 21個經典深度學習句間關系模型
21個經典深度學習句間關系模型
鴿了很久的NLP入門系列終于在我的努力下又更新了。
上次聊了分類任務的模型與技巧,今天我們就來聊聊句間關系任務。句間關系的輸入是一對文本,輸出是文本間的關系。常用的判別有語義相似度、語義關系推理(蘊含/中立/矛盾)、問答對等,拿GLUE榜單來說,其中有6個(QQP/MNLI/QNLI/STS/RTE/MRPC)都是句間關系任務。這個任務的應用場景也很廣泛,比如搜索推薦的語義相關性、智能問答中的問題-問題、問題-答案匹配、知識圖譜中的實體鏈接、關系識別等,是成為NLPer必須卷的一個方向。
在深度學習中,文本匹配模型可以分為兩種結構:雙塔式和交互式。
雙塔式模型也稱孿生網絡、Representation-based,就是用一個編碼器分別給兩個文本編碼出句向量,然后把兩個向量融合過一個淺層的分類器;交互是也稱Interaction-based,就是把兩個文本一起輸入進編碼器,在編碼的過程中讓它們相互交換信息,再得到最終結果。如下圖:
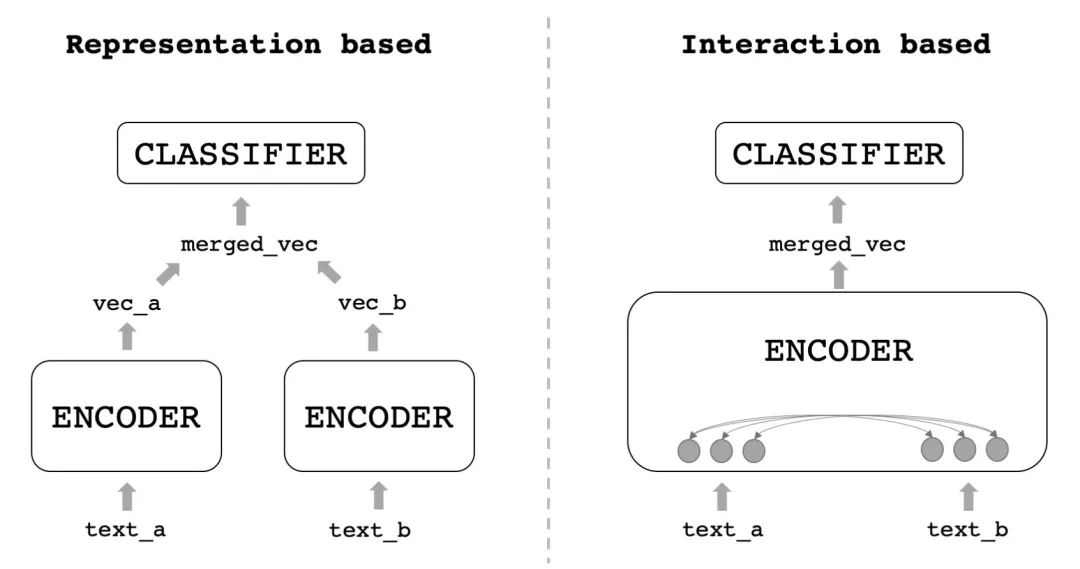
兩種框架比較的話,交互式通常準確率會高一些,畢竟編碼器能使用的信息更多了,而雙塔式的速度會快很多,比如線上來一個query,庫里有一百萬個候選,等交互式算完了用戶都走了,但雙塔式的候選可以提前計算好,只用給query編碼后去和候選向量進行淺層計算就好了。工程落地的話,通常會用雙塔式來做召回,把一百萬個候選縮減為10個,再對這10個做更精細的計算。
所以說這兩種方式都是實際應用中必不可缺的,兩個方向也都有著不少的模型:
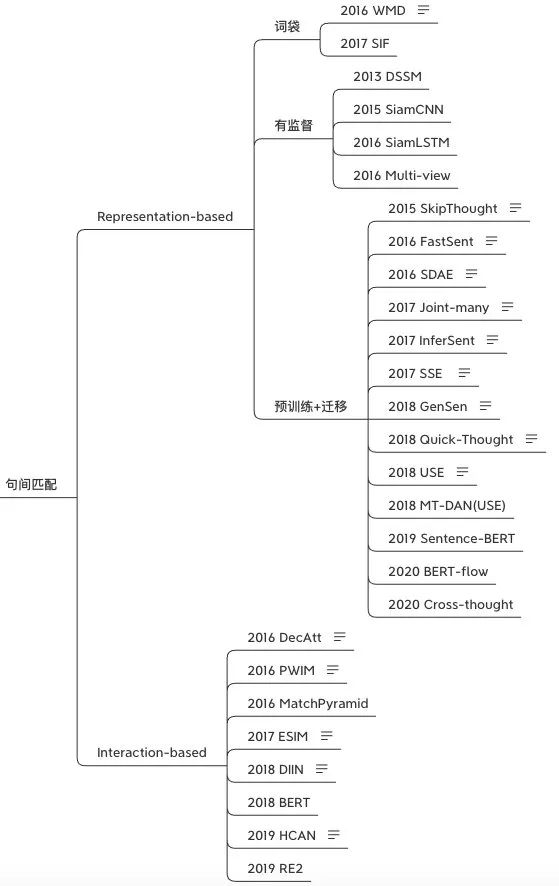
下面我們就先講講雙塔式模型的SOTA發展。這里面通常有三個點可以優化:encoder、merged_vec、classifier,大部分研究都在專注提升encoder的能力。我個人主要將雙塔的發展分為詞袋、有監督、預訓練+遷移三個階段。
詞袋句向量
最簡單的就是直接從詞向量計算句向量。首先可以用mean、max池化,相比字面n-gram重合度肯定是有提升的。但當句子中的噪聲多起來之后,如果兩個句子有大量重合的無意義詞匯,分數也會很高,這時候就可以考慮加權求和,比如TF-IDF。
ICLR2017論文SIF提出了名為smooth inverse frequency的方法,先由詞向量加權平均得到句向量,再對多個句子組成的句向量矩陣進行PCA,讓每個句向量減去第一主成分,去掉“公共”的部分,保留更多句子本身的特征。該方法在相似度任務上有10%-30%的提升,甚至超過了一些RNN模型,十分適合對速度要求高、doc相似度計算的場景。
之前提到的相似度任務都適用cosine相似度衡量的,也有學者研究了其他metric。2016年的WMD提出了Word Mover‘s Distance這一概念,用句子A走到句子B的最短距離來衡量兩者的相似程度。表示在下圖中就是非停用詞的向量轉移總距離:
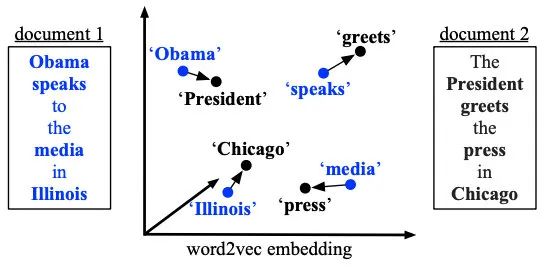
上面介紹的兩篇文章使用的都是word2vec向量,但實際操作中我推薦使用fasttext(就是加上ngram,但仍用word2vec結構訓練),一方面ngram可以增加信息,另一方面也避免了OOV。
千萬不要小看詞向量,用好了真的是很強的baseline。另外現在很多線上場景因為對速度要求高,或者是toB的業務甲方不愿意買GPU,有不少落地都停留在這個階段。
有監督句向量
詞向量雖然可以經過處理變成句向量,但詞袋式的融合也會丟失掉順序信息,同時在訓練時其目標還是word-level的,想要獲得「真正的句向量」,還是需要尋找sentence-level的目標函數。
