 什么是內存管理?如何進行內存管理?及內存管理的方案與分析
什么是內存管理?如何進行內存管理?及內存管理的方案與分析
前面已經將所有的硬件驅動實現,驗證了硬件功能。但是每一個硬件都是單獨測試的,而且并不完善。下一步,我們需要對各個驅動進行整合完善。在整合之前,需要做一些基礎工作。其中之一就是實現內存管理。什么叫內存管理呢?為什么要做內存管理?前面我們已經大概了解了程序中的變量現在我們復習一下:局部變量、全局變量。
局部變量在進入函數時從棧空間分配,退出函數前釋放。全局變量則在整個程序運行其中一直使用。在程序編譯時就已經分配了RAM空間。
那還有沒有第三種變量呢?可以說沒有。但是如果從生存周期上看,是有的:一個變量,在多個函數內使用,但是又不是整個程序運行期間都使用。或:一個變量,在一段時間內使用,不是整個程序運行生命周期都要用,但是用這個變量的函數會退出,然后重復進入(用static定義的局部變量相當于全局變量)
如果不使用動態內存管理,這樣的變量就只能定義為全局變量。如果將這些變量定義為指針,當要使用時,通過內存管理分配,使用完后就釋放,這就叫做動態分配。舉個實際的例子:
一個設備,有三種通信方式:串口,USB,網絡,在通信過程每個通信方式需要1K RAM。經過分析,3種通信方式不會同時使用。那么,如果不使用動態內存,則需要3K變量。如果使用內存管理動態分配,則只需要1K內存就可以了。(這個只是舉例,如果簡單的系統,確定三種方式不同時使用,可以直接復用內存)
通信方式只是舉例,其實一個系統中,并不是所有設備都一直使用,如果使用動態內存管理,RAM的峰值用量將會大大減少。
內存管理方案
不發明車輪,只優化輪胎。
內存管理是編程界的一個大話題,有很多經典的方案。很多人也在嘗試寫新的方案。內存分配模塊我們使用K&R C examples作為基礎,然后進行優化。K&R是誰?就是寫《C程序設計語言》的兩個家伙。如果你沒有這本書,真遺憾。這本書的8.7章節,《實例--存儲分配程序》,介紹了一種基本的存儲分配方法。代碼見alloc.c,整個代碼只有120行,而且結構很美。
K&R 內存管理方案分析
下面我們結合代碼分析這種內存分配方案。代碼在wujiqueUtilitiesalloc文件夾。
內存分析
初始化
在malloc函數中,如果是第一次調用就會初始化內存鏈表。代碼原來是通過獲取堆地址,在堆上建立內存池。我們把他改為更直觀的數組定義方式。內存建立后的內存視圖如下:
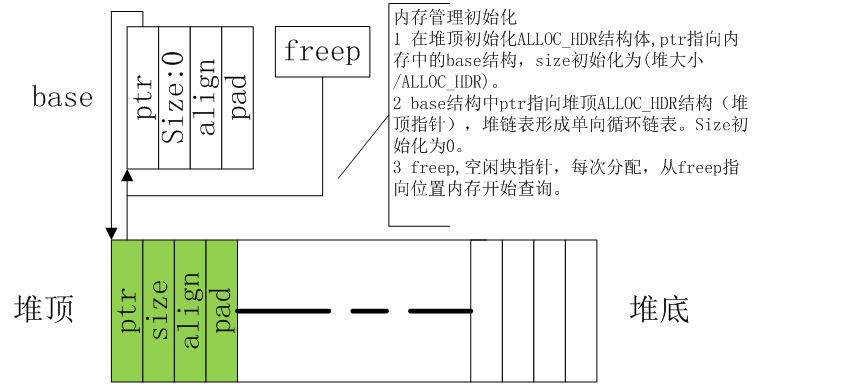
內存分配的最小單元是:
typedef struct ALLOC_HDR{ struct{ struct ALLOC_HDR *ptr; unsigned int size;/*本塊內存容量*/} s; unsigned int align; unsigned int pad;} ALLOC_HDR;
這也就是內存管理結構體。在32位ARM系統上,這個結構體是16字節。
