") 整體thread模型的設(shè)計與實現(xiàn)
整體thread模型的設(shè)計與實現(xiàn)
SPDK Thread 模型是SPDK誕生以來十分重要的模塊,它的設(shè)計確保了spdk應(yīng)用的無鎖化編程模型,本文基于spdk最新的release 19.07版本介紹了整體thread模型的設(shè)計與實現(xiàn),并詳細分析了NVMe-oF的使用案例。
P1
SPDK Thread 模型設(shè)計與實現(xiàn)
Lcore對應(yīng)的CPU Core id
Threads在該核心下的線程
Events 這是一個spdk ring,用于事件傳遞接收
Thread – 線程,但它是spdk抽象出來的線程,主要包含了:
io_channels資源的抽象,可以是bdev,也可以是具體的tgt
tailq 線程隊列,用于連接下一個線程
name 線程的名稱
Stats 用于計時統(tǒng)計閑置和忙時時間的
active_pollers 輪詢使用的poller,非定時
timer_pollers 定時的poller
messages 這是一個spdk ring,用于消息傳遞接收
msg_cache 事件的緩存
1.1 Reactor
對象g_reactor_state有五個狀態(tài)對應(yīng)了應(yīng)用中reactors運行運行狀態(tài),
enum spdk_reactor_state {
SPDK_REACTOR_STATE_INVALID = 0,
SPDK_REACTOR_STATE_INITIALIZED = 1,
SPDK_REACTOR_STATE_RUNNING = 2,
SPDK_REACTOR_STATE_EXITING = 3,
SPDK_REACTOR_STATE_SHUTDOWN = 4,
};
初始情況下是:
SPDK_REACTOR_STATE_INVALID狀態(tài),在spdk app(任意一個target,比如nvmf_tgt)啟動時,即調(diào)用了spdk_app_start方法,會調(diào)用spdk_reactors_init,在這個方法中將會初始化所有需要被初始化的reactors(可以在配置文件中指定需要使用的Core,CPU Core 和reactor是一對一的)。并且會將g_reactor_state設(shè)置為SPDK_REACTOR_STATE_INITIALIZED。具體代碼如下:
Int spdk_reactors_init(void)
{
// 初始化所有的event mempool
g_spdk_event_mempool = spdk_mempool_create(…);
// 為g_reactors分配內(nèi)存,g_reactors是一個數(shù)組,管理了所有的reactors
posix_memalign((void **)&g_reactors, 64, (last_core + 1) * sizeof(struct spdk_reactor));
// 這里設(shè)置了reactor創(chuàng)建線程的方法,之后需要初始化線程的時候?qū){(diào)用該方法
spdk_thread_lib_init(spdk_reactor_schedule_thread, sizeof(struct spdk_lw_thread));
// 對于每一個啟動的reactor,將會初始化它們
// 初始化reactor過程,即為綁定lcore,初始化spdk ring、threads,對rusage無操作
SPDK_ENV_FOREACH_CORE(i) {
reactor = spdk_reactor_get(i);
spdk_reactor_construct(reactor, i);
}
// 設(shè)置好狀態(tài)返回
g_reactor_state = SPDK_REACTOR_STATE_INITIALIZED;
return 0;
}
在進入SPDK_REACTOR_STATE_INITIALIZED狀態(tài)且spdk_app_start在創(chuàng)建了自己的線程并綁定到了reactors后,會調(diào)用spdk_reactors_start方法并將g_reactor_state設(shè)置為SPDK_REACTOR_STATE_RUNNING狀態(tài)并會創(chuàng)建所有reactor的線程且輪詢。
