 計算機視覺領域開始在3D場景理解方面取得良好進展
計算機視覺領域開始在3D場景理解方面取得良好進展
過去幾年里,3D 傳感器(如激光雷達、深度傳感攝像頭和雷達)越發普及,對于能夠處理這些設備所捕獲數據的場景理解技術,相應需求也在不斷增加。此類技術可以讓使用這些傳感器的機器學習 (ML) 系統,如無人駕駛汽車和機器人,在現實世界中導航和運作,并在移動設備上創建改進的增強現實體驗。
最近,計算機視覺領域開始在 3D 場景理解方面取得良好進展,包括用于移動 3D 目標檢測、透明目標檢測等的模型,但由于可應用于 3D 數據的可用工具和資源有限,進入該領域本身可能具有挑戰性。
為了進一步提高 3D 場景理解能力,降低感興趣的研究人員的入門門檻,我們發布了 TensorFlow 3D (TF 3D),這一高度模塊化的高效庫旨在將 3D 深度學習功能引入 TensorFlow。TF 3D 提供了一組流行的運算、損失函數、數據處理工具、模型和指標,使更廣泛的研究社區能夠開發、訓練和部署最先進的 3D 場景理解模型。
TF 3D 包含用于最先進 3D 語義分割、3D 目標檢測和 3D 實例分割的訓練和評估流水線,并支持分布式訓練。它也可實現其他潛在應用,如 3D 目標形狀預測、點云配準和點云密化。此外,它還提供了統一的數據集規范和配置,用于訓練和評估標準 3D 場景理解數據集。目前支持 Waymo Open、ScanNet 和 Rio 數據集。不過,用戶可以將 NuScenes 和 Kitti 等其他流行數據集自由轉換為相似格式,并將其用于預先存在或自定義創建的流水線,也可以通過利用 TF 3D 進行各種 3D 深度學習研究和應用,包括快速原型設計以及試驗新想法的方式來部署實時推斷系統。
左側
我們將介紹 TF 3D 提供的高效可配置的稀疏卷積主干,它是在各種 3D 場景理解任務上取得最先進結果的關鍵。此外,我們將分別介紹 TF 3D 目前支持的三種流水線:3D 語義分割、3D 目標檢測和 3D 實例分割。
3D 稀疏卷積網絡
傳感器捕獲的 3D 數據通常具有一個場景,其中包含一組感興趣的目標(如汽車、行人等),其周圍大多是有限(或無)興趣的開放空間。因此,3D 數據本質上是稀疏的。在這樣的環境下,卷積的標準實現將需要大量計算并消耗大量內存。因此,在 TF 3D 中,我們使用子流形稀疏卷積和池化運算,旨在更有效地處理 3D 稀疏數據。稀疏卷積模型是大多數戶外自動駕駛(如 Waymo、NuScenes)和室內基準(如 ScanNet)中應用的最先進方法的核心。
我們還使用多種 CUDA 技術來加快計算速度(例如,哈希處理、在共享內存中分區/緩存過濾器,以及使用位運算)。Waymo Open 數據集上的實驗表明,該實現比使用預先存在的 TensorFlow 運算的精心設計實現快約 20 倍。
TF 3D 然后使用 3D 子流形稀疏 U-Net 架構為每個體素 (Voxel) 提取特征。通過讓網絡同時提取粗略特征和精細特征并將其組合以進行預測,事實證明 U-Net 架構是有效的。U-Net 網絡包括編碼器、瓶頸和解碼器三個模塊,每個模塊都由許多稀疏卷積塊組成,并可能進行池化或解池化運算。
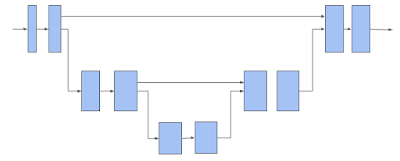
3D 稀疏體素 U-Net 架構。請注意,水平箭頭接收體素特征并對其應用子流形稀疏卷積。下移箭頭執行子流形稀疏池化。上移箭頭將回收池化的特征,與來自水平箭頭的特征合并,并對合并后的特征進行子流形稀疏卷積
上述稀疏卷積網絡是 TF 3D 中提供的 3D 場景理解流水線的主干。下面描述的每個模型都使用此主干網絡提取稀疏體素的特征,然后添加一個或多個附加預測頭來推斷感興趣的任務。用戶可以更改編碼器/解碼器層數和每層中卷積的數量以及修改卷積過濾器的大小來配置 U-Net 網絡,從而通過不同的主干配置探索大范圍的速度/準確率權衡。
