 Linux下最常用命令之一copy引發的思考
Linux下最常用命令之一copy引發的思考
cp 引發的思考
cp 是啥 ? 是的,就是 Linux 是 Linux 下最常用的命令之一,copy 的簡寫,小伙伴 100% 都用過。
cp 命令處于 Coreutils 庫里,是 GNU 項目維護的一個核心項目,提供 Linux 上核心的命令。
今天用 cp 命令,把小伙伴驚到了,引發了我對其中細節的思考。
背景是這樣的,奇伢今天用 cp 拷貝了一個 100 GiB 的文件,竟然一秒不到就拷貝完成了。一個 SATA 機械盤的寫能力能到 150 MiB/s (大部分的機械盤都是到不了這個值的)就算非常不錯了,所以,正常情況下,copy 一個 100G 的文件至少要 682 秒 ( 100 GiB/ 150 MiB/s ),也就是 11 分鐘。
sh-4.4# time cp 。/test.txt 。/test.txt.cp
real 0m0.107s
user 0m0.008s
sys 0m0.085s
上面是我們理論分析,最少要 11 分鐘,實際情況卻是我們 cp 一秒沒到就完成了工作,驚呆了,為啥呢?并且還有一個更詭異的我文件系統大小才 40 GiB,為啥里面會有一個 100 G的文件呢?
分析文件
我們先用 ls 看一把文件,顯示文件確實是 100 GiB.
sh-4.4# ls -lh
-rw-r--r-- 1 root root 100G Mar 6 12:22 test.txt
但是再用 du 命令看卻只有 2M ,這是怎么回事?(且所在的文件系統總空間都沒 100G 這么大)
sh-4.4# du -sh 。/test.txt
2.0M 。/test.txt
再看 stat 命令顯示的信息:
sh-4.4# stat 。/test.txt
File: 。/test.txt
Size: 107374182400 Blocks: 4096 IO Block: 4096 regular file
Device: 78h/120d Inode: 3148347 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 1200.888871000 +0000
Modify: 2021-03-13 1246.562243000 +0000
Change: 2021-03-13 1246.562243000 +0000
Birth: -
stat 命令輸出解釋:
Size 為 107374182400(知識點:單位是字節),也就是 100G ;
Blocks 這個指標顯示為 4096(知識點:一個 Block 的單位固定是 512 字節,也就是一個扇區的大小),這里表示為 2M;
劃重點:
Size 表示的是文件大小,這個也是大多數人看到的大小;
Blocks 表示的是物理實際占用空間;
所以,注意到一個新概念,文件大小和實際物理占用,這兩個竟然不是相同的概念。為什么會這樣?
這里先梳理下文件系統的基礎知識,文件系統究竟是怎么存儲文件的?(以 Linux 上 ext系列的文件系統舉例)
文件系統