微軟在2013年提出的CIKM論文DSSM是相當知名的多塔模型,它對文本進行word hash(也就是表示成ngram,減少詞表數),再將ngram轉成向量再平均得到句向量,經過三層MLP得到128維的編碼,用cosine相似度作為每個Q-D對的分數,經過sofamax歸一化后得到P(D|Q),最終目標為最大化正樣本被點擊的概率。
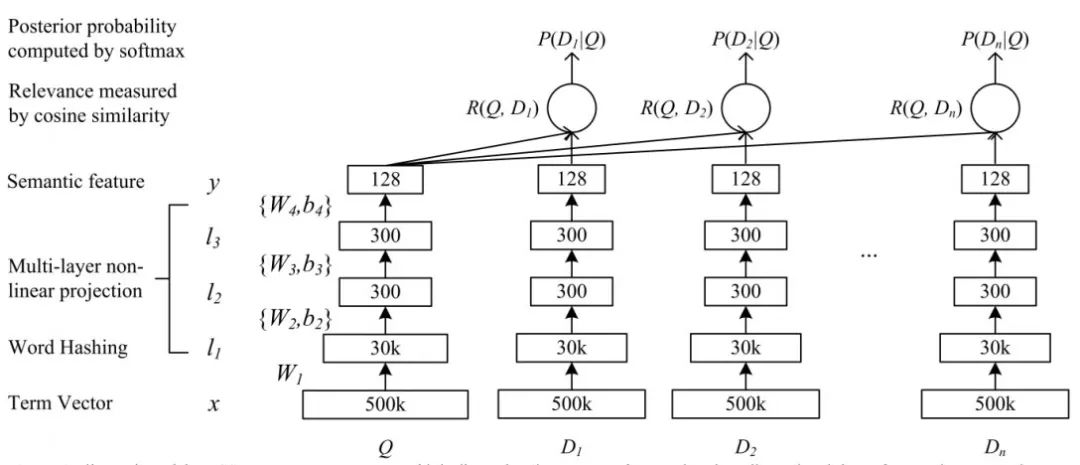
但BOW式的詞向量平均會損失上下文信息,所以之后也有學者提出了CNN-DSSM、LSTM-DSSM,基本上結構都差不多。
Siam-CNN
題目:Applying Deep Learning to Answer Selection: A Study and An Open Task
論文:https://arxiv.org/pdf/1508.01585.pdf
在2015年IBM提出的Siam-CNN架構中,作者嘗試了多種孿生架構,使用CNN作為基礎編碼器,pairwise loss作為損失函數,最后實驗發現第二種是最好的:
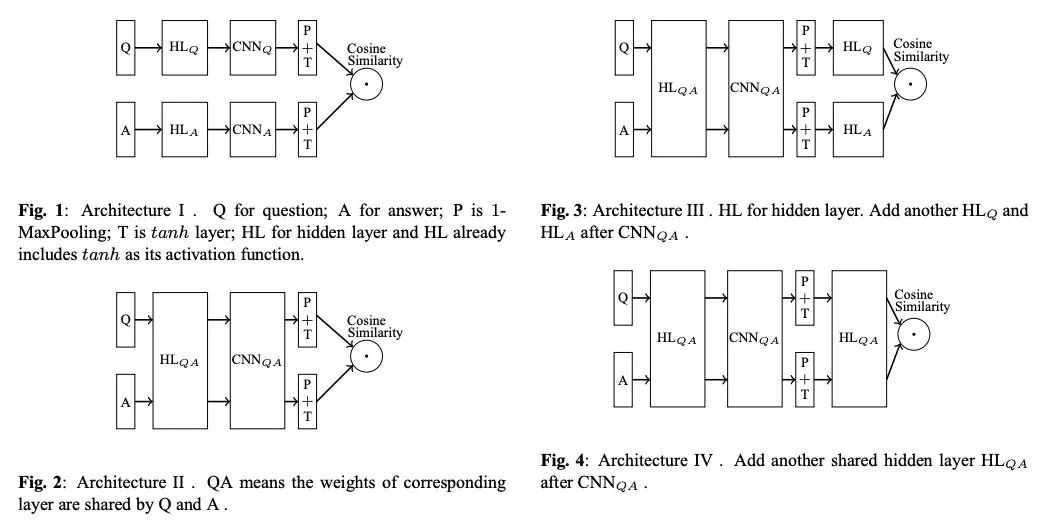
說實話這個結果有點迷,Query和Answer的表達還是略有不同的,經驗上看我覺得第三個結構更靠譜些。不過作者只在一種數據集上進行了嘗試,或許換個數據集結果會有變化。
Siam-LSTM
題目:Siamese Recurrent Architectures for Learning Sentence Similarity
論文:http://www.mit.edu/~jonasm/info/MuellerThyagarajan_AAAI16.pdf
2016年的Siam-LSTM在結構上比較簡單,就是直接用共享權重的LSTM編碼,取最后一步的輸出作為表示。有個改進點是作者使用了Manhattan距離計算損失:
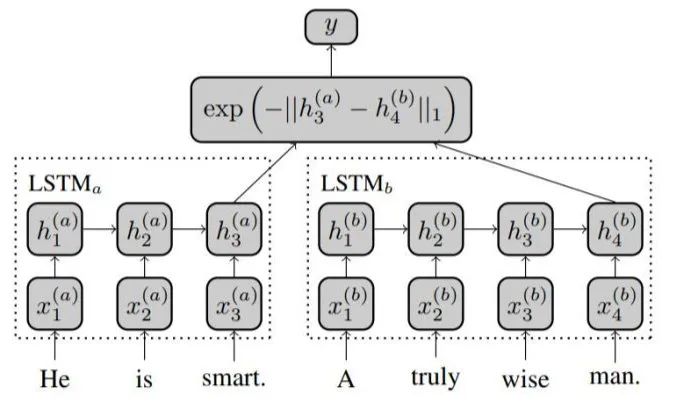
后續還有一些模型改成雙向、char-level的,這里就不過多贅述了。
Multi-View
題目:Multi-view Response Selection for Human-Computer Conversation
論文:https://www.aclweb.org/anthology/D16-1036.pdf
百度的EMNLP2016論文針對多輪對話問題,提出了Multi-view的Q-A匹配方式,輸入的query是歷史對話的拼接,分別編碼了word sequence view和utterance sequence view兩種表示。詞級別的計算和Siam-LSTM差不多,都是用RNN的最后一步輸出做Q-A匹配,而句子級別的會對RNN每步輸出做max pooling得到句子表示,然后再將句子表示輸入到GRU中,取最后一步作為帶上下文的表示與回答匹配,如下圖:
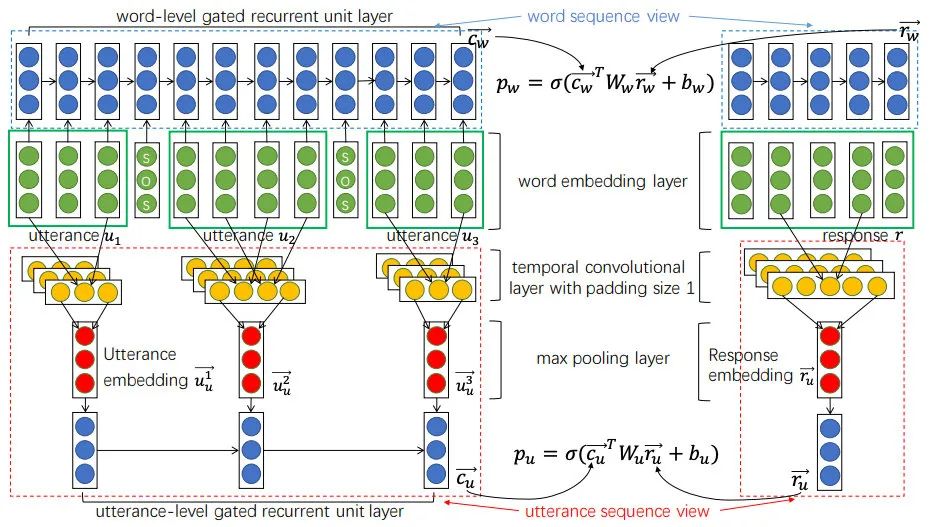
融合了兩個level的匹配后比普通方法的R@1要好上4-6個點,提升很明顯。
預訓練+遷移
有監督、領域內的語料總是有限的,目前很多任務都開始轉向預訓練+遷移的范式。
Skip-Thought
題目:Skip-Thought Vectors
論文:https://arxiv.org/pdf/1506.06726.pdf
代碼:https://github.com/ryankiros/skip-thoughts
多倫多大學的NIPS2015論文Skip-Thought提出了一種無監督句向量訓練方法,參考wrod2vec,一句話與它的上下文也是存在關聯的,因此我們可以用一個句子的編碼去預測它的上下句:

Skip-Thought用GRU作為編碼器,條件GRU作為解碼器,預測時候只用編碼器就可以得到句子表示。
