 AI優化的FPGA和GPU的芯片級對比
AI優化的FPGA和GPU的芯片級對比
本部分,我們就跟隨作者一起看看Intel Stratix10 NX和Nvidia在這個領域的利器T4以及V100之間的對比,過程分為芯片級對比以及系統級對比。
本部分一起先來看看芯片級對比
首先來看下我們的GPU對手——Nvidia T4和V100分別有320個和640個張量核(專門用于AI工作負載的矩陣乘法引擎)
Nvidia Tesla T4
Nvidia Tesla V100
下面表格總結了與Stratix10 NX和這些同代工藝GPU的關鍵指標對比。 就die尺寸來說,V100是Nvidia最大的12nm GPU,幾乎比T4大50%,而Stratix10 NX比兩種GPU都小。
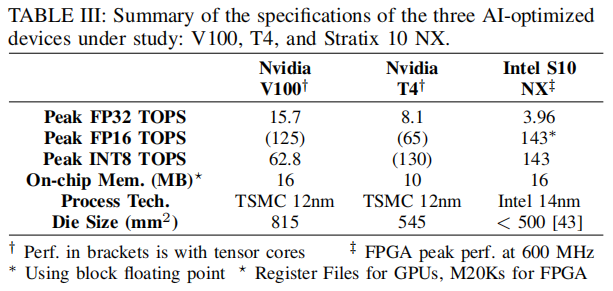
首先,文章使用GPU最擅長處理的工作負載:通用矩陣乘(GEMM)來跑GPU的benchmark(什么是GEMM請移步https://spatial-lang.org/gemm),為了測量最佳的GPU性能,對每個器件使用最新的library,這些庫不會出錯,并且分別在使用和不使用張量核的情況下測試性能。對于fp32和fp16實驗,分別使用CUDA10.0和10.2的CuBLAS庫進行V100和T4。對于int8,我們使用CUDA10.2中的cuBLASLt庫,這樣可以比cuBLAS庫獲得更高的int8性能。文章使用Nvidia的官方(高度優化)的cuDNN kernel來處理DL工作負載,并且分別對V100和T4使用了從cuDNN7.6.2和7.6.5。 (cuBLAS API,從cuda6.0開始;cuBLASLt API,從cuda10.1開始)
cuDNN庫不支持int8計算kernel,但它們支持將所有模型權重保存在片上內存中。對于每個工作負載、問題大小和序列長度,文章在兩種GPU上運行了所有可能的配置組合,如精度{fp32、fp16、int8}、計算樣式{persistent、non-persistent}、張量核心設置{enable、disable}。然后,選擇最佳的性能,來和Stratix10 NX的NPU進行比較。 這里因為是芯片級對比,所以只考慮了芯核的計算效率,不包括任何初始化、芯核啟動或主機-GPU數據傳輸開銷。
下圖給出了T4和V100 GPU上fp32、fp16和int8精度的GEMM benchmark測試結果。結果表明,相對于張量核禁用情況(藍線),啟用張量核(紅線) 可以顯著提高GPU在GEMM上的性能。
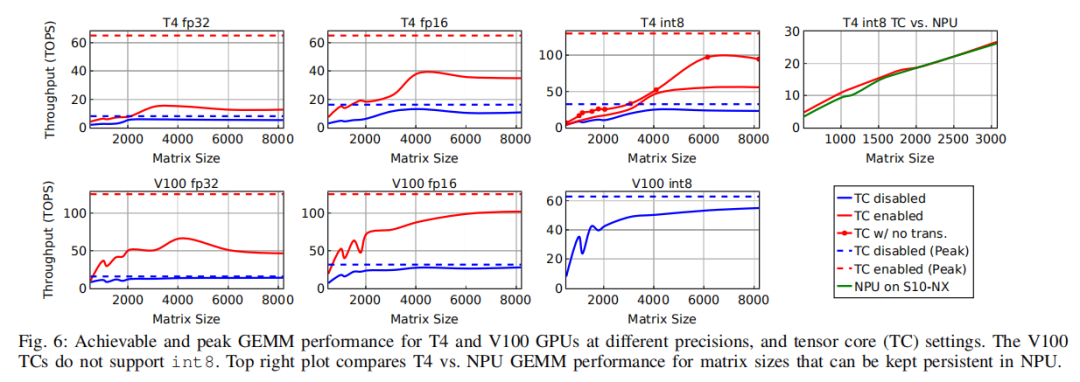
然而,一個普遍的趨勢是,張量核雖然是為GEMM設計的,但在矩陣大小為2048或以下情況時的利用效率明顯不如峰值情況(紅色虛線)。因此要實現高利用率,除非工作負載中的矩陣大小非常大,而這在實際DL工作負載中并不常見。T4和V100上的張量核都不支持fp32的精度,而是在執行乘法運算之前,將fp32數據轉換為fp16。相對于純fp16 GEMM,這種數據轉換開銷降低了張量核性能。另一個有趣的情況是,當T4張量核在int8模式下工作時,它們需要將輸入矩陣從標準的行/列主要格式轉換為特定于張量核的布局。因此,即使在處理非常大的8192×8192矩陣時,在張量核(沒有標記的紅線)上實現的int8性能還不到峰值性能的45%。
為了更好地理解這種數據轉換的開銷,文章還進行了一個額外的實驗,在這個實驗中,對張量核進行了特殊布局(帶有標記的紅線)。即使不算矩陣布局變化的開銷,對于4096×4096及以下的矩陣大小,張量核利用率也小于40%,在6144×6144矩陣中利用率達到最高為72%。
下面來看看FPGA上的情況,上圖(Fig.6)的右上角那張圖比較了Stratix10 NX上的NPU性能與具有int8張量核的T4 GPU的性能。為了公平地比較,文章禁用了NPU兩個輸入矩陣其中一個的矩陣布局變換,只保留了對另一個輸入以及輸出矩陣的布局變換(因為NPU以標準格式使用和生成這些矩陣)。