第一次分配
每次分配,就是在一塊可以分配的空間尾部切割一塊出來,切割的大小是16字節的倍數,而且會比需要的內存多一塊頭。這塊頭在內存釋放時需要使用。這一塊,也就是內存管理的開銷。
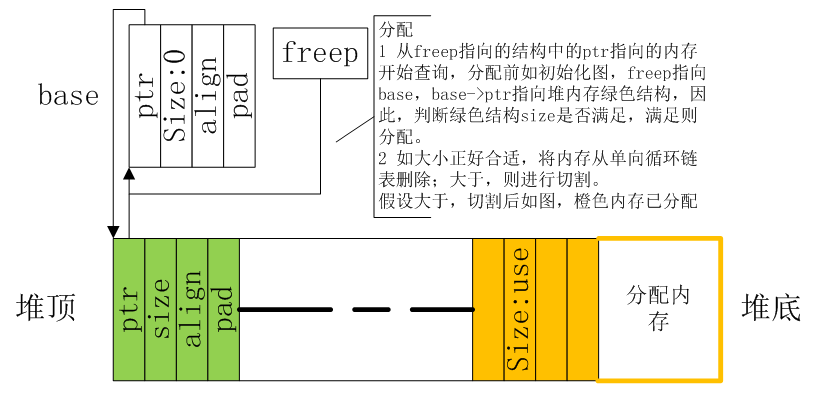
分配釋放后
經過多次分配釋放后,內存可能如下圖,綠色是兩塊不連續的空閑塊,黃色是分配出去的塊。分配出去的塊,已經不在內存鏈表里面。
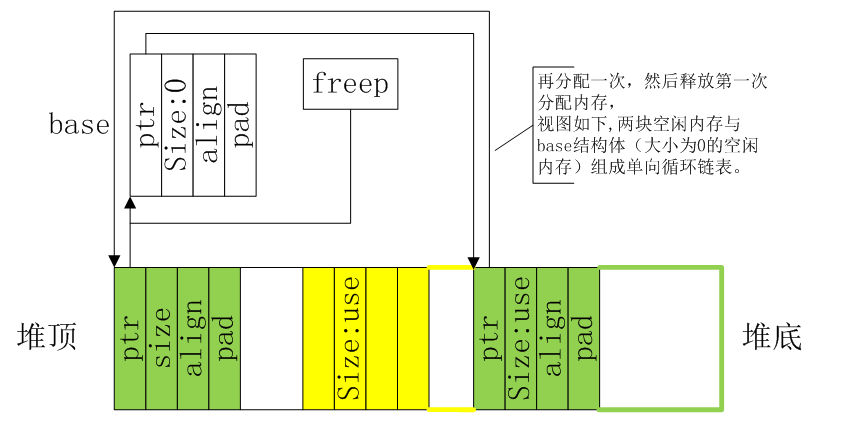
缺點
一般情況上面的代碼已經能滿足需求。但是,有以下缺陷:
缺點1:容易碎片化
分配使用首次適應法,也即是找到一塊大于等于要分配內存的空閑塊,立刻進行分配。這種方法的優點是速度較快,缺點是容易內存碎片化,分配時將很多大塊內存切割成小內存了。經過多次分配后,很可能出現以下情況:
空閑內存總量還有10K,但是卻被分散在10個塊內,而且沒有大容量的內存塊,再申請2K內存就出現失敗。如果對時間并不是那么敏感,我們可以使用最適合法,也即是遍歷空閑鏈表,查找一個最合適的內存(大于要分配內存且容量最小的空閑塊),減少大內存被切碎的概率。需要注意的是,最適合法,除了會增加分配時間,不會減少內存碎片數量,只是增加了空閑內存的集中度。假設經過多次分配后,空閑總量還是10K,也是分散在10個空閑塊,但是在這10個空閑塊中,會有5K的大塊,再申請2K的時候,就可以申請到2K內存了。
缺點2:內存消耗
內存分配方案使用了一個結構體,每次分配的最小單位就是這個結構體的大小16字節。
typedef struct ALLOC_HDR{ struct{ struct ALLOC_HDR *ptr; unsigned int size;/*本塊內存容量*/} s; unsigned int align; unsigned int pad;} ALLOC_HDR;
一次分配,最少就是2個結構體(一個結構體用于管理分配出去的內存,其余結構體做為申請內存),也就是32字節。如果代碼有大量小內存申請,例如申請100次8個字節
需求內存:100X8=800字節實際消耗內存100X32 = 3200字節利用率只有800/3200 =25%
如果內存分配只有25%的使用率,對于小內存嵌入式設備來說,是致命的方案缺陷。
如何解決呢?我們可以參考LINUX內存分配方案SLAB。在LINUX中,有很多模塊需要申請固定大小的內存(例如node結構體),為了加快分配速度,系統會使用malloc先從大內存池中申請一批node結構體大小的內存,作為一個slab內存池。當需要分配node結構體時,就直接從slab內存池申請。同理,可以將內存分配優化為:需要小內存時,從大塊內存池分配一塊大內存,例如512,使用新算法管理,用于小內存分配。當512消耗盡,再從大內存池申請第二塊512字節大內存。當小內存釋放時,判斷小塊內存池是否為空,如為空,將小塊內存池釋放回大內存池。那如何管理這個小內存池呢?