文件系統聽起來很高大上,通俗話就用來存數據的一個容器而已,本質和你的行李箱、倉庫沒有啥區別。只不過文件系統存儲的是數字產品而已。我有一個視頻文件,我把這個視頻放到這個文件系統里,下次來拿,要能拿到我完整的視頻文件數據,這就是文件系統,對外提供的就是存取服務。
現實的存取場景
就跟你在火車站使用的寄存服務一樣,包裹我能存進去,稍后我能取出來,就可以了。問題來了,存進去?怎么取?仔細回憶下存儲行李的場景。
存行李的時候,是不是要登記一些個人信息?對吧,至少自己名字要寫上。可能還會給你一個牌子,讓你掛手上,這個東西就是為了標示每一個唯一的行李。
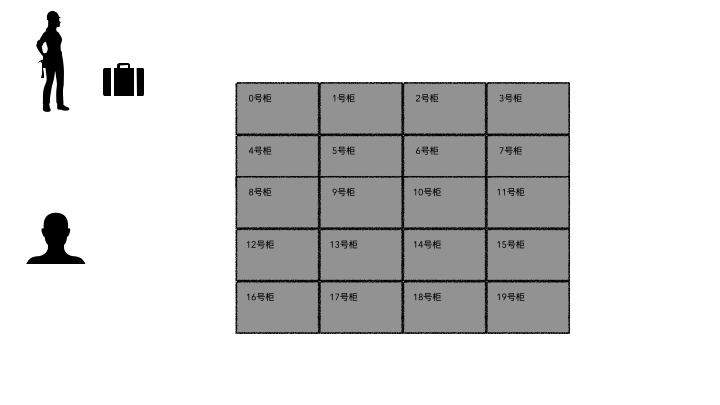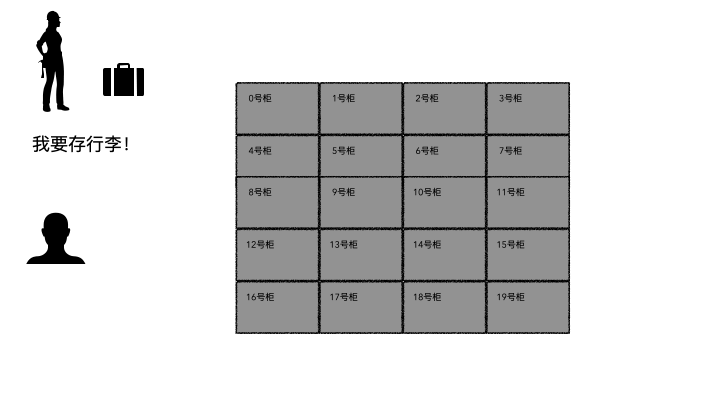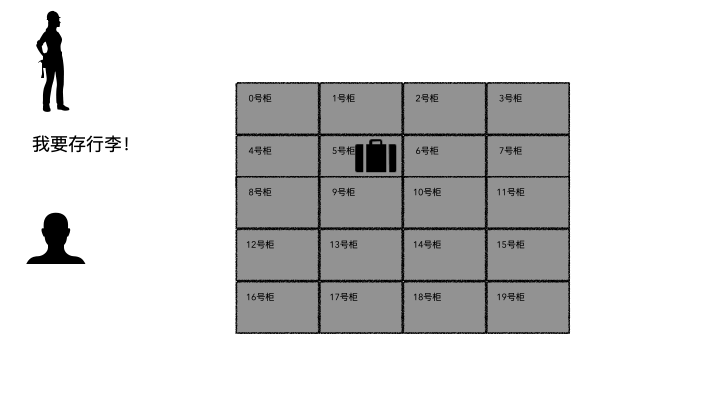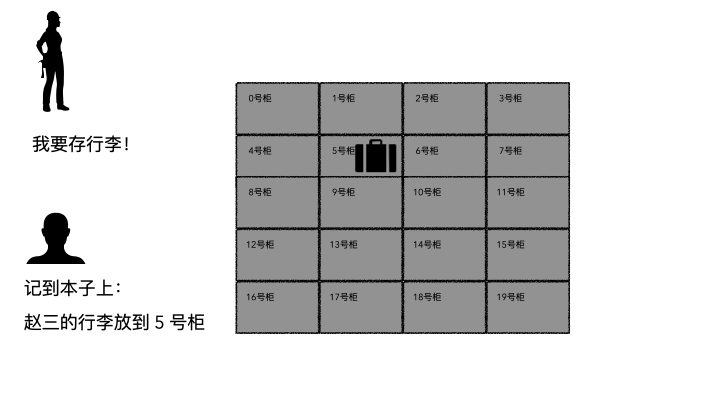
取行李的時候,要報自己名字,有牌子的給他牌子,然后工作人員才能去特定的位置找到你的行李(不然機場那么多人,行李都長差不多,他肯定不知道你的行李是哪個)。
劃重點:存的時候必須記錄一些關鍵信息(記錄ID、給身份牌),取的時候才能正確定位到。
文件系統
回到我們的文件系統,對比上面的行李存取行為,可以做個簡單的類比;
登記名字就是在文件系統記錄文件名;
生成的牌子就是元數據索引;
你的行李就是文件;
寄存室就是磁盤(容納東西的物理空間);
管理員整套運行機制就是文件系統;
上面的對應并不是非常嚴謹,僅僅是幫助大家理解文件系統而已,讓大家知道其實文件系統是非常樸實的一個東西,思想都來源于生活。
劃重點:文件系統的存儲介質是磁盤,文件系統是軟件層面的,是管理員,管理怎么使用磁盤空間的軟件系統而已。
空間管理
現在思考文件系統是怎么管理空間的?
如果,一個連續的大磁盤空間給你使用,你會怎么使用這段空間呢?
直觀的一個想法,我把進來的數據就完整的放進去。

這種方式非常容易實現,屬于眼前最簡單,以后最麻煩的方式。因為會造成很多空洞,明明還有很多空間位置,但是由于整個太大,形狀不合適(數據大小),哪里都放不下。因為你要放一個完整的空間。
這種不能利用的空間我們稱之為碎片,準確的說是外部碎片,這種碎片在內存池分配內存的時候最常見,產生的原理是一樣的。
怎么改進?有人會想,既然整個放不進去,那就剁碎了唄。這里塞一點,那里塞一點,就塞進去了。
對,思路完全正確。改進的方式就是切分,把空間按照一定粒度切分。每個小粒度的物理塊命名為 Block,每個 Block 一般是 4K 大小,用戶數據存到文件系統里來自然也是要切分,存儲到每一個 Block 。Block 粒度越小則外部碎片則會越少(注意:元數據量會越大),可以盡可能的利用到空間,并且完整的用戶數據文件存儲到磁盤上則不再連續,而是切成一個個 Block 大小的數據塊存到磁盤的各個角落上。
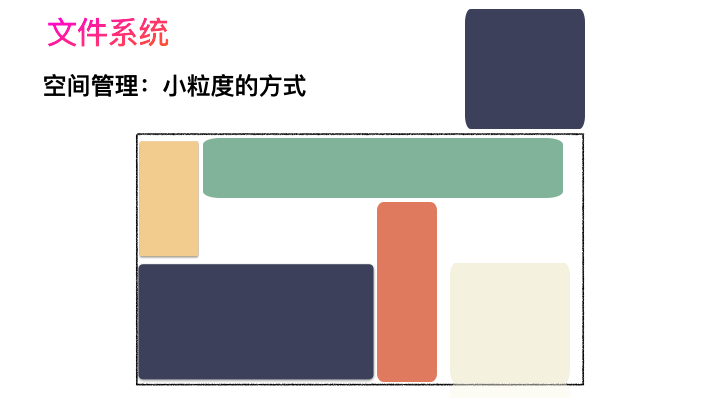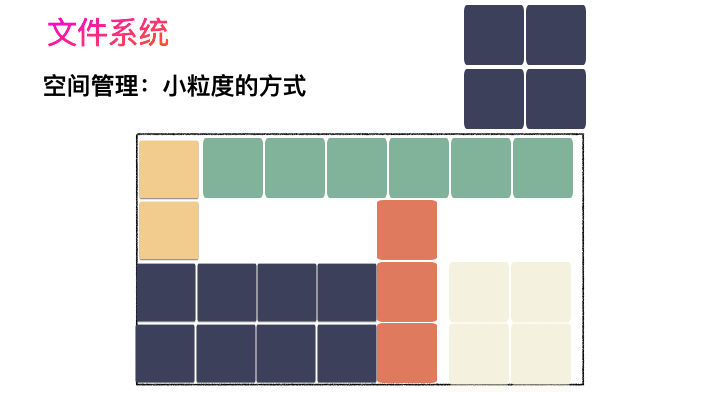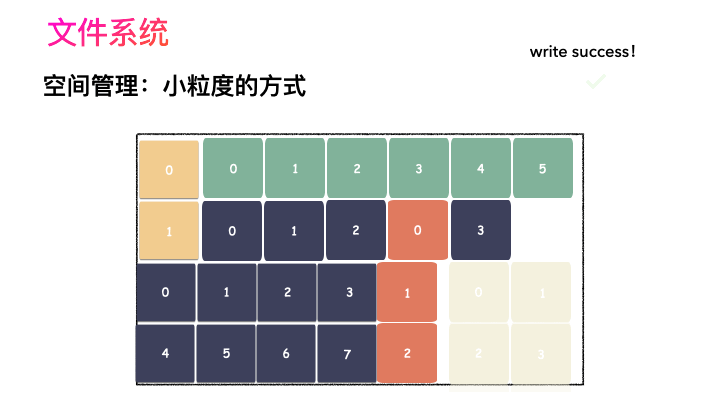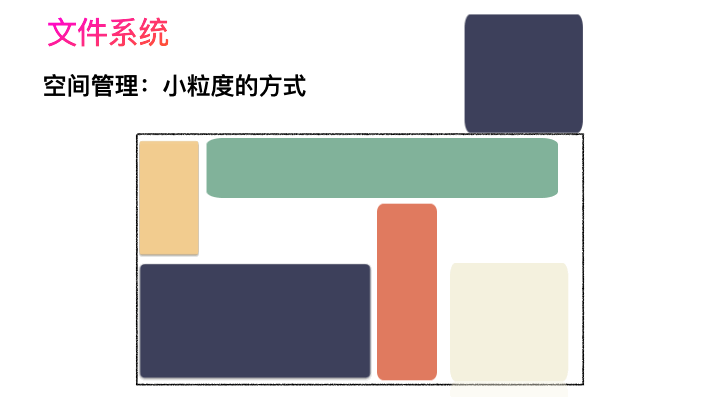