Void spdk_reactors_start(void) {
SPDK_ENV_FOREACH_CORE(i) {
if (i != current_core) { // 在非master reactor中
reactor = spdk_reactor_get(i); // 得到相應(yīng)的reactor
// 設(shè)置好線程創(chuàng)建后的一個消息,該消息為輪詢函數(shù)
rc = spdk_env_thread_launch_pinned(reactor-》lcore, _spdk_reactor_run, reactor);
// reactor創(chuàng)建好線程并且會自動執(zhí)行第一個消息
spdk_thread_create(thread_name, tmp_cpumask);
}
}
// 當前CPU core得到reactor,并且開始輪詢
reactor = spdk_reactor_get(current_core);
_spdk_reactor_run(reactor);
}
之前提到spdk_reactors_init方法中調(diào)用了spdk_thread_lib_init方法傳入了創(chuàng)建thread的spdk_reactor_schedule_thread方法,在調(diào)用spdk_thread_create會回調(diào)該方法。這個方法它主要的功能就是告訴這個新創(chuàng)建的線程綁定創(chuàng)建該線程的reactor。
spdk_reactor_schedule_thread(struct spdk_thread *thread)
{
// 得到該線程設(shè)置的cpu mask
cpumask = spdk_thread_get_cpumask(thread);
for (i = 0; i 《 spdk_env_get_core_count(); i++) {
…。 // 遍歷cpu core
// 通過cpu mask找到對應(yīng)的核心,并產(chǎn)生event
if (spdk_cpuset_get_cpu(cpumask, core)) {
evt = spdk_event_allocate(core, _schedule_thread, lw_thread, NULL);
break;
}
}
// 傳遞該event,即對應(yīng)的reatcor會調(diào)用_schedule_thread方法,
spdk_event_call(evt);
}
_schedule_thread(void *arg1, void *arg2)
{
struct spdk_lw_thread *lw_thread = arg1;
struct spdk_reactor *reactor;
// 消息傳遞到對應(yīng)的reactor后將該thread加入到reactor中
reactor = spdk_reactor_get(spdk_env_get_current_core());
TAILQ_INSERT_TAIL(&reactor-》threads, lw_thread, link);
}
在SPDK_REACTOR_STATE_RUNNING后,此時所有reactor就進入了輪詢狀態(tài)。_spdk_reactor_run函數(shù)為線程提供了輪詢方法:
static int _spdk_reactor_run(void *arg) {
while (1) {
// 處理reactor上的event消息,消息會在之后講到
_spdk_event_queue_run_batch(reactor);
// 每一個reactor上注冊的thread進行遍歷并且處理poller事件
TAILQ_FOREACH_SAFE(lw_thread, &reactor-》threads, link, tmp) {
rc = spdk_thread_poll(thread, 0, now);
}
// 檢查reactor的狀態(tài)
