 CPU在人工智能應用中有什么獨特優勢?
CPU在人工智能應用中有什么獨特優勢?
在過去的數年間,人工智能技術實現了前所未有的爆發式成長。這主要歸功于萬物互聯的浪潮帶來的海量數據、芯片技術革新帶來的算力飛躍,以及計算機和數據科學領域對算法的不斷優化。這也是我們常說的驅動AI技術發展的三大要素:數據、算力和算法,而且這三大要素是相互促進、缺一不可的。
作為芯片來說,它是承載這三大要素最重要的力量。除了人工智能專用芯片之外,其實很多通用的芯片類型,比如GPU、FPGA,還有中央處理器CPU,都在人工智能時代針對性的進行了架構優化,并且再次煥發新生。
在這篇文章里,我們就以英特爾的至強可擴展處理器為例,一起來看一下在云計算和數據中心領域,CPU在人工智能應用里的獨特優勢。
至強可擴展處理器的技術特點
2020年6月,英特爾正式發布了第三代至強可擴展處理器(Xeon Scalable Processor),代號為Cooper Lake。
和前一代產品Cascade Lake相比,Cooper Lake單芯片集成了最高28個處理器核心,每個8路服務器平臺最高可以支持224個處理器核心。每個核心的基礎頻率可達3.1GHz,單核最高頻率可達4.3GHz。此外它還集成了一些其他的架構升級,比如增強了對傳統DDR4內存帶寬和容量的支持,并且將英特爾UPI(超級通道互聯)的通道數量增加到了6個,將CPU之間的通信帶寬和吞吐量提升了一倍,達到20.8GT/s;此外也提升了對硬件安全性、虛擬化、網絡連接等等這些數據中心常用技術的硬件支持。
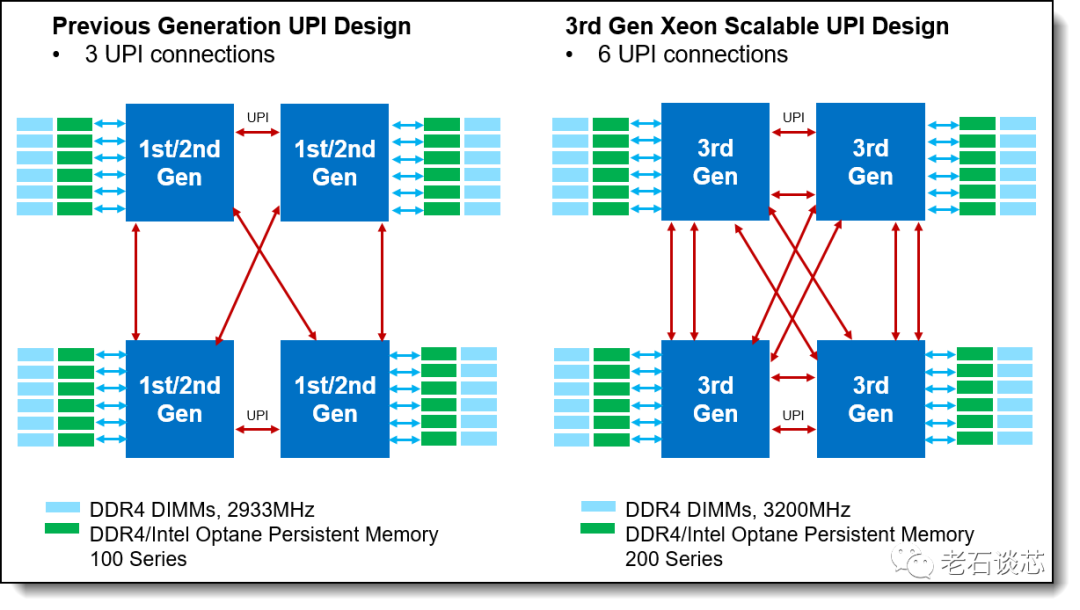
至強可擴展處理器的UPI通道示意圖
值得注意的是,這個Cooper Lake是特別針對4路或者8路的服務器產品進行打造的第三代至強可擴展處理器。對于更加常見的單路和雙路服務器,英特爾也即將推出代號為Ice Lake的處理器,它將基于英特爾最新的10納米工藝進行制造,內核采用了Sunny Cove微架構。
在去年的HotChips大會上,英特爾就對Ice Lake和Sunny Cove微架構做了比較詳細的介紹。關于這部分內容,會在今后的文章里繼續解讀,敬請關注。
Cooper Lake作為英特爾第三代至強可擴展處理器,針對人工智能應用做了特別的架構優化和設計。一個就是在上一代產品的基礎上,進一步優化了英特爾的深度學習加速技術DL-Boost,首次引入了對BF16指令集的支持。另外一個就是增加了對第二代英特爾傲騰持久內存、也就是Optane Persistent Memory的支持。接下來我們就具體來看一下為什么這兩點提升對于AI應用來說特別的重要。
英特爾深度學習加速技術
首先來看DL-Boost,也就是英特爾的深度學習加速技術。從第二代至強開始,英特爾就在這個CPU里加入了深度學習加速技術,它的核心就是擴展了AVX-512矢量神經網絡指令的用途,進一步提升了對AI應用的加速。
AVX-512是一個算力上的加速指令集,它是通過增加數據位寬來處理更多數據的,通過支持512位寬度的數據寄存器,它能在每個時鐘周期內進行32次雙精度和64次單精度浮點數運算、或者8個64位和16個32位的整數運算。這樣的能力本身就可以在CPU上為AI應用提供更好的性能支持,而DL-Boost對它的擴展,目的就是要通過降低數據精度的方式來進一步加速AI應用。
簡單來說,DL-Boost的本質有兩點,一個是低精度的數據表示不會對深度學習的推理結果和精度造成太大影響,但是會極大的提升硬件性能和效率。第二個就是可以為某些類型的AI應用、比如這里說的推理應用,專門設計更有效的指令集和硬件,來支持這些應用的高效運行。