圖示標號表示這個完整對象的 Block 的序號,用來復原對象用的。
隨之而來又有一個問題:你光會切成塊還不行,取文件數據的時候,要給完整的用戶數據出去,用戶不管你內部怎么實現,他只想要的是最初的樣子。所以,要有一個表記錄該文件對應所有 Block 的位置,要把每一個 Block 的位置記錄好,取文件的時候,對照這表恢復出一個完整的塊給到用戶。
所以,寫流程再完善一下就是這樣子:
先寫數據:數據先按照 Block 粒度存儲到磁盤的各個位置;
再寫元數據:然后把 Block 所在的各個位置保存起來,這也就是元數據,文件系統里叫做 inode(我用一本書來表示);

文件讀流程則是:
先讀元數據,找到各個 Block 的位置;
然后讀數據,構造一個完整的文件,給到用戶;
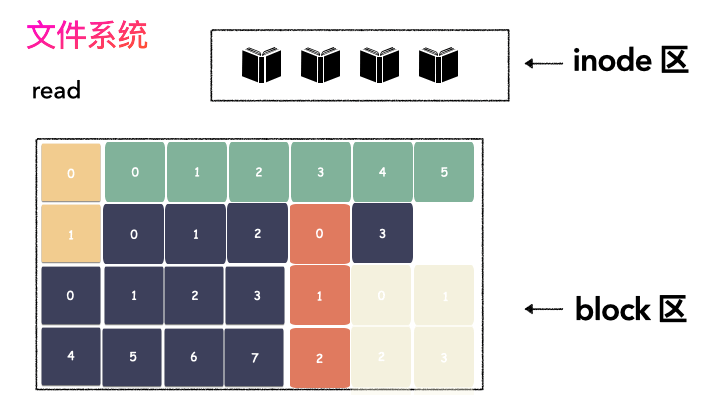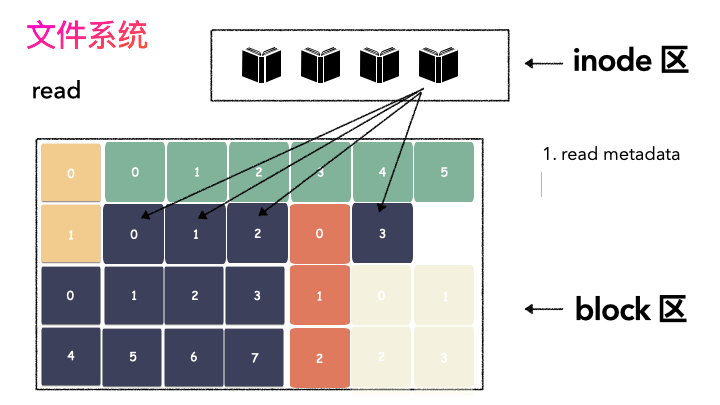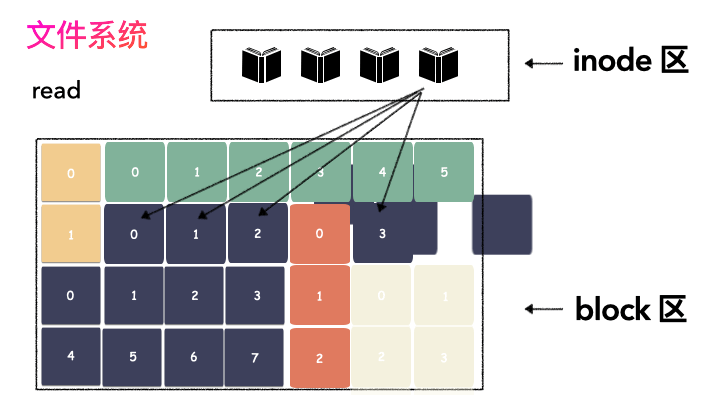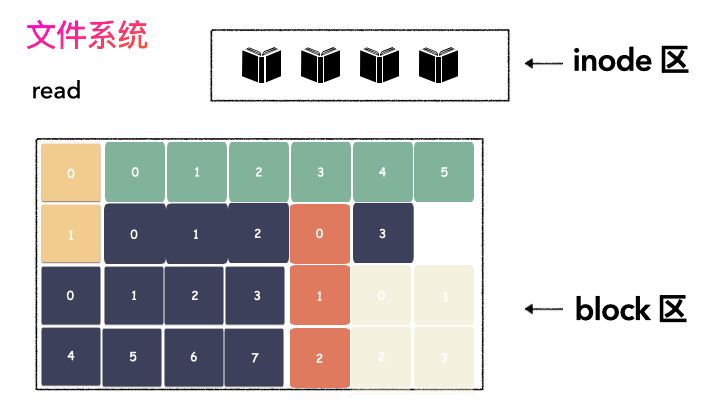
inode/block 概念
好,現在我們引出了兩個概念:
磁盤空間是按照 Block 粒度來劃分空間的,存儲數據的區域全都是 Block,我們叫做數據區域;
文件存儲不再連續存儲在磁盤上,所以需要記錄元數據,這個我們叫做 inode;
文件系統中,一個 inode 唯一對應一個文件,inode 的個數則是在文件系統格式化的時候就確定好了的,換言之,一個 local 文件系統支持的文件數是天然就有上限的。
block 固定大小,每個 4k(大部分文件系統都是,這里不做糾結),block 意圖存儲打散的用戶數據。
無論是 inode 區,還是 block 區,本質上都是在線性的磁盤空間上。文件系統的空間層次如下:

一個文件的對應一個 inode,這個文件需要按照 Block 切分存儲在磁盤上,存儲的位置則由 inode 記錄起來,通過 inode 則能找到 block,也就獲取到用戶數據。
現在有一個新的小問題,inode 區和 block 區都是在初始化就構造好的。存儲一個文件的時候,需要取一個空閑的 inode,然后把數據切分成 4k 大小存儲到空閑的 block 上,對吧?
劃重點:空閑的inode,空閑的 block。 這個很關鍵,已經存儲了數據的地方不能再讓寫,不然會把別人的數據覆蓋掉。
那么,怎么區分空閑和已經在用的 inode ,block 呢?
答案是 :inode 區和 block 區分別需要另一張表,用來表示 inode 是否在用,block 是否在用,這個表的名字我們叫做 bitmap 表。bitmap 是一個 bit 數組,用 0 表示空閑,1 表示在用,如下:
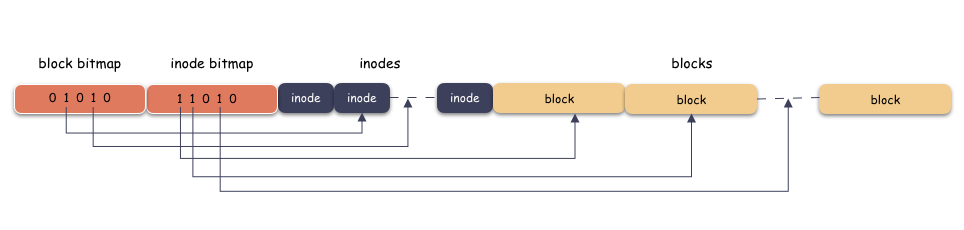
bitmap 什么時候用呢?自然是寫的時候,也就是分配 inode 或者 block 的時候,因為只有分配的時候,你才需要找空閑的空間。
上圖我為了突出本質思想,類似于超級塊,塊描述符都省略了,這個感興趣可以自己擴展,這里只突出主干哈。