if (g_reactor_state != SPDK_REACTOR_STATE_RUNNING) {
break;
}
}
}
而當spdk app被調(diào)用spdk_app_stop方法后將會相應(yīng)的通知每一個reactor調(diào)用spdk_reactors_stop方法,將g_reactor_state賦值為SPDK_REACTOR_STATE_EXITING,即開始退出了。回到_spdk_reactor_run函數(shù)中,輪詢將會被跳出,并且執(zhí)行銷毀線程的代碼。
static int _spdk_reactor_run(void *arg) {
…。. // 輪詢
TAILQ_FOREACH_SAFE(lw_thread, &reactor-》threads, link, tmp) {
thread = spdk_thread_get_from_ctx(lw_thread);
TAILQ_REMOVE(&reactor-》threads, lw_thread, link);
spdk_set_thread(thread);
spdk_thread_exit(thread);
spdk_thread_destroy(thread);
}
}
在這之后,主線程的_spdk_reactor_run會返回到spdk_reactors_start中,并將g_reactor_state賦值為SPDK_REACTOR_STATE_SHUTDOWN,返回到spdk_app_start中等待應(yīng)用退出。
最后,總結(jié)一下reactors和CPU core以及spdk thread關(guān)系應(yīng)該如圖1所示
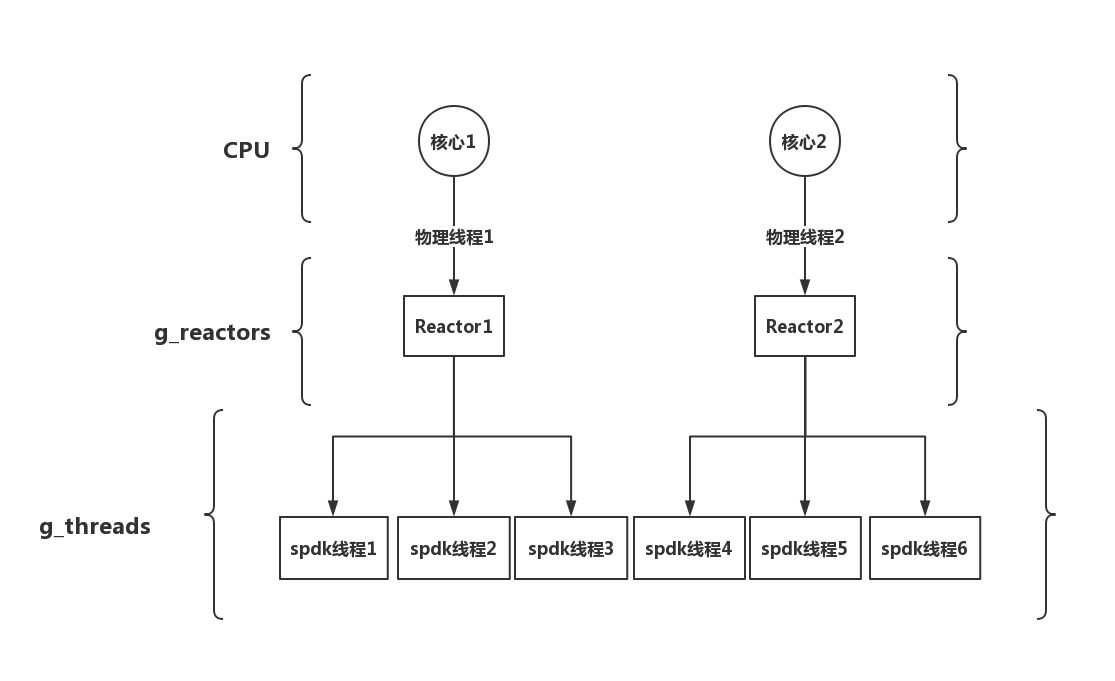
圖1 CPU cores、reactors和thread關(guān)系圖
Reactor生命周期流程圖則如圖2所示
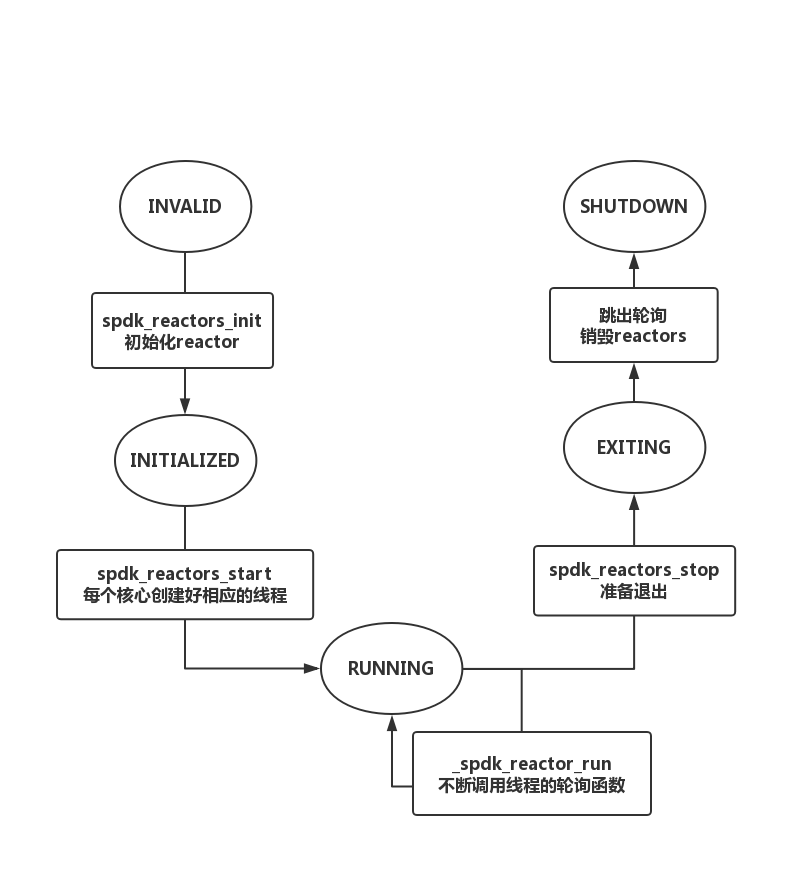
圖2 reactor生命周期流程圖
1.2 thread
當Reactors進行輪詢時,除了處理自己的事件消息之外,還會調(diào)用注冊在該reactor下面的每一個線程進行輪詢。不過通常一個reactor只有一個thread,在spdk應(yīng)用中,更多的是注冊多個poller而不是注冊多個thread。具體的輪詢方法為:
Int spdk_thread_poll(struct spdk_thread *thread, uint32_t max_msgs, uint64_t now) {
// 首先先處理ring傳遞過來的消息
msg_count = _spdk_msg_queue_run_batch(thread, max_msgs);
// 調(diào)用非定時poller中的方法
TAILQ_FOREACH_REVERSE_SAFE(poller, &thread-》active_pollers,
active_pollers_head, tailq, tmp) {
// 調(diào)用poller注冊的方法之前,會對poller狀態(tài)檢測且轉(zhuǎn)換
if (poller-》state == SPDK_POLLER_STATE_UNREGISTERED) {
TAILQ_REMOVE(&thread-》active_pollers, poller, tailq);
free(poller);
continue;
}
poller-》state = SPDK_POLLER_STATE_RUNNING;
// 調(diào)用poller注冊的方法
poller_rc = poller-》fn(poller-》arg);
// poller轉(zhuǎn)換狀態(tài)
poller-》state = SPDK_POLLER_STATE_WAITING;
}
// 調(diào)用定時poller中的方法
TAILQ_FOREACH_SAFE(poller, &thread-》timer_pollers, tailq, tmp) {
// 類似非定時poller過程,不過會檢查是否到了預(yù)定的時間
if (now 《 poller-》next_run_tick) break;
}