但這種方法訓出的decoder不用比較浪費,后續也有學者用同樣的思想改成了判別任務,比如Quick-Thought對句子分別編碼,過分類器選擇上下文,又或者BERT中的NSP,或者ALBERT的SOP。
FastSent
題目:Learning Distributed Representations of Sentences from Unlabelled Data
論文:https://www.aclweb.org/anthology/N16-1162.pdf
代碼:https://github.com/fh295/SentenceRepresentation/tree/master/FastSent
2016年的FastSent主要對Skip-Thought的速度進行了改進,其實就是用詞袋模型去替換RNN編碼,再用中間句子的表示去預測上下文的詞。同時也提出了一個FastSent+AE變體,預測目標也加上了自身的詞。
最終效果在無監督任務上好于Skip-Thought,但有監督任務上還是略遜色。
InferSent
題目:Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
論文:https://www.aclweb.org/anthology/D17-1070.pdf
代碼:https://github.com/facebookresearch/InferSent
前幾篇可遷移的encoder都是無監督的,因為學者們一直沒有發現更通用的數據,直到InferSent。
EMNLP2017中Facebook提出了InferSent,文中使用NLI數據集來預訓練雙塔結構,超越了之前眾多無監督方法。該文章用了很簡單的雙塔結構,但在計算loss時先對兩個向量用了多種方式融合,再過分類器。同時也提出了多個基于RNN、CNN的編碼器,最后實驗發現BiLSTM+Max效果最好,在評估的10個任務中有9個達到了SOTA。
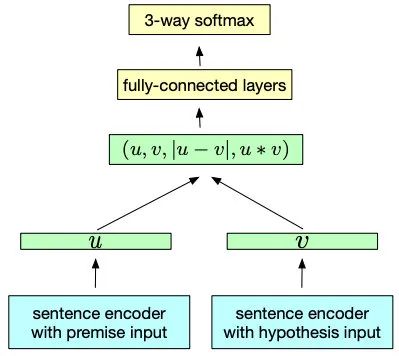
InferSent提出的結構到現在還用很多同學在用,包括后文的Sentence-BERT(19年的SOTA)也只是換了個編碼器而已。同時用NLI來做預訓練這個點也很重要,優質語料對模型提示有很大幫助。
后續也有模型進行了小改進,比如2017年的SSE,使用3層堆疊BiLSTM+Shortcut,效果比InferSent好一些。
GenSen
題目:Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning
論文:https://arxiv.org/abs/1804.00079
代碼:https://github.com/Maluuba/gensen
同樣是提升可遷移性,微軟在ICLR2018上提出了GenSen,使用GRU編碼,將encoder下游接上4種不同的任務(預測上下文、翻譯、NLI、句法分析),但只在6/10個任務上超越了之前的模型,個別情況下增加新的任務還會使效果下降。
這種多任務的思想后續也被用在其他模型上,比如MT-DNN(狗頭。
USE
題目:Universal Sentence Encoder, Learning Semantic Textual Similarity from Conversations
論文:https://arxiv.org/pdf/1803.11175v1.pdf, https://arxiv.org/pdf/1804.07754.pdf
谷歌在ACL2018提出了USE模型,這也是引用量很高的一篇文章(但寫的不是很清楚,推薦讀第二篇),主要改進如下:
提出了用Transformer和平均池化+MLP作為encoder,分別適用不同的場景