小結一下:
bitmap 本質是個 bit 數組,占用空間極其少,用 0 來表示空閑,1 表示在用。使用時機是在創建文件,或者寫數據的時候;
inode 則對應一個文件,里面存儲的是元數據,主要是數據 block 的位置信息;
block 里面存儲的是用戶數據,用戶數據按照 block 大小(4k)切分,離散的分布在磁盤上。讀的時候只有依賴于 inode 里面記錄的位置才能恢復出完整的文件;
inode 和 block 的總個數在文件系統格式化的時候就確定了,所以文件數和文件大小都是有上限的;
一個文件真實的模樣
上面是抽象的樣子,現在我們看一個真實的 inode -》 block 的樣子。一個文件除了數據需要存儲之外,一些元信心也需要存儲,例如文件類型,權限,文件大小,創建/修改/訪問時間等,這些信息存在 inode 中,每個文件唯一對應一個inode 。
看一下 inode 的數據結構(就以 linxu ext2 為例,該結構定義在 linux/fs/ext2/ext2.h 頭文件中 ):
struct ext2_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
__le32 i_file_acl; /* File ACL */
__le32 i_dir_acl; /* Directory ACL */
__le32 i_faddr; /* Fragment address */
};
重點:
上面的結構 mode,uid,size,time 等信息就是我們常說的文件類型,大小,創建修改等時間元數據;
注意到 i_block[EXT2_N_BLOCKS] 這個字段,這個字段將會帶你找到數據, 因為里面存儲的就是 block 所在的位置,也就是 block 的編號;
再來,理解下什么叫做 block 的位置(編號)。

位置就是編號,記錄位置就是記錄編號,編號就是索引。
我們看到有一個數組:i_block[EXT2_N_BLOCKS],這個數組是存儲 block 位置的數組。其中 EXT2_N_BLOCKS 是一個宏定義,值為 15 。也就是說,i_block 是一個 15 個元素的數組,每個元素是 4 字節(32 bit)大小。
舉個例子,假設我們現在有一個 6k 的文件,那么只需要 2 個 block 就可以存下了,假設現在數據就存儲在編號為 3 和 101 這兩個 block 上,那么如下圖:
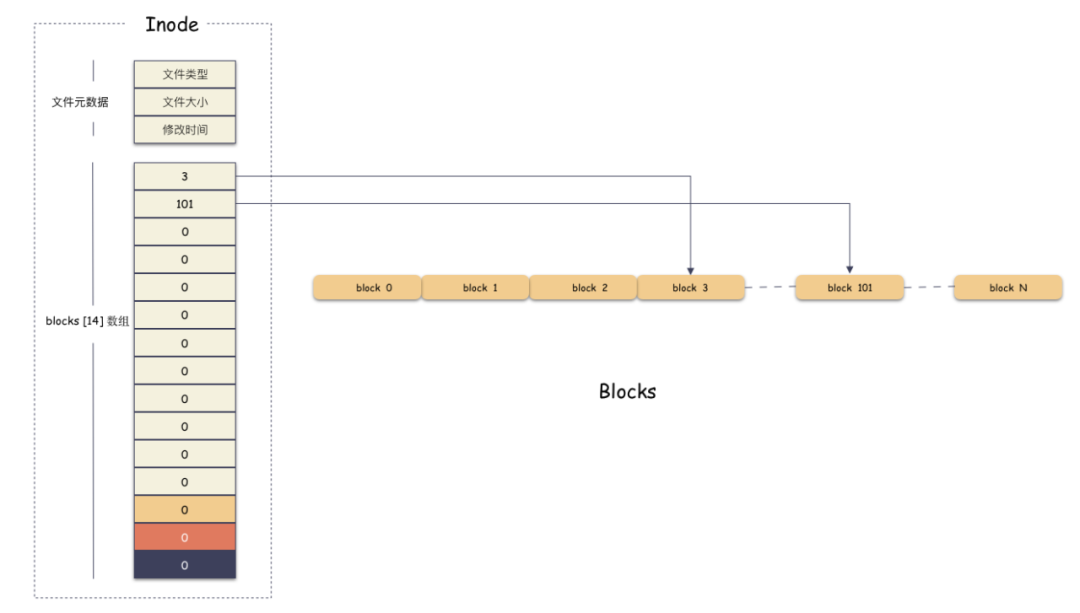
i_block[15] 第一個元素存的是 3,第二個存儲的是 101,其他槽位沒用用到,由于 inode 的內存是置零分配的,所以里面的值為 0,表示沒有在使用 。 我們通過 [3, 101] 這兩個 block 就能拼裝出完整的用戶數據了。用戶的 6k 文件組成如下:
第一個 4k 數據在 [3*4K, 4*4K] 范圍;
第二個 2k 數據在 [ 101*4K, 101*4K+2K] 范圍;
好,現在我們知道了每個定長 block 都有唯一編號,我們的 i_block[15] 數組 通過有序存儲這個編號找到文件數據所在的位置,并且拼裝出完整文件。