雖然NPU是為矩陣向量運算而設計的,但它在GEMM工作負載上仍然實現了與T4相似的性能,其矩陣大小從512到3072不等(最大的矩陣可以fit進片上BRAM)。
最后,一起看看頂級FPGA和GPU的PK結果。下圖(Fig.7)將文章在Stratix10 NX上增強型NPU的性能與T4和V100的最佳性能進行比較。對于比較小的batch-3和batch-6情況,FPGA性能總是顯著高于兩個GPU。FPGA在batch-6(其設計為:雙核batch-3)中表現最好,平均性能分別是T4和V100的24.2x和11.7x。
與batch-6相比,FPGA在batch-3上的性能較低,因為兩個核中的一個完全空閑。然而,它仍然比T4和V100分別平均快了22.3x和9.3x。在batch size高于6時,如果batch size不能被6整除,則NPU可能不能被充分利用。例如,在batch size為8、32和256的情況下,NPU最多可以達到其batch-6性能的67%、89%和99%,而batch size為12、36和258(上圖中的虛線所示)可以達到100%的效率。在32輸入的中等batch size情況下,NX仍然比T4具有更好的性能,并且與V100性能相當。
即使在比較大的batch size情況下,NX的性能也比T4高58%,只比die size更大(大將近一倍)的V100低30%。這些結果表明,人工智能優化的FPGA在低batch實時推理中不僅可以實現比GPU好一個數量級的性能,而且可以在放寬延遲約束下的高batch推理中和GPU匹敵。上圖(Fig.7)中的右下角圖總結了不同batch size情況下NX相對于CPU的平均加速情況。
上圖(Fig.7)中的右上角圖顯示了與不同batch大小下的兩個GPU相比,NX的平均利用率。NX在batch-6中的平均利用率為37.1%,而T4和V100分別僅為1.5%和3%。GPU張量核并非直接互連,它們只能接收來自本地核內寄存器文件的輸入。因此,每個GPU張量核都必須發送它的partial result到全局內存中,并與其他張量核同步,以結合這些partial result。然后GPU從全局內存中讀取組合好的矢量來執行進一步的操作,如激活函數(activation functions)。
較高的batch size可以攤銷這種同步延遲,但即使在batch-256情況下,T4和V100的利用率分別只有13.3%和17.8%。 另一方面,FPGA在架構上也更具優勢,其在張量塊之間有專用的用來做減法的互連, FPGA的可編程布線資源還允許將MVU tile和矢量單元級引擎級聯起來進行直接通信,減少了像GPU中那樣必須通過內存通信的情況。
綜上可以看到,FPGA依靠架構優勢和超高的資源利用率,在AI性能PK上對GPU形成了強勁挑戰。下一篇,我們再來一起看看從系統角度,FPGA和GPU的對比情況以及功耗方面的分析。
原文標題:讀《超越巔峰性能:AI優化的FPGA和GPU真實性能對比》:芯對芯
文章出處:【微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
FPGA
+關注
關注
1629文章
21729瀏覽量
603016 -
AI
+關注
關注
87文章
30743瀏覽量
268896
原文標題:讀<超越巔峰性能:AI優化的FPGA和GPU真實性能對比>:芯對芯
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

行業首個芯片級游戲技術,OPPO「風馳游戲內核」正式亮相一加游戲大會

一加將首發芯片級游戲技術 帶來極致手游體驗
NPU與GPU的性能對比
瑞沃微:一文詳解CSP(Chip Scale Package)芯片級封裝工藝
概倫電子宣布正式推出芯片級HBM靜電防護分析平臺ESDi
FPGA芯片你了解多少?
FPGA在深度學習應用中或將取代GPU
在芯片級的薄膜電阻和板級的厚膜電阻都是如何進行修調呢?

Vision Pro芯片級內部拆解分析

FPGA、ASIC、GPU誰是最合適的AI芯片?






 工商網監
工商網監
評論