爬取了大量reddit的問答數據,用于無監督Q-A訓練,因為query和answer的表示空間不一樣,結構上給answer多加一層DNN。并且在問答任務上使用batch negative策略,也就是除了對應的正確答案外batch內剩下的樣本都作為負例,用softmax計算P(A|Q)的概率,跟現在對比學習的loss一樣。
多任務,在無監督訓練Q-A的同時也用SNLI進行有監督訓練
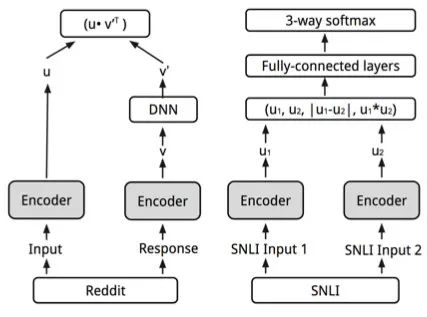
這樣訓練出的模型比InferSent高3-5個點,效果很好。現在這個模型也在一直更新,可以在TFhub上使用,不僅速度快,效果也沒比BERT系差太多。
Sentence-BERT
題目:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
論文:https://arxiv.org/pdf/1908.10084
代碼:https://github.com/UKPLab/sentence-transformers
EMNLP2019的Sentence-BERT是目前最常用的BERT式雙塔模型,一是效果真的好,二是作者的開源工具做的很方便,用的人越來越多。結果其實就是把InferSent改成BERT編碼,訓練語料也不變,做離線任務可以直接用起來。
BERT-flow
題目:On the Sentence Embeddings from Pre-trained Language Models
論文:https://arxiv.org/pdf/2011.05864.pdf
代碼:https://github.com/bohanli/BERT-flow
字節在EMNLP2020提出了BERT-flow,主要是基于Sentence-BERT做改動,因為之前的預訓練+遷移都是使用有監督數據,而作者基于對原生BERT表示的分析發現,那些表示在空間的分布很不均勻,于是使用flow-based生成模型將它們映射到高斯分布的均勻空間,比之前的Sentence-BERT提升了4個點之多。
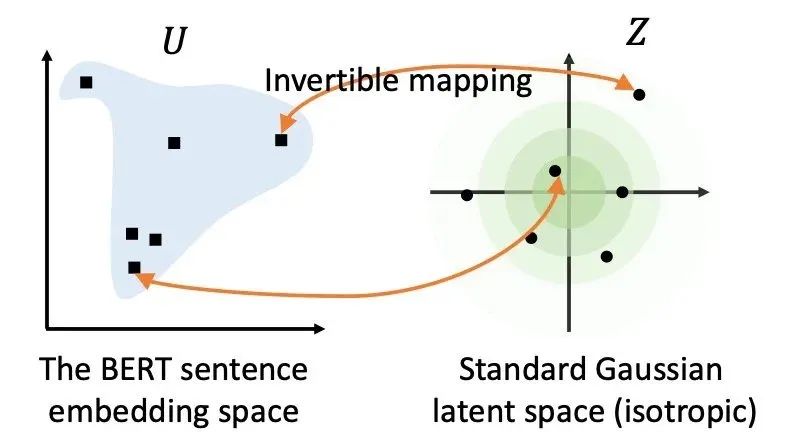
但這個模型的缺點是又加了一層機制,在預測時候會降低速度,同時在知乎上看到個別同學在自己任務上的試用反饋也不太好。不過我倒是驗證了SentEval上有監督的效果(論文只給了無監督的),效果跟Sentence-BERT差不多。
Cross-Thought
題目:Cross-Thought for Sentence Encoder Pre-training
論文:https://arxiv.org/abs/2010.03652
代碼:https://github.com/shuohangwang/Cross-Thought
微軟在EMNLP2020提出了Cross-Thought,先用transformer對每個句子編碼,再取多個CLS(紅點部分)作為句子表示再進行attention,得到一個整體的上下文表示,再回頭去預測每個句子被mask的token。相比起NSP來說,該任務的解空間更豐富,相比單純的BERT表示提升明顯,在QA任務上更是提了幾十個點。
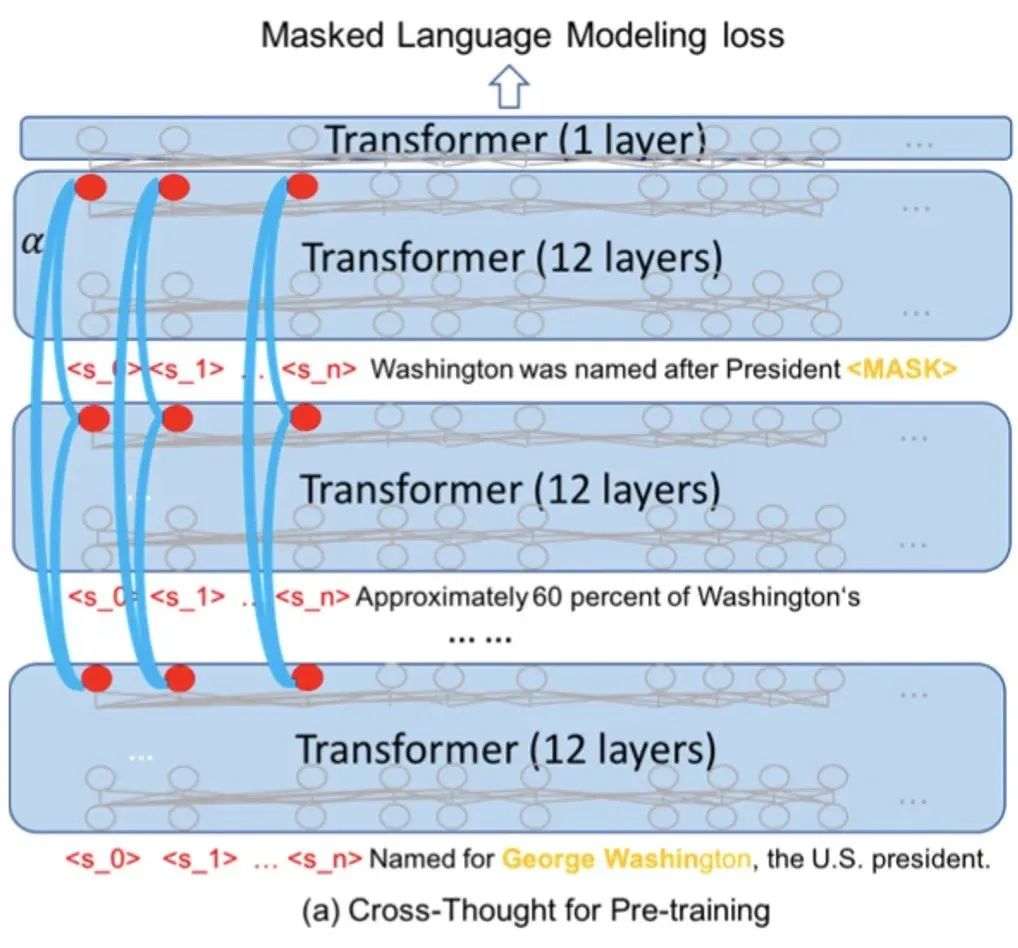
對比學習
對比學習是20年圖像領域火熱的表示預訓練方法,在訓練時會給輸入A生成一個數據增強版本B,經過編碼器對A和B編碼后,如果兩個表示還是最接近的(batch內分類),就說明這個編碼器抓住了用于區分A與其他樣本的本質特征。對比學習目前在NLP領域還沒開始大放異彩,從20年下半年的一些新論文來看,在預訓練過程、精調中加入對比損失都會輕微提升模型效果并增強魯棒性、小樣本場景的表現。相信用對比做出的優秀文本表示不久就會出現。
!!!我是朋克風分割線!!!