在深度神經網絡應用里使用低精度的數據表示,已經是一個研究比較成熟的領域了。相比使用32位浮點數進行運算,我們可以采用更低的數據精度,甚至也可以采用整形數來進行運算。
有很多研究表明,當使用16位乘法器與32位累加器進行訓練和推理時,對準確性幾乎沒有影響。當使用8位乘法器與32位累加器進行推理計算時,對準確性的影響也非常小。比如對于很多應用來說、特別是涉及我們人類感官的應用,比如看一個圖片或者聽一段聲音等等,由于我們人類的感知能力并沒有那么精確,所以推理精確度的稍許差別并沒有太大關系。
但是降低數據精度會對AI芯片的設計和性能帶來很多的好處,比如可以在芯片面積不變的情況下,大幅提升運算單元的數量,或者在性能要求不變的情況下,采用更少的芯片面積,從而降低功耗。此外這樣也會減少數據傳輸的數據量,節約了帶寬,提升了吞吐量。
基于這個理論,也衍生出了很多非常有趣的AI芯片架構設計,比如一sa些AI專用芯片,還有之前介紹過的英特爾Stratix10 NX FPGA等等,都加入了對不同的數據精度的硬件支持,對于至強可擴展處理器來說也是如此。在第二代至強可擴展處理器里,深度學習加速技術第一次出現,主打INT8的加速,主攻的是推理加速。從第三代至強可擴展處理器開始,英特爾又在DL-Boost技術里引入了對BF16的硬件支持,兼顧推理和訓練的加速。
和8位整形數相比,BF16的精度更高,而且有著大得多的動態范圍。和32位浮點數相比,BF16雖然精度有所損失,但損失并不多,動態范圍類似,但所需數據位寬要小很多。可以說BF16這種數據表示,可以在精度、面積、性能等衡量標準里取得非常好的折中,這也是為什么要在第三代至強可擴展處理器里支持這種數據表示的主要原因。
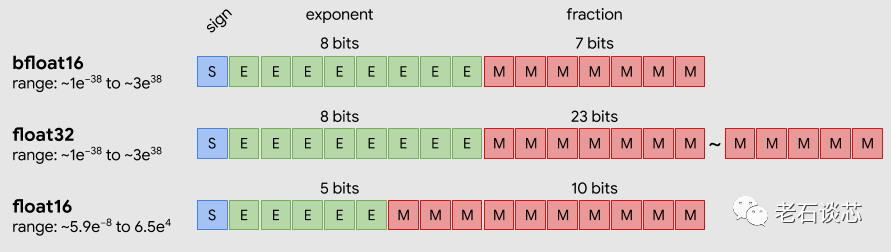
BF16和浮點數數據格式的對比
和前一代CPU搭配32位浮點數的組合相比,第三代至強可擴展處理器加上BF16加速后的AI推理性能可提升到它的1.9倍,訓練性能可提升到它的1.93倍。
當然了,業界已經有很多公司在使用和部署第三代至強可擴展處理器,以及前面介紹的深度學習加速技術。比如阿里云就利用對BF16的支持,將BERT模型推理的性能提升到原來的1.8倍以上,并且沒有準確率下降。Facebook也將英特爾深度學習加速技術用在了它的深度學習推薦模型里,結果對INT8的加速帶來了推理性能提升達2.8倍的成績,BF16加速則讓訓練性能提升達到了原來的1.6倍以上。
高性能存儲技術:傲騰Optane內存
說完數據的計算,我們接下來再來看看數據的存儲。設計芯片的一個大的原則,就是存儲數據的地方離使用數據的地方越近,性能就越高、功耗也越低。對于人工智能應用來說,不管是對于訓練還是推理,都需要對大量的數據進行處理。這一方面需要有大容量的存儲技術作支持,另一方面也需要更大的內存帶寬、以及更快的數據傳輸速度。
總體來說,我們在計算機系統里常見的存儲器類型可以分成這么幾個類型。一個是DRAM,也就是我們常說的內存,它的性能最高、數據讀寫的延時最低,但是容量十分有限、價格昂貴,更重要的是一旦斷電,DRAM里的數據就會丟失。
相比之下,像機械硬盤、固態硬盤之類的存儲方式,雖然容量夠大、價格便宜,而且具備數據持久性,但是最大的問題就是訪問速度相比DRAM來說要慢幾個量級。
所以,很自然的我們就會想,能否有另外一個量大實惠的存儲方式,既能有大容量、低延時、也能保證數據的持久性、而且價格也可以接受呢?一個可行的方案,就是英特爾的傲騰Optane持久內存。它既有大的容量、又能保證數據的持久性,也能提供快速的數據讀寫性能。傲騰持久內存目前單條容量最高可以到512GB,并且和傳統DDR4內存的插槽兼容。當搭配第三代至強可擴展處理器使用的時候,單路內存總容量最高可以達到4.5TB,遠大于普通的DRAM內存。