思考問題:區分文件的切分成 4k 塊的編號和 磁盤上物理 4k 塊的編號的區別。
舉個栗子,一個文件 12K 的大小,那么按照 4K 切分會存儲到 3 個 物理 block 上。
文件第 0 個 4k 存儲到了 101 這個物理 block 上;文件第 1 個 4k 存儲到了 30 這個物理 block 上;文件第 2 個 4k 存儲到了 11 這個物理 block 上;
文件邏輯空間上的編號是從 0 開始,到 2 結束,對應存儲的物理塊編號分別是 101,30,11 。
思考問題:這么一個 inode 結構能夠表示多大的文件?
我們看到 inode-》i_block[15] 是一個一維數組,里面能存 15 個元素。也就是能存 15 個 block 的編號,那么如果直接存儲文件的 block 編號最大能表示 60K (15*4K) 的文件。換句話說,如果我拿著 15 個槽位全部用來存儲文件的編號,這個文件系統支撐的最大文件卻就是 60K。驚呆了?(注意:ext2 文件系統是可以創建 4T 以內的文件的!!)
那我們自然會思考,怎么解決呢?怎么才能支撐更大的文件?
最直接思考就是用更大的數組,把 inode-》i_block 數組變得更大。比如,如果你想要支持 100G 的文件:
那么,需要 i_block 數組大小為 26214400 (計算公式:100*1024*1024/4),也就是要分配一個 i_block[26214400] 的數組。
每個編號占用 4 字節,這個數組就占用 100M 的空間(計算公式:(26214400*4)/1024/1024)。100M !這里就有點夸張了,注意到 i_block 只是一個 inode 內部的字段,是一個靜態分配的數組,也就是說,這個文件系統為了支持最大 100G 的文件存入,每一個 inode 都要占用 100M 的內存,就算你是一個 1K 的文件,inode 也會占用這么大的內存空間。并且,這種方案擴展性差,支持的文件 size 越大,i_block[N] 消耗內存情況越嚴重。這是無法接受的。
思考問題:怎么才能讓你既能表示更大的文件,又能不浪費占用空間?
我們仔細分析這個問題,你會發現,這里有 2 個核心問題:
第一點,核心在于浪費內存空間(關鍵點是要保證 inode 內存結構的穩定,無論文件怎么變,inode 結構本身不能變);
第二點,仔細思考你會發現,無論是什么神仙方案,如果你要存儲一個按照 4k 切分的 100G 文件,都是需要 100M 的空間來存儲索引( block 編號),但是 99.99% 的文件可能都沒有這么大;
我們前面用一個大數組來一把存儲 block 編號的方案固然簡單,但是問題在于太過死板。核心問題在于存儲 block 編號的數組是預分配的,為了還沒有發生并且 99% 場景都不會發生的事情(文件大小達到 100G),卻不管三七二十一,提前準備好了完整的 block 索引數組,預分配就是浪費的根源。
那么知道了這兩個問題,下一步分析下一個個解決:
索引存磁盤
問題一的解決:索引存磁盤:
既然問題在于浪費內存,inode 內存分配不靈活,那就可以看把 inode-》i_block 下放到磁盤。
為什么?