上文講了眾多雙塔模型,其主要的重點都在編碼器的優化,對速度要求高的召回場景可以用BOW+MLP、CNN,精度要求高的排序場景可以用LSTM、Transformer。同時兩個向量的融合方法以及loss也都可以優化,比如做一些輕微的交互、像Deformer一樣前面雙塔接后面的多層交互,或者根據需要選擇pointwise、pairwise(排序場景)損失。
但真要想做句間關系SOTA的話,比如刷榜,光靠雙塔模型還是不行的,它有兩個問題比較大:
位置信息。如果用BOW的話“我很不開心”和“我不很開心”兩句的意思就變成一樣了,雖然用RNN、BERT引入位置編碼可以減緩一些,但不去讓兩個句子相互比較的話對于最后的分類層還是很難的
細粒度語義。比如“我開心”和“我不開心”這兩句話只有一個字的區別,但BOW模型很可能給出較高的相似度,交互式模型則可以稍有緩解
交互式匹配
比起雙塔只能在encoder上下功夫,交互式模型的套路就多多了,其核心思想是將兩個句子逐個詞比較。比如判斷“進擊的巨人”和“進擊的矮子”語義是否相同時,前三個字在兩句話中都能找到,而第二句里沒找到跟“巨人”接近的,那分數就會被降低一些。因此得讓兩個句子有interaction,一般用attention解決,因為沒那么在意速度了,在交互前后都可以加encoder,再讓向量拼接、做差、點積。。。不說了,請開始讓它們表演。
DecAtt
題目:A Decomposable Attention Model for Natural Language Inference
論文:https://arxiv.org/pdf/1606.01933.pdf
Google在EMNLP2016提出了輕量級的交互模型DecAtt,作者的出發點是讓句子中的各個元素相互對比,找出詞級別的同義和反義。分為三步計算:
Attend:將兩個句子中每對次 相互attention,加權后得到對齊的
Compare:將 分別拼接,過一層FFN得到
Aggregate:分別將第二步得到的表示求和得到 ,拼接起來進行分類
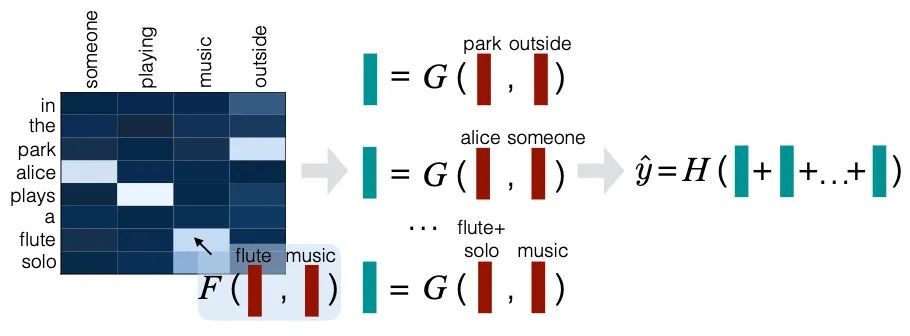
比較難懂的主要是第二步,作者的解釋是經過第一步attend后可以將問題拆解為子問題,再通過每個詞向量的compare解決。
這個模型的缺點是最后一步求句向量時用了求和操作,如果序列過長的話數值會較大,造成梯度大,需要裁剪。但計算還是很輕量的,從結果來看跟LSTM差不多。
MatchPyramid
題目:Text Matching as Image Recognition
論文:https://arxiv.org/pdf/1602.06359.pdf
代碼:https://github.com/pl8787/MatchPyramid-TensorFlow