數據中心存儲架構層級
值得注意的是,傲騰有多種工作模式。比如它可以作為內存模式使用,這時它就和DRAM沒有本質區別,相當于對系統內存進行了擴展。它還有一個叫做App Direct的模式,可以實現較大內存容量和數據持久性,這樣軟件可以將DRAM和傲騰作為內存的兩層進行訪問。
此外,硬盤之類的存儲設備是按塊讀寫數據,而傲騰持久內存是可以按字節進行尋址的,這就保證了數據讀寫的效率和性能。
軟件框架和生態系統
說完了對數據進行計算和存儲的硬件,最后我們再來看看軟件,以及圍繞軟硬件搭建的生態系統。不管是什么芯片、什么應用場景,最終使用它的都是開發者,是人。所以開發軟件和生態是芯片設計中非常重要的環節。
英特爾有一個名叫Analytic Zoo的開源平臺,它將大數據分析、人工智能應用,包括數據的處理、模型的訓練和推理等過程進行了的整合。它可以把 TensorFlow、Pytorch、OpenVINO這些框架、開發工具和軟件集成到一個統一的,基于SPARK、Ray、Flink等搭建的大數據分析流水線里,用于分布式的訓練或預測,這樣讓用戶更方便的構建端到端的深度學習應用。這個分析流水線根據至強處理器進行了深度優化,可以充分利用前面介紹的那些針對AI應用進行的計算和存儲架構革新,并且也可以比較方便地進行計算集群的部署和擴展。
Analytics Zoo架構圖
比如,美的就采用了Analytic Zoo來搭建了工業視覺檢測的云平臺,來加速產品缺陷檢測的效率,并且將模型推理的端到端速度提升了16倍。
作為構建廣泛生態系統的一部分,英特爾硬件產品方面除了有至強可擴展處理器和傲騰持久內存,還有基于Xe架構的數據中心專用GPU系列、還有現場可編程芯片FPGA、以及一系列的人工智能專用芯片,比如旗下Habana Labs用于訓練和推理的Gaudi和Goya系列產品等等。
之前介紹摩爾定律的時候我們說過,晶體管尺寸每縮小10倍,就會衍生出一種全新的計算模式。現任英特爾芯片總架構師的Raja Koduri就把現在的計算模式分成了標量計算、向量計算、矩陣計算和空間計算四大類,分別對應基于CPU、GPU、AI ASIC和FPGA。而目前業界也只有英特爾完成了對這四大類計算模式的芯片全覆蓋。
除此之外,英特爾還推出了oneAPI,用來支持和統一這四大類硬件架構的編程,降低使用不同代碼庫和編程語言帶來的風險,并且無需在性能上做出妥協。
結語
隨著數據量的不斷爆發,數據中心的重要性在不斷凸顯。為了捍衛數據中心市場的領先地位,英特爾也勢必會拿出看家本領。關于10納米數據中心處理器Ice Lake四月份的發布,小編也會持續關注。
原文標題:什么是CPU在人工智能時代的獨特優勢
文章出處:【微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
cpu
+關注
關注
68文章
10855瀏覽量
211592 -
人工智能
+關注
關注
1791文章
47193瀏覽量
238268
原文標題:什么是CPU在人工智能時代的獨特優勢
文章出處:【微信號:bdtdsj,微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式和人工智能究竟是什么關系?
FPGA應用于人工智能的趨勢
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
risc-v在人工智能圖像處理應用前景分析
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
bnc彎公頭有哪些獨特優勢






 工商網監
工商網監
評論