型 | 數據集 | 蒸餾 | NER F1 | 參數量 |
| Roberta-Large (教師模型) | train | 無 | 81.55 | 311.24M |
| LSTM (Baseline) | train | 無 | 68.56 | 9.66M (x32.21) |
| LSTM | train | 有 | 71.01 | 9.66M (x32.21) |
| LSTM | train+10w增強 | 有 | 72.61 | 9.66M (x32.21) |
| LSTM | train+20w增強 | 有 | 74.61 | 9.66M (x32.21) |
| LSTM | train+30w增強 | 有 | 76.51 | 9.66M (x32.21) |
| LSTM | train+40w增強 | 有 | 77.30 | 9.66M (x32.21) |
| LSTM | train+50w增強 | 有 | 77.40 | 9.66M (x32.21) |
| LSTM | train+60w增強 | 有 | 78.14 | 9.66M (x32.21) |
| LSTM | train+110w增強 | 有 | 79.68 | 9.66M (x32.21) |
CLUE NER 結果
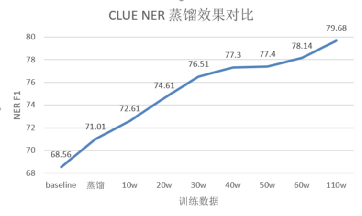
不同增強數據集增強效果
可以看出,隨著增強數據集數量的提升,學生模型效果也在逐步提升。使用110萬數據集,驗證集的分數可以達到79.68。繼續增加數據,效果應該還會有進一步提升。提交到榜單上,測試集的分數可以達到78.299,CLUENER單項排第二名,眾多的BERT中擠出了一個LSTM。
nice!
6. 總結
利用少量的訓練集訓練教師模型,隨后收集增強數據集用來訓練學生模型可以大幅提升學生模型的能力。這樣在業務的初期,只需要利用少量的標注語料,便可達到一個相對可觀的一個效果,并且在服務部署方面使用小模型可以完成對GPU的一個釋放,實際測試中使用學生LSTMGPU加速比達到3.72倍,CPU加速比達到15倍。
而模型蒸餾這樣一個teacher-student的框架,可以十分靈活的選擇教師模型和學生模型選,比如教師模型可以通過集成選擇一個最好的效果,學生模型也可以任意嘗試各式的模型結構比如CNN,LSTM,Transformers。當然其他的模型壓縮方法,比如說剪枝,近秩分解也可以與這樣的一個框架結合。而對于數據增強,在實際業務中,我們無需去尋找額外的公開數據集,直接從實際業務中就能獲取大量的數據來進行增強,這樣省去我們篩選數據的時間,也能更好的提升模型的效果。
這樣的一套框架在分類,意圖識別槽位提取,多模態等相應業務中都取得了較好的效果,甚至在增強數據集到達一定程度時超過了教師模型的效果。
原文標題:【知識蒸餾】讓LSTM重返巔峰!
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
人工智能
+關注
關注
1791文章
47350瀏覽量
238750 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13572 -
nlp
+關注
關注
1文章
489瀏覽量
22049
原文標題:【知識蒸餾】讓LSTM重返巔峰!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論