計算所在2016AAAI發表的MatchPyramid主要受圖像處理的啟發,先對詞進行交互得到Matching矩陣,然后通過多層2D卷積抽取更高維度的特征,最后得到表征用MLP分類。作者憑借此模型在2017年的Quora Question Pairs比賽上拿到了全球第四。
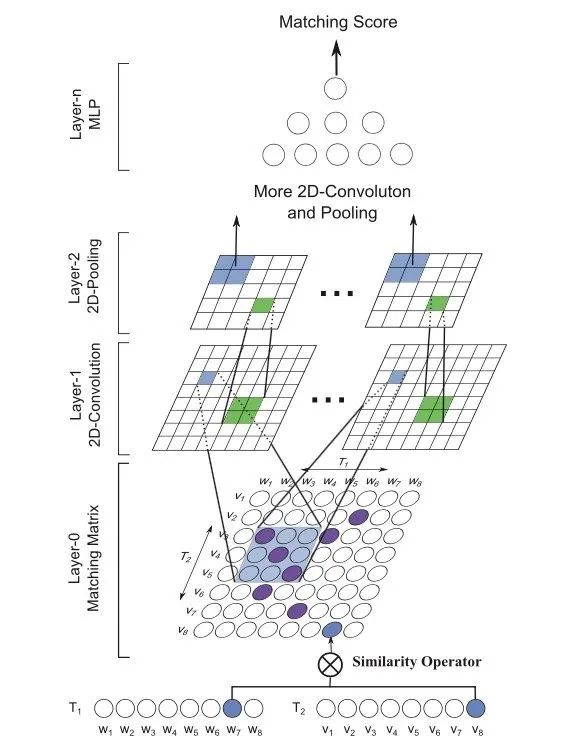
相比上文的DecAtt,MatchPyramid通過CNN捕獲到了ngram特征。從結果看比DSSM等模型高出了3、5個點。
PWIM
題目:Pairwise Word Interaction Modeling with Deep Neural Networks for Semantic Similarity Measurement
論文:https://www.aclweb.org/anthology/N16-1108.pdf
代碼:https://github.com/lanwuwei/Subword-PWIM
ACL2016的PWIM模型主打細粒度交互,模型非常的深,分為以下四個計算步驟:
Context Modeling:用BiLSTM對輸入編碼
Pairwise Word Interaction Modeling:作者定義了一個對比向量的函數coU(包含cosine、點積、歐式距離),對兩句話的詞進行兩兩比較,總共計算了前向向量、反向向量、前后向拼接、前后向相加四種表示的coU,作者將輸出稱為simCube
Similarity Focus Layer:提出了一個算法,根據simCube的分數排序,計算出一個mask矩陣,其中重要元素的權重是1,非重要為0.1。作者認為如果句子A中的某個詞在句子B中也找到了,那這就是一個衡量兩者相似度的重要指標。最終mask和simCube相乘得到focusCube
Deep ConvNet:作者把前面產出的三維矩陣看作圖像,用19層卷積神經網絡的到最后的表征,再過softmax分類
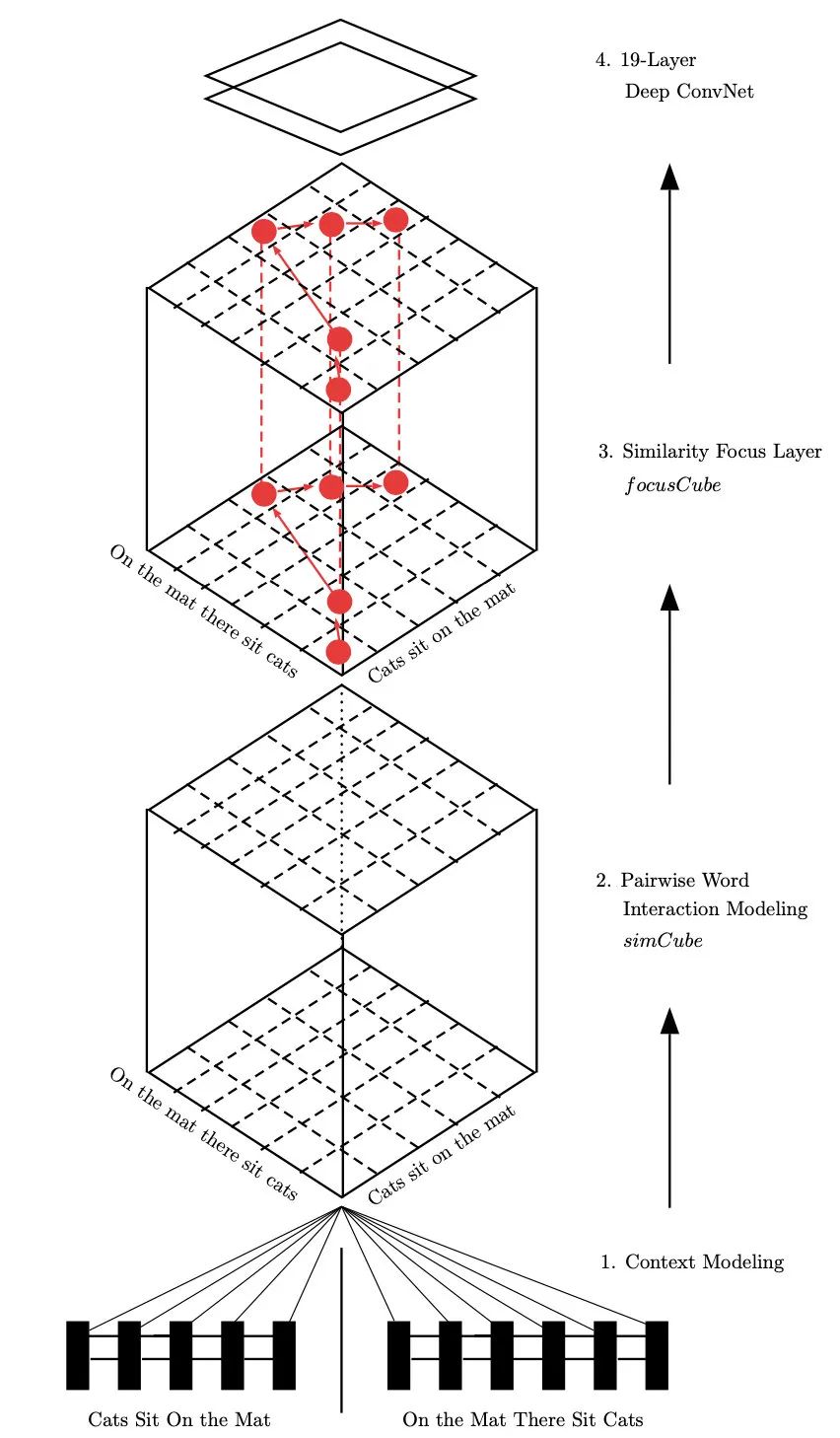
這篇文章真的是花式計算,雖然從結果來看超過了雙層BiLSTM 2、3個點,但這計算復雜度讓人難以承受。在后文也會被ESIM超越,所以就別用了,當做多學習一些思想吧~
ESIM
題目:Enhanced LSTM for Natural Language Inference
論文:https://www.aclweb.org/anthology/P17-1152.pdf
代碼:https://github.com/coetaur0/ESIM
ACL2017中的ESIM也是效果很好的模型,基于DecAtt改動,在兩句話交互融合后又加了一層BiLSTM,將效果提升了1-2個點。同時也嘗試使用句法樹進一步提升效果。它的計算過程有一下四步:
用BiLSTM對embedding編碼,得到表示
將兩句話的BiLSTM輸出進行attention,得到融合的句子表示