3D 語義分割
3D 語義分割模型只有一個輸出頭,用于預測每個體素的語義分數,語義分數映射回點以預測每個點的語義標簽。
3D 實例分割
在 3D 實例分割中,除了預測語義外,目標是將屬于同一目標的體素歸于一組。TF 3D 中使用的 3D 實例分割算法基于我們先前的使用深度指標學習的 2D 圖像分割研究工作。該模型預測每個體素的實例嵌入向量以及每個體素的語義分數。實例嵌入向量將體素映射到一個嵌入向量空間,其中對應同一目標實例的體素靠得很近,而對應不同目標的體素則相距很遠。在這種情況下,輸入是點云而不是圖像,并使用 3D 稀疏網絡而不是 2D 圖像網絡。在推斷時,貪婪的算法每次挑選一個實例種子,并使用體素嵌入向量之間的距離將其分組為段。
3D 目標檢測
3D 目標檢測模型預測每個體素的大小、中心、旋轉矩陣以及目標語義分數。在推斷時,采用盒建議機制 (Box proposal mechanism) 將成千上萬的各體素的盒預測減少為幾個準確的盒建議,然后在訓練時,將盒預測和分類損失應用于各體素的預測。我們對預測和基本事實盒頂角之間的距離應用 Huber 損失。由于從其大小、中心和旋轉矩陣估計盒頂角的函數是可微的,因此損失將自動傳播回這些預測的目標屬性。我們采用動態盒分類損失,將與基本事實強烈重合的盒分類為正,將不重合的盒分類為負。
在我們最近的論文《DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes》中,我們詳細描述了 TF 3D 中用于目標檢測的單階段弱監督學習算法。此外,在后續工作中,我們提出基于 LSTM 的稀疏多幀模型,擴展了 3D 目標檢測模型以利用時間信息。我們進一步證明,在 Waymo Open 數據集中,這種時間模型比逐幀方法的性能高出 7.5%。
DOPS 論文中介紹的 3D 目標檢測和形狀預測模型。3D 稀疏 U-Net 用于提取每個體素的特征向量。目標檢測模塊使用這些特征建議 3D 盒和語義分數。同時,網絡的另一個分支預測形狀嵌入向量,用于輸出每個目標的網格
致謝
TensorFlow 3D 代碼庫和模型的發布是 Google 研究人員在產品組的反饋和測試下廣泛合作的結果。我們要特別強調 Alireza Fathi 和 Rui Huang(在 Google 期間完成的工作)的核心貢獻,另外還要特別感謝 Guangda Lai、Abhijit Kundu、Pei Sun、Thomas Funkhouser、David Ross、Caroline Pantofaru、Johanna Wald、Angela Dai 和 Matthias Niessner。
原文標題:TensorFlow 3D 助力理解 3D 場景!
文章出處:【微信公眾號:TensorFlow】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
傳感器
+關注
關注
2551文章
51177瀏覽量
754287 -
3D
+關注
關注
9文章
2886瀏覽量
107622
原文標題:TensorFlow 3D 助力理解 3D 場景!
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
計算機視覺與機器視覺的區別與聯系
計算機視覺的工作原理和應用
計算機視覺與智能感知是干嘛的
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺:AI如何識別與理解圖像






 工商網監
工商網監
評論