因為磁盤的空間比內存大了不止一個量級。100M 對內存來說很大,對磁盤來說很小。換句話說,用把用戶數據所在的 block 編號存到磁盤上去,這個也需要物理空間,使用的也是 block 來存儲,只不過這種 block 存儲的是 block 編號信息,而不是用戶數據。
那么我們怎么通過 inode 找到用戶數據呢?
因為這個 block 本身也有編號,我們則需要把這個存儲用戶 block 編號的 block 所在塊的編號存儲在 inode-》i_block[15] 里,當讀數據的時候,我們需要先找到這個存儲編號的 block,然后再通過里面存儲的用戶數據所在的 block 編號找到用戶所在的 block ,去讀數據。
這個存儲用戶 block 編號的 block 所在塊的編號我們叫做間接索引,然后我們根據跳轉的次數可以分類成一級索引,二級索引,三級索引。顧名思義,一級索引就是跳轉 1 次就能定位到用戶數據,二級索引就是跳轉 2 次,三級索引就是跳轉 3 次才能定位到用戶數據。那么 inode-》i_block[15] 里面存儲的可以直接定位到用戶數據的 block 就是直接索引。
終于可以說回 ext2 的使用了,ext2 的 inode-》i_block[15] 數組。知識點來了,按照約定,這 15 個槽位分作 4 個不同類別來用:
前 12 個槽位(也就是 0 - 11 )我們成為直接索引;
第 13 個位置,我們稱為 1 級索引;
第 14 個位置,我們稱為 2 級索引;
第 15 個位置,我們稱為 3 級索引;

好,那我們在來看下直接索引,一級,二級,三級索引的表現力。
直接索引:能存 12 個 block 編號,每個 block 4K,就是 48K,也就是說,48K 以內的文件,只需要用到 inode-》i_block[15] 前 12 個槽位存儲編號就能完全 hold 住。
一級索引:
inode-》i_block[12] 這個位置存儲的是一個一級索引,也就是說這里存儲的編號指向的 block 里面存儲的也是 block 編號,里面的編號指向用戶數據。一個 block 4K,每個元素 4 字節,也就是有 1024 個編號位置可以存儲。
所以,一級索引能尋址 4M(1024 * 4K)空間 。
二級索引:
二級索引是在一級索引的基礎上多了一級而已,換算下來,有了 4M 的空間用來存儲用戶數據的編號。所以二級索引能尋址 4G (4M/4 * 4K) 的空間。
三級索引:
三級索引是在二級索引的基礎上又多了一級,也就是說,有了 4G 的空間來存儲用戶數據的 block 編號。所以二級索引能尋址 4T (4G/4 * 4K) 的空間。
最后,看一眼完整的表示圖:
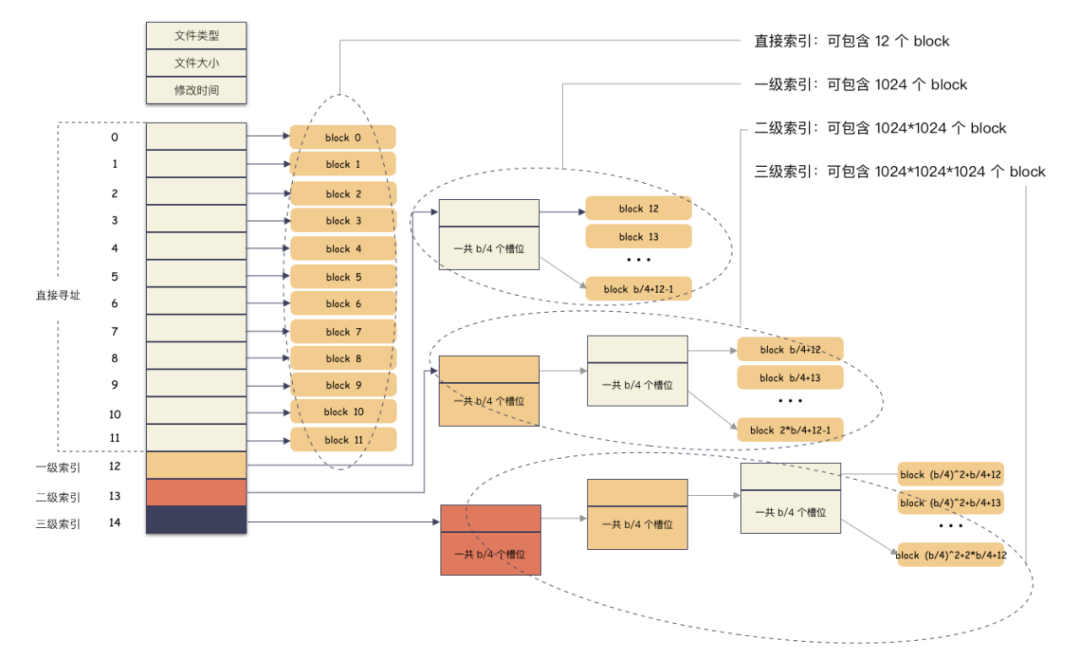
所以,在我們 ext2 的文件系統上,通過這種間接塊索引的方式,最大能支撐的文件大小 = 48K + 4M + 4G + 4T ,約等于 4 T。文件系統最大支撐 16T 空間,因為 4 Byte 的整形最大數就是 2^32=4294967296 , 乘以 4K 就等于 16 T。
ext2 文件系統支持的最大單文件大小和文件系統最大容量就是這么算出來的(溫馨提示:ext4 文件系統不僅兼容間接塊的實現,還使用的是 extent 模式來管理的空間,最大支持單文件 16 TB ,文件系統最大 1 EB)。
思考:這種多級索引尋址性能表現怎么樣?