將 拼接作為新表示,用BiLSTM進行推理
池化后過進行最終分類
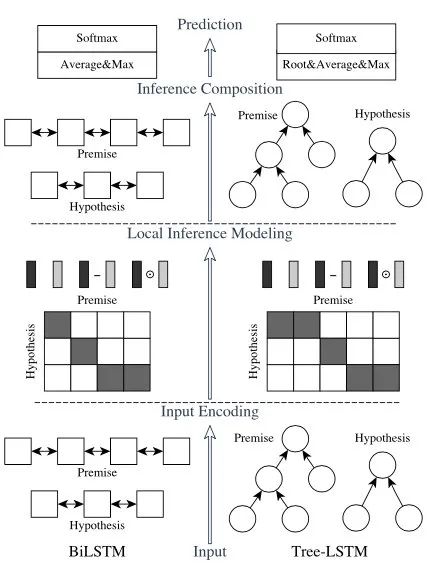
DIIN
題目:Natural Language Inference over Interaction Space
論文:https://arxiv.org/pdf/1709.04348.pdf
代碼:https://github.com/YerevaNN/DIIN-in-Keras
ICLR2018的DIIN看起來像PWIM一樣花式,比ESIM高出5、6個點。主要有以下改動:
在embedding層除了使用詞向量,還使用了字向量、詞性特征和英文詞根的完全匹配特征
使用Self-Attention編碼
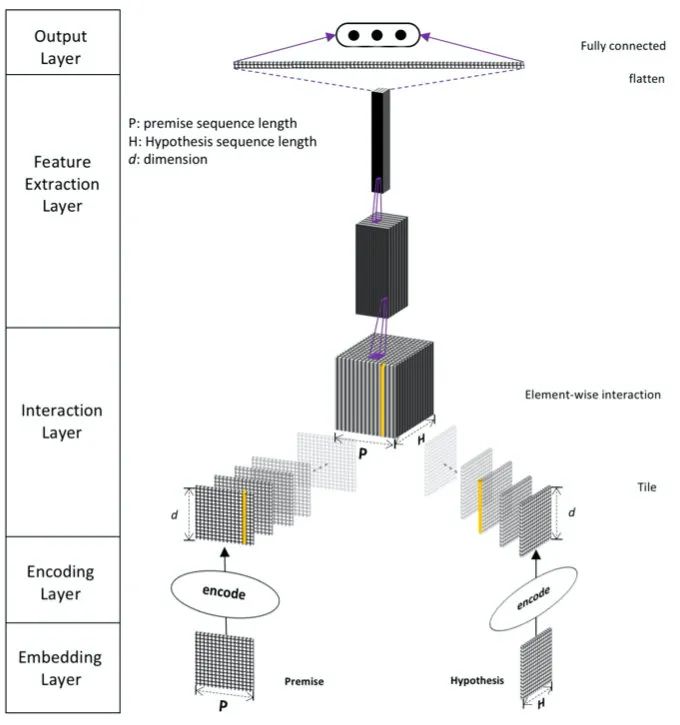
HCAN
題目:Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling
論文:https://cs.uwaterloo.ca/~jimmylin/publications/Rao_etal_EMNLP2019.pdf
代碼:https://github.com/jinfengr/hcan
HCAN是Facebook在EMNLP2019提出的模型,雖然比上文的ESIM、PWIM等模型高上4+個點,但還是被BERT甩了很遠。不過這個模型的核心也不只是做語義匹配,而是同時做檢索相關性(Relevance Matching),也就是搜索中query-doc的匹配。
模型計算如下:
Encoding層作者提出了三種方法,堆疊的CNN作為Deep Encoder,不同尺寸卷積核作為Wide Encoder,BiLSTM作為Contextual Encoder編碼更長距離的上下文
先把兩句話交互得到attention score矩陣,之后對于query中每個詞,求得doc中最相似的詞的分數,作為向量Max(S),按照同樣的方法求出Mean(S),長度都為|Q|,再分別乘上query中每個詞的tfidf統計,得到相關性匹配向量
用加性attention對query和doc進行交互,得到新的表示,再花式拼接過BiLSTM,得到語義匹配向量
將 拼接起來過MLP,最后分類
通過實驗結果來看,Deep Encoder的表現是最好的,在7/8個評估上都超過另外兩個。
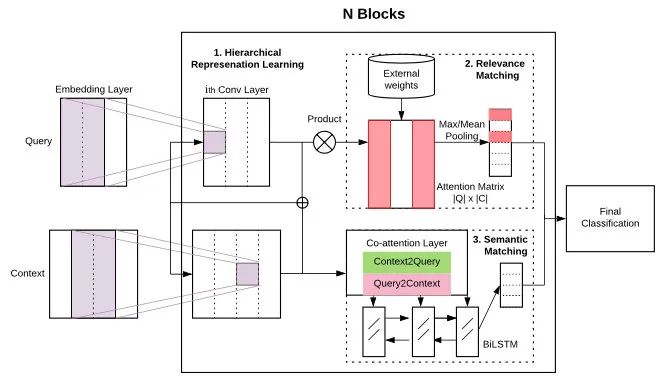
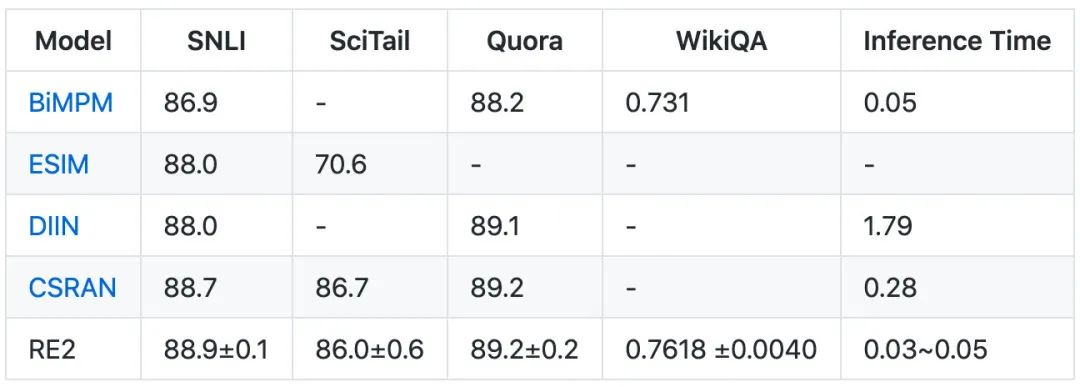
RE2
題目:Simple and Effective Text Matching with Richer Alignment Features
論文:https://www.aclweb.org/anthology/P19-1465.pdf