// 最后統(tǒng)計時間
}
Io_device 和 io_channel在thread中也是非常重要的概念。它們的實現(xiàn)都在thread.c中,io_device是設(shè)備的抽象,io_channel是對該設(shè)備通道的抽象。一個線程可以創(chuàng)建多個io_channel 。 io_channel只能和一個io_device綁定,并且這個io_channel是別的線程使用不了的。
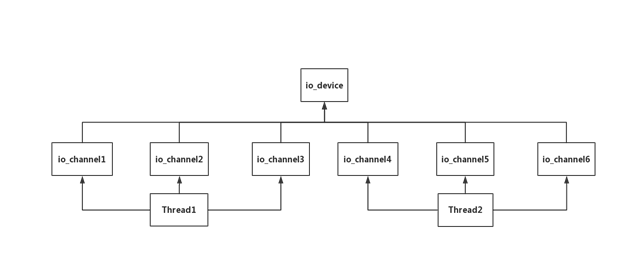
圖 3 io_device、io_channel和線程關(guān)系圖
Io_device結(jié)構(gòu)
struct io_device {
void *io_device; // 抽象的device指針
char name[SPDK_MAX_DEVICE_NAME_LEN + 1]; // 名字
spdk_io_channel_create_cb create_cb; // io_channel創(chuàng)建的回調(diào)函數(shù)
spdk_io_channel_destroy_cb destroy_cb; // io_channel銷毀的回調(diào)函數(shù)
spdk_io_device_unregister_cb unregister_cb; // io_device解綁的回調(diào)函數(shù)
struct spdk_thread *unregister_thread; // 不使用該device線程
uint32_t ctx_size; // ctx的大小,將會傳給io_channel處理
uint32_t for_each_count; // io_channel的數(shù)量
TAILQ_ENTRY(io_device) tailq; // device隊列頭
uint32_t refcnt; // 計數(shù)器
bool unregistered; // 是否該device被注冊
};
可以看到,io_device實際上只提供了一些自身io_device的操作和io_channel相關(guān)的方法,具體的io_device實體其實是那個名字叫io_device的void指針。因為thread中的io_device只提供了thread這一層接口,具體的io操作每一個設(shè)備很難被抽象出來,所以這一層的接口只負責管理io_channel的創(chuàng)建、銷毀和綁定等。
Io_channel的結(jié)構(gòu)
struct spdk_io_channel {
struct spdk_thread *thread; // 綁定的線程
struct io_device *dev; // 綁定的io_device
uint32_t ref; // io_channel引用計數(shù)
uint32_t destroy_ref; // destroy前被引用的次數(shù)
TAILQ_ENTRY(spdk_io_channel) tailq; // io_channel 隊列頭
spdk_io_channel_destroy_cb destroy_cb; // io_channel銷毀的回調(diào)函數(shù)
};
雖然io_channel看起來是很簡單的結(jié)構(gòu)體,實際上在創(chuàng)建一個io_device的時候,會要求使用者傳入一個io_channel_ctx的大小作為調(diào)用的參數(shù),而在給io_channel分配內(nèi)存的時候,除了分配本身io_channel結(jié)構(gòu)體的大小外,還會額外分配一個io_channel_ctx的大小,這個context可以理解成一個void指針,當用戶在使用io_channel的時候,實際上還是通過context的部分去訪問io_device。
P2
NVMe-oF實例
nvmf_tgt 是spdk中一個重要的模塊,這里詳細的寫一下它作為一個target實例是如何使用thread、io_device以及io_channel的。