在不超過 12 個數據塊的小文件的尋址是最快的,訪問文件中的任意數據理論只需要兩次讀盤,一次讀 inode,一次讀數據塊。訪問大文件中的數據則需要最多五次讀盤操作:inode、一級間接尋址塊、二級間接尋址塊、三級間接尋址塊、數據塊。
多級索引和后分配
問題二解決:多級索引和后分配
一級索引不夠,表現力太差,預留空間又太浪費,不預留空間又無法擴展,怎么解決?
既然問題在于預分配,我們使用后分配(瘦分配,或精簡分配)解決。也就是說用戶文件數據有多大,我才分配出多大的數組。舉個例子,我們存儲 100 G 的文件,那么就要用到三級索引塊,最多分配 26214400 個槽位的數組(因為要 26214400 個 block)。如果是存儲 6K 的文件,那么只需要 2 個槽位的數組。
索引數組的后分配
后分配這里說的是 block 索引編號數組的后分配,需要用到的時候才分配,而不是說,現在用戶存儲一個 1k 的文件,我上來就給他分配一個 100M 的索引數組,只是為了以后這個文件可能增長到 100 G。
數據的后分配
既然這里說到,關于后分配還有一個層面,就是數據所占的空間也是用到了才分配,這個也就是涉及到今天 cp的秘密的核心問題。
實際的栗子
先看下下正常的文件寫入要做的事情(注意這里只描述主干,實際流程可能,有優化):
創建一個文件,這個時候分配一個 inode;
在 [ 0,4K ] 的位置寫入 4K 數據,這個時候只需要 一個 block 假設編號 102,把這個編號寫到 inode-》i_block[0] 這個位置保存起來;
在 [ 1T,1T+4K ] 的位置寫入 4K 數據,這個時候需要分配一個 block 假設編號 7,因為這個位置已經落到三級索引才能表現的空間了,所以需要還需要分配出 3 個索引塊;
寫入完成,close 文件;
這里解釋下文件偏移位置 [1T, 1T+4K] 為什么落到三級索引。
offset 為 1T,按照 4K 切分,也就是 block 268435456 塊(注意這個是虛擬文件塊,不是物理位置);
先算出范圍:直接索引的范圍是 [0, 11] 個,一級索引 [12, 1035],二級索引 [1036, 1049611], 三級索引 [1049612, 1074791435],(有人如果不知道怎么來的話,可以往前看看 inode 的結構,直接索引 12個,一級索引 1024 個,二級 1M 個,三級 1G 個,然后算出來的);
268435456 落在三級索引 [1049612, 1074791435] 這個范圍;
實際存儲如圖:
計算索引:
12 + 1024 + 1024 * 1024 + 1024 * 1024 * 254 + 1024 * 1022 + 1012 = 268435456
實際的物理分配如圖:
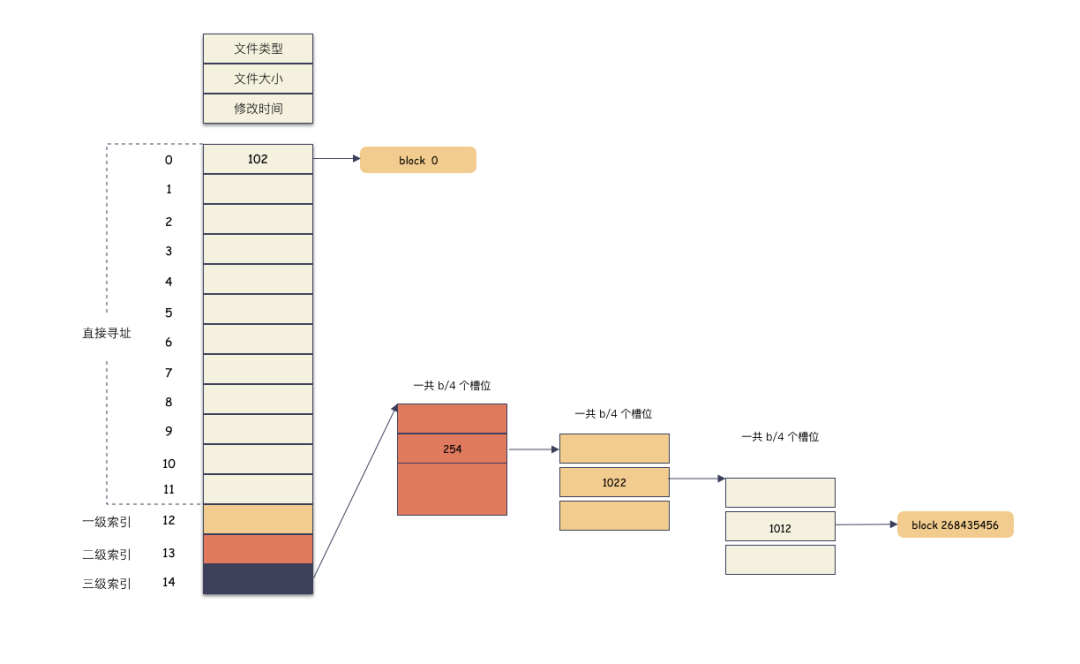
因為偏移已經用到了 3 級索引,所以除了用戶數據的兩個 block ,中間還需要 3 個間接索引 block 分配出來。
如果要讀 [1T, 1T+4K] 這個位置的數據怎么辦?