代碼:https://github.com/hitvoice/RE2
RE2是阿里在ACL2019提出的模型,也是很不錯的一個工作,優點是模型輕量且效果好。上文雖然很多模型都用到了交互,但只交互1、2次,而RE2則像transformer一樣把兩句話交互了多次。
計算邏輯是(圖中只展示了雙塔的一半):
Encoding:對輸入進行embedding得到,拼接上之前的輸出,用CNN編碼
Alignment:把encoder的輸入輸出拼接起來,兩句話進行attention
Fusion:將encoder的輸入輸出與attention的結果一起融合,得到的表示進入下一循環或max pooling輸出句子表示
將兩個句子表示各種拼接后進行分類
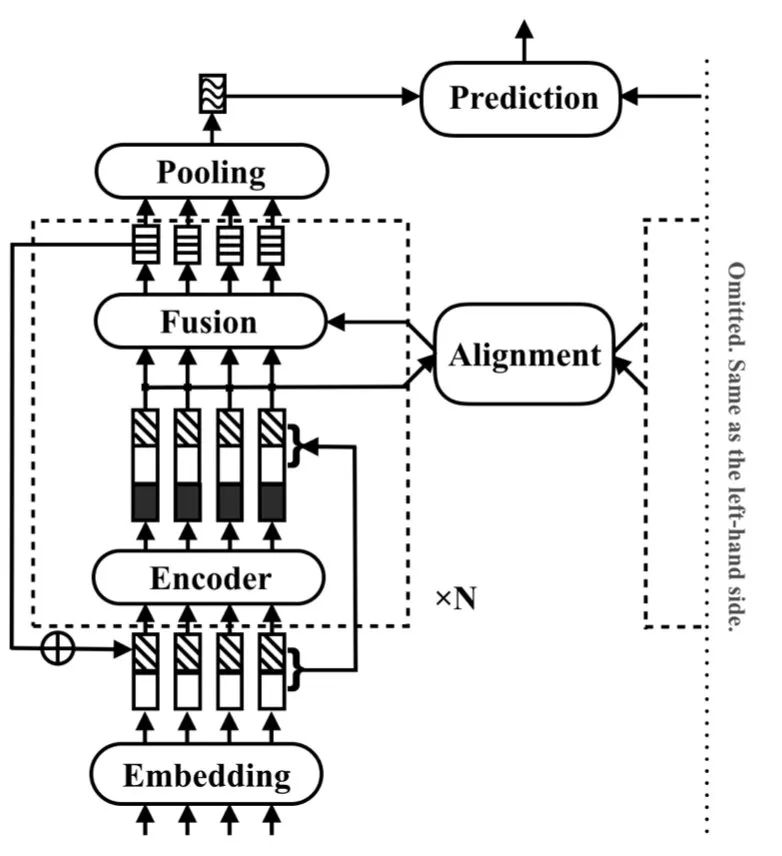
這個模型除了多次交互之外,還有個點是一直都把最初的embedding拼接上,從消融實驗看可以提升1-6個點。
!!!我是朋克風分割線!!!
一口氣講了7個交互式匹配模型,感覺自己都不會愛了。其實大部分都是為了解之前的思想,因為現在無腦用BERT就夠了。
同時老司機們也很清楚,模型只是工具,數據才是天花板,數據質量不好/數量不夠,模型再花哨也沒用。所以這里分享兩個數據洗刷刷經驗:
負例的構造。都說句間關系任務負例的構造是很重要的,確實如此。但構造前一定要把正、負界定清楚,明確這個任務的粒度有多細。比如“我很不開心”和“我不太開心”都是不開心,但程度不一樣,在自己的任務中到底是算正例還是負例呢?這個界定的越清楚、標注人員培訓越到位,數據噪聲也就越少。之后才是盡量構造有難度的負例,比如用BOW召回一些再人工標注,讓樣本們越來越逼近分類邊界
數據增強。交互式模型雖然準確,但他們有個缺點是容易過擬合,因為對“交互”看得太重了。比如一對正例里只有一兩個字一樣,模型可能就會認為這兩個字很重要,有些overlap超低的文本對也會給出高得分。這時候就要對正例進行清洗,看看特殊情況是否存在,再嘗試用增刪改的方法加一些負例,避免過擬合這種極端正例。另外BERT這種交互式模型是不對稱的,如果做paraphrase任務也可以鏡面構造些新正負例。
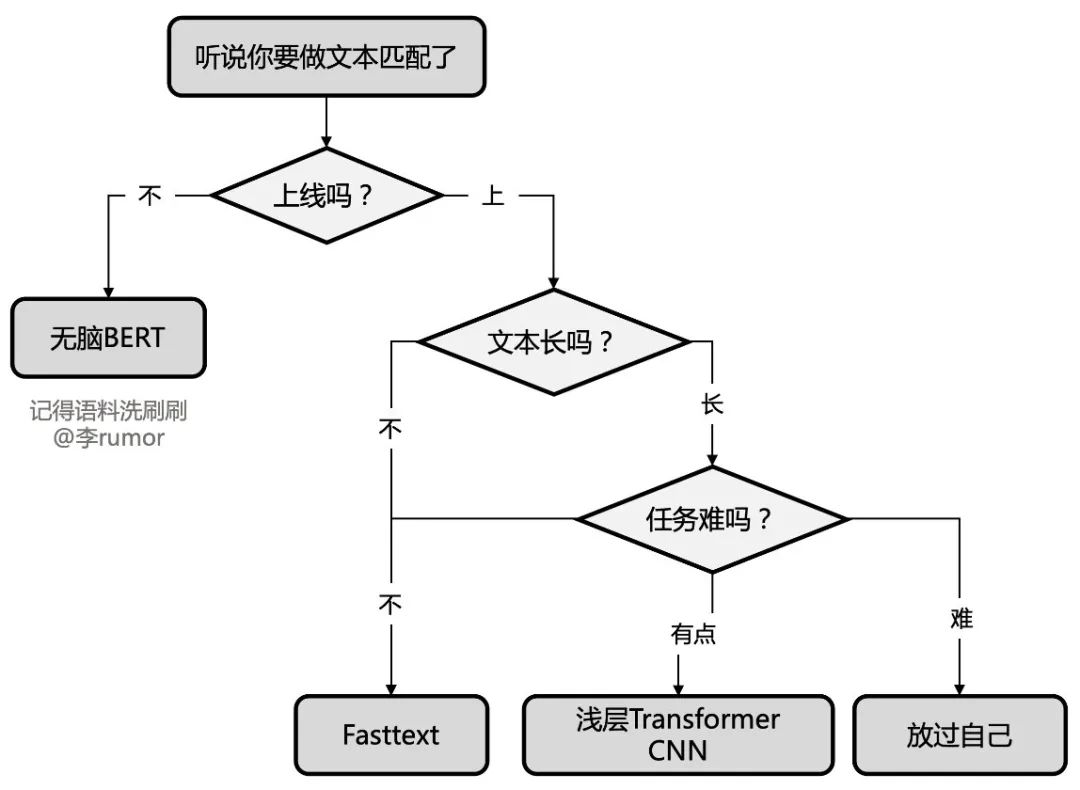
總結
可能是文本匹配方面看得比較多吧,終于把我收藏的模型都扒拉出來了,直接像文本分類一樣再給大家提供一個選型方案吧:
原文標題:【代碼&技巧】21個經典深度學習句間關系模型
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
深度學習
+關注
關注
73文章
5500瀏覽量
121113 -
nlp
+關注
關注
1文章
488瀏覽量
22033
原文標題:【代碼&技巧】21個經典深度學習句間關系模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論