缺點3:沒有管理已分配內存
內存分配沒有將已分配內存管理起來。我們可以對已分配內存進行統一管理:
1 已分配內存在頭部有原來的結構體,通過ptr指針,將所有已分配內存連接在已分配鏈表上。2 利用不使用的align跟pad成員,記錄分配時間跟分配對象(記錄哪個驅動申請的內存)
通過上面優化后,就可以統計已經分配了多少內存,還有多少空閑內存,哪個模塊申請了最多內存等數據。
使用
1 將代碼中的所有free改為為wjq_free,malloc改為wjq_malloc。
串口緩沖用了free跟malloc.fatfs的syscall.c 用了lwip的mem.h用了。
2 修改啟動代碼, 棧跟堆改小。不用庫的malloc,堆可以完全不要。棧,還是要保留,但是不需要那么大,如果函數內用到比較大的局部變量,改為動態申請。
Stack_Size EQU 0x00002000
AREA STACK, NOINIT, READWRITE, ALIGN=3Stack_Mem SPACE Stack_Size__initial_sp
; 《h》 Heap Configuration; 《o》 Heap Size (in Bytes) 《0x0-0xFFFFFFFF:8》; 《/h》
Heap_Size EQU 0x00000010
AREA HEAP, NOINIT, READWRITE, ALIGN=3__heap_baseHeap_Mem SPACE Heap_Size__heap_limit
3 內存池開了80K,編譯不過
linking.。..Objectswujique.axf: Error: L6406E: No space in execution regions with .ANY selector matching dev_touchscreen.o(.bss)。.Objectswujique.axf: Error: L6406E: No space in execution regions with .ANY selector matching mcu_uart.o(.bss)。.Objectswujique.axf: Error: L6406E: No space in execution regions with .ANY selector matching etharp.o(.bss)。.Objectswujique.axf: Error: L6406E: No space in execution regions with .ANY selector matching mcu_can.o(.bss)。.Objectswujique.axf: Error: L6406E: No space in execution regions with .ANY selector matching netconf.o(.bss)。先把內存池改小,編譯通過之后,分析 map文件,用了較多全局變量的統統改小或者改為動態申請。分析map文件,還可以檢查還有沒有使用庫里面的malloc。Code (inc. data) RO Data RW Data ZI Data Debug Object Name 124 32 0 4 40976 1658 alloc.o 16 0 0 0 0 2474 def.o 96 34 8640 4 0 1377 dev_dacsound.o 300 36 0 0 0 2751 dev_esp8266.o 204 38 0 1 0 1446 dev_key.o 436 98 0 10 16 3648 dev_touchkey.o 310 18 0 14 3000 3444 dev_touchscreen.o 932 18 0 4 0 15981 dhcp.o 0 0 0 0 3964 5933 dual_func_demo.o 280 14 12 0 200 5963 etharp.o 0 0 0 0 0 35864 ethernetif.o 0 0 0 0 0 3820 inet.o 98 0 0 0 0 2022 inet_chksum.o 0 0 0 0 0 4163 init.o 168 4 0 20 0 4763 ip.o 0 0 4 0 0 6463 ip_addr.o 386 4 0 0 0 4118 ip_frag.o 264 38 0 8 16 383399 main.o 84 8 0 0 0 1410 mcu_adc.o 60 32 0 1 68 1511 mcu_can.o 12 0 0 0 0 521 mcu_dac.o 128 14 0 0 0 2352 mcu_i2c.o 28 8 0 1 0 630 mcu_i2s.o 336 92 0 0 0 2689 mcu_rtc.o 430 86 0 1 0 4396 mcu_timer.o 1564 82 0 0 328 9072 mcu_uart.o 504 20 0 12 0 4510 mem.o 56 10 0 0 9463 3250 memp.o 120 14 0 0 0 1651 misc.o 0 0 0 0 56 1066 netconf.o 118 0 0 0 0 4267 netif.o 684 0 0 0 0 6971 pbuf.o 36 8 392 0 8192 824 startup_stm32f40_41xxx.o
alloc.o 內存池dev_touchscreen.o 觸摸屏緩沖dual_func_demo.o USB,應該能優化memp.o 什么鬼?又一個內存池?應該是要優化掉startup_stm32f40_41xxx.o 啟動代碼,是棧跟堆用的RAM.
由于編譯器的優化,項目沒用到的代碼沒有編譯進來,上面的map數據并不完整。等后面我們做完全部測試程序,所有用到的代碼都會參與連接,到時還需要優化一次。
總結
內存管理暫時到此,等后面所有功能都完成后,再進行一次優化。如果對內存分配時間有更高要求,可使用伙伴內存分配法。
編輯:lyn
-
代碼
+關注
關注
30文章
4780瀏覽量
68529 -
內存管理
+關注
關注
0文章
168瀏覽量
14134
原文標題:深度:產品級的MCU是如何進行內存管理的?
文章出處:【微信號:gh_c472c2199c88,微信公眾號:嵌入式微處理器】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux下如何管理虛擬內存 使用虛擬內存時的常見問題
虛擬內存的作用和原理 如何調整虛擬內存設置
Linux內存泄露案例分析和內存管理分享

Linux內存管理中HVO的實現原理
Windows管理內存的三種主要方式
內存管理的硬件結構
深入理解Java 8內存管理機制及故障排查實戰指南







 工商網監
工商網監
評論