

【摘要】3D視覺定位指的是根據事先構建的3D模型及相關信息,計算取得某張圖像在拍攝時相機的位置和姿態。這是3D視覺的一項十分重要的技術,可以用來幫助實現人員定位與導航。本博文將基于2019年CVPR論文From Coarse to Fine: Robust Hierarchical Localization at Large Scale所采用的分級定位方案對該技術進行簡要的介紹。基本原理3D.。.
引言
所謂3D視覺定位指的是根據事先構建的3D模型及相關信息,計算取得某張圖像在拍攝時相機的位置和姿態。這是3D視覺的一項十分重要的技術,可以用來幫助實現人員定位與導航。本博文將基于2019年CVPR論文From Coarse to Fine: Robust Hierarchical Localization at Large Scale所采用的分級定位方案對該技術進行簡要的介紹。
基本原理
3D視覺定位的直接目標是計算當前圖像的照相機位姿,解決該問題的直接方案是建立3D點與2D點之間的匹配關系,通過二者的匹配關系估計相機位姿,這一問題被稱作PnP(Pespective-n-Point)問題。求解PnP問題的方法有很多,常見的有P3P、EPnP、UPnP等,具體的如何實現本文不做介紹,讀者可以自行搜索PnP問題的相關理論。而視覺定位需要解決的一大關鍵問題是如何建立3D點與2D點之間的匹配關系。對于這一點,論文作者Sarlin提出過一種分級定位的方案,以下將詳細介紹該方案。
分級定位
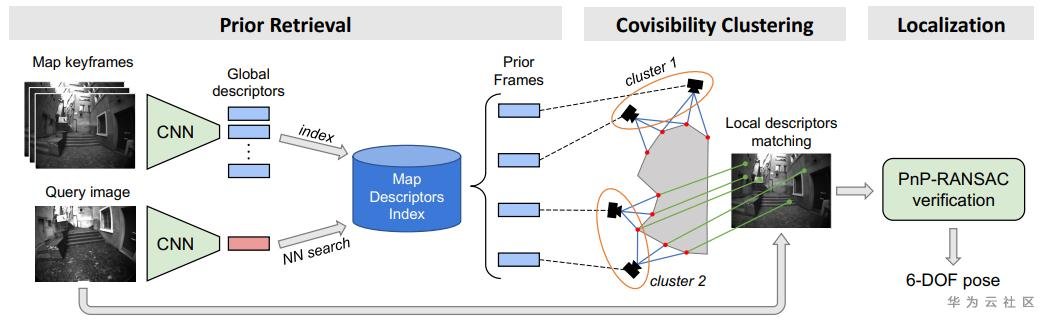
分級定位的框架大約可以分成三步:預檢索、共視聚類、局部匹配與定位。
預檢索
預檢索的意義在于獲取前k張與當前圖像最相似的圖像,判斷相似的依據通常是通過匹配圖像的全局特征。一般而言,產生全局特征的方法可以依賴于局部特征所組成的詞袋,不過近些年,一些深度學習方案也被引入了進來,例如NetVLAD或更加輕量級的MobileNetVLAD。最終通過獲取當前圖像的全局特征的k個最近鄰來獲取預檢索得到的相近圖集。
共視聚類
然而由于可能產生的錯誤匹配,所獲取到的預檢索圖集并不一定全部都面向同一場景,這時就需要先將面向不同場景的圖像區分開來,這項技術就被稱作共視聚類,簡而言之就是將具有共視關系的圖像聚成一類。
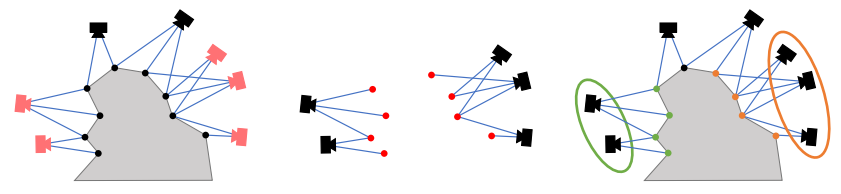
這一過程實際十分簡單,它是通過匹配同名點來獲取的,這些同名點在早先進行的3D建模過程中通過特征的提取與匹配已經建立了對應的關系。若兩個圖像中存在穩定的同名點,則認為二者共視,分成一類,否則分成兩類。
局部匹配與定位
一般認為圖像數量較多的類所對應的場景是正確場景的可能性較大。因此從這一場景開始,嘗試獲取相機位姿。獲取的方式主要依賴求解PnP問題,因此需要首先構建當前圖像的2D關鍵點在3D模型中的坐標位置。在尚不知道相機姿態前,這一信息的獲取需要首先匹配當前圖像和場景內的圖像,特別要匹配那些能夠對應到3D位置的2D特征點,若能夠匹配上則確定了當前圖像中的2D點和3D點的對應關系,繼而即可通過對PnP問題的求解獲取相機位姿。
總結
本博文基于當前被廣泛采用的分級視覺定位方法對在3D視覺領域廣泛使用的視覺定位方法進行了簡要介紹,其主要可以被分為三個步驟,即預檢索、共視聚類、局部匹配與定位,最終通過求解PnP問題來獲取當前圖像的位姿,從而確定拍攝者的位置。筆者后續將繼續保持對3D視覺領域的研究和關注,并繼續輸出相關博文。
編輯:lyn
-
定位
+關注
關注
5文章
1401瀏覽量
35809 -
3D模型
+關注
關注
1文章
72瀏覽量
16302 -
3D視覺
+關注
關注
4文章
447瀏覽量
28059
發布評論請先 登錄
英倫科技裸眼3D便攜屏有哪些特點?


3D 視覺定位技術:汽車零部件制造的智能變革引擎
探索3D視覺技術在活塞桿自動化抓取中的應用

微視傳感高性能3D視覺產品亮相2024上海機器視覺展
3D視覺技術廣闊的應用前景

居然還有這樣的10.1寸光場裸眼3D視覺訓練平板電腦?
裸眼3D筆記本電腦——先進的光場裸眼3D技術
蘇州吳中區多色PCB板元器件3D視覺檢測技術

3D視覺定位系統在汽車零部件制造業中扮演著重要角色
英倫科技裸眼3D平板電腦:革新視覺體驗,重塑價格優勢
除了令人驚嘆的裸眼3D顯示技術,英倫科技裸眼3D視覺訓練一體機還具備哪些特點?
VIVERSE 推行實時3D渲染: 探索Polygon Streaming技術力量與應用





 工商網監
工商網監

評論