在spdk應(yīng)用剛啟動的時候,reactor模塊就會自動加載起來,然后在加載nvmf subsystem的時候,會調(diào)用spdk_nvmf_subsystem_init(lib/event/subsystems/nvmf/nvmf_tgt.c)方法,nvmf_tgt其實也是有生命周期,并且有一個狀態(tài)機去管理它的生命周期。
enum nvmf_tgt_state {
NVMF_TGT_INIT_NONE = 0, // 最初的狀態(tài)
NVMF_TGT_INIT_PARSE_CONFIG, // 解析配置文件
NVMF_TGT_INIT_CREATE_POLL_GROUPS, // 創(chuàng)建poll groups
NVMF_TGT_INIT_START_SUBSYSTEMS, // 啟動subsystem
NVMF_TGT_INIT_START_ACCEPTOR, // 開始接收
NVMF_TGT_RUNNING, // running
NVMF_TGT_FINI_STOP_SUBSYSTEMS,
NVMF_TGT_FINI_DESTROY_POLL_GROUPS,
NVMF_TGT_FINI_STOP_ACCEPTOR,
NVMF_TGT_FINI_FREE_RESOURCES,
NVMF_TGT_STOPPED,
NVMF_TGT_ERROR,
};
首先在NVMF_TGT_INIT_PARSE_CONFIG狀態(tài)中,nvmf_tgt會去解析啟動時傳入的配置文件,當解析了[nvmf]這個label后,會調(diào)用spdk_nvmf_tgt_create這個方法,這個方法將初始化了全局的g_nvmf_tgt變量,同時也將tgt注冊成了一個io_device。
spdk_io_device_register(tgt,
spdk_nvmf_tgt_create_poll_group,
spdk_nvmf_tgt_destroy_poll_group,
sizeof(struct spdk_nvmf_poll_group),
“nvmf_tgt”);
spdk_nvmf_tgt_create_poll_group和spdk_nvmf_tgt_destroy_poll_group是io_channel創(chuàng)建和銷毀的回調(diào)方法。第三個參數(shù)是io_channel_ctx的size,既然這里傳入了spdk_nvmf_poll_group的大小,那么很明顯說明在nvmf中io_channel_ctx對象就是spdk_nvmf_poll_group。
當config文件解析完了之后,nvmf_tgt狀態(tài)到了NVMF_TGT_INIT_CREATE_POLL_GROUPS,這個狀態(tài)下會為每一個線程都創(chuàng)建相應(yīng)的poll group。
spdk_for_each_thread(nvmf_tgt_create_poll_group,
NULL,
nvmf_tgt_create_poll_group_done);
static void nvmf_tgt_create_poll_group(void *ctx)
{
struct nvmf_tgt_poll_group *pg;
…。
pg-》thread = spdk_get_thread();
pg-》group = spdk_nvmf_poll_group_create(g_spdk_nvmf_tgt);
…。
}
再看spdk_nvmf_poll_group_create中,
struct spdk_nvmf_poll_group * spdk_nvmf_poll_group_create(struct spdk_nvmf_tgt *tgt)
{
struct spdk_io_channel *ch;
ch = spdk_get_io_channel(tgt);
…。
return spdk_io_channel_get_ctx(ch);
}
在spdk_get_io_channel中,會先去檢查傳入的io_device是不是已經(jīng)注冊好了的,如果已經(jīng)注冊了,將會創(chuàng)建一個新的io_channel返回,創(chuàng)建的過程會回調(diào)在注冊io_device時注冊的io_channel創(chuàng)建方法(即方法spdk_nvmf_tgt_create_poll_group)。
static int spdk_nvmf_tgt_create_poll_group(void *io_device, void *ctx_buf)
{
…。. // 初始化transport 、nvmf subsystem等
// 注冊一個poller
group-》poller = spdk_poller_register(spdk_nvmf_poll_group_poll, group, 0);
group-》thread = spdk_get_thread();
return 0;
}
在spdk_nvmf_poll_group_poll中,因為spdk_nvmf_poll_group對象中有transport的poll group,所以它會調(diào)用對應(yīng)的transport的poll_group_poll方法,比如rdma的poll_group_poll就會輪詢rdma注冊的poller處理每個在相應(yīng)的qpair來的請求,進入rdma的狀態(tài)機將請求處理好。
然后這個狀態(tài)就結(jié)束了,之后再初始化好了nvmf subsystem相關(guān)的東西之后,到了狀態(tài)NVMF_TGT_INIT_START_ACCEPTOR。在這個狀態(tài)中,只注冊了一個poller。
g_acceptor_poller = spdk_poller_register(acceptor_poll, g_spdk_nvmf_tgt,
g_spdk_nvmf_tgt_conf-》acceptor_poll_rate);
這個poller調(diào)用的transport的方法,不斷的監(jiān)聽是不是有新的fd連接進來,如果有就調(diào)用new_qpair的回調(diào)。
P3
總結(jié)
spdk thread 模型是spdk無鎖化的基礎(chǔ),在一個線程中,當分配一個任務(wù)后,一直會運行到任務(wù)結(jié)束為止,這確保了不需要進行線程之間的切換而帶來額外的損耗。同時,高效的spdk ring提供了不同線程之間的消息傳遞,這就使得任務(wù)結(jié)束的結(jié)果可以高效的傳遞給別的處理線程。而io_device和io_channel的設(shè)計保證了資源的抽象訪問以及獨立的路徑不去爭搶資源池,并且塊設(shè)備由于是對塊進行操作的所以也十分適合抽象成io_device。正是因為以上幾點才讓spdk線程模型能夠達到無鎖化且為多個target提供了基礎(chǔ)線程框架的支持。
原文標題:SPDK線程模型解析
文章出處:【微信公眾號:FPGA之家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責任編輯:haq
-
處理器
+關(guān)注
關(guān)注
68文章
19259瀏覽量
229653 -
線程
+關(guān)注
關(guān)注
0文章
504瀏覽量
19675
原文標題:SPDK線程模型解析
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
開源共生 商業(yè)共贏 | RT-Thread 2024開發(fā)者大會報名啟動!

中興通訊推出星云通信大模型
6月6日杭州站RT-Thread線下workshop,探索RT-Thread混合部署新模式!
Thread網(wǎng)絡(luò)協(xié)議1.3.1版本特性介紹
【大語言模型:原理與工程實踐】大語言模型的評測
5月16日南京站RT-Thread線下workshop,探索RT-Thread混合部署新模式!
RT-Thread混合部署Workshop北京站來啦!
4月25日北京站RT-Thread線下workshop,探索RT-Thread混合部署新模式
理想汽車自動駕駛端到端模型實現(xiàn)

摩爾線程攜手瑞萊智慧共同打造人工智能、大模型的整體解決方案

4月10日深圳場RT-Thread線下workshop,探索RT-Thread混合部署新模式!

4月10日深圳場RT-Thread線下workshop,探索RT-Thread混合部署新模式!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論