流程如下:
計算 offset 得出在第 268435456 的位置;
讀出三級索引 inode-》i_block[14] 里存儲的 block 編號,找到對應的物理 block,這個是第一級的 block;
然后讀該 block 的第 254+1 個槽位里的數據,里面存儲的是第二級的 block 編號,把這個編號讀出來,通過這個編號找到對應的物理 block;
讀該 block 的第 1022 +1 個操作的數據,里面存儲的是第三級的 block 編號,通過這個編號可以找到物理 block 的數據,里面存儲的是用戶數據所在 block 的編號;
讀該 block 第 1012+1 個槽位里存儲的編號,找到物理 block,這個 block 里存的就是用戶數據了;
這個時候,我們的文件看起來是超大文件,size 等于 1T+4K ,但里面實際的數據只有 8 K,位置分別是 [ 0,4K ] ,[ 1T,1T+4K ]。
重點:文件 size 只是 inode 里面的一個屬性,實際物理空間占用則是要看用戶數據放了多少個 block 。
劃重點:沒寫數據的地方不用分配物理 block 塊。
沒寫數據不分配物理塊?那是什么?那就是我們下面要說的稀疏文件。
文件的稀疏語義
什么是稀疏文件
終于到我們文件的稀疏語義了,稀疏語義什么意思?
稀疏文件英文名 sparse file 。稀疏文件本質上就是計算機文件,用戶不感知,文件系統支持稀疏文件只是為了更有效率的使用磁盤空間而已。稀疏文件就是后分配空間的一種實現形式,做到真正用時才分配,最大效率的利用磁盤空間。
就以上面舉的栗子,文件大小 1T,但是實際數據只有 8K,這種就是稀疏文件,邏輯大小和實際物理空間是可以不等的。文件大小只是一個屬性,文件只是數據的容器,沒有用戶數據的位置可以不分配空間。
為什么要支持稀疏語義?
還是以上面 1T 的文件舉例,如果這 1T 的文件只有首尾分別寫了 4K 的數據,而文件系統卻要分配 1T 的物理空間,這里將帶來巨大的浪費。何不等存了用戶數據的時候再分配了,實際數據有多少,才去分配多大的 block ,何必著急的預分配呢?
后分配本著用多少給多少的原則,盡量有效的利用空間。
后分配還有一個優點,這也減少了首次寫入的時間,怎么理解?
因為,如果文件大小 1T,就要分配 1T 的空間,那么初始分配需要寫入全零到空間,否則上面的數據可能是隨機數。
對于稀疏文件空洞的地方,不占用物理空間,但要保證讀的時候返回全 0 數據的語義,即可。
又一個知識點:有時候稀疏文件的空洞和用戶真正的全 0 數據是無法區分的,因為對外表現是一樣的。
稀疏文件也要文件系統支持,并不是所有的文件系統都支持稀疏語義,比如 ext2 就沒有,ext4 才有稀疏語義,支持的標志是實現文件系統的 fallocate 接口。
怎么創建一個稀疏文件?
可以使用 truncate 命令在一個 ext4 的文件系統創建一個文件。
truncate -s 100G test.txt
你 ls -lh 。/test.txt 命令看會發現是一個 100 G 的文件;
但是 du -sh 。/test.txt 會發現是一個 0 字節的文件;
stat 。/test.txt 會發現是 Size: 107374182400 Blocks: 0 的文件;
這就是一個典型的稀疏文件。size 只是文件的邏輯大小,實際的物理空間占用還是得看 Blocks 這個數值。
下面這種 1T 的文件,因為只寫了頭尾 8K 數據,所以只需要分配 2 個 block 存儲用戶數據即可。
好,我們再深入思考下,文件系統為什么能做到這個?
這也是為什么理解稀疏語義要先了解文件系統的實現的原因。
首先,最關鍵的是把磁盤空間切成離散的、定長的 block 來管理;
然后,通過 inode 能查找到所有離散的數據(保存了所有的索引);
最后,實現索引塊和數據塊空間的后分配;
這三點是層層遞進的。
稀疏語義接口
為了知識的完整性,簡要介紹稀疏語義的幾個接口:
preallocate(預分配):提供接口可以讓用戶預占用文件內指定范圍的物理空間;
punch hole(打洞):提供接口可以讓用戶釋放文件內指定范圍的物理空間;
這兩個操作剛好相反。
預分配的意思是?
就是說,當你創建一個 1T的文件,如果你沒寫數據,這個時候其實沒有分配物理空間的,支持稀疏語義的文件系統會提供一個 fallocate 接口給你,讓你實現預分配,也就是說把這 1T 的物理空間現在就分配出來。
思考:這個有什么好處呢?
第一,如果你命中注定要 1T 的空間,預分配是有好處的,把空間分配的工作量集中在初始化的時候一把做了,避免了實時現場分配的開銷;
第二,如果不提前占坑,很有可能等你想要的時候已經沒有空間可占用了。所以你把物理空間先占好,就可以安心使用了;
linux 提供了一個 fallocate 命令,可以用來預分配空間。
fallocate -o 0 -l 4096 。/test.txt
這個命令的意思就是給 text.txt 這個文件 [0, 4K] 的位置分配好物理空間。
打洞(punch hole) 是干啥的呢?
這個調用允許你把已經占用的物理空間釋放掉,從而達到快速釋放的目的。這種操作在虛擬機鏡像的場景用得多,通常用于快速釋放空間,punch hole 能夠讓業務更有效的利用空間。
linux 提供了一個 fallocate 命令也可以用來 punch hole 空間。
fallocate -p -o 0 -l 4096 。/test.txt
這個命令的意思是把 test.txt [ 0, 4K ] 的物理空間釋放掉。
Go 語言實現
稀疏文件本身和編程語言無具體關系,可以用任何語言實現,我下面以 Go 為例,看下稀疏文件的預分配和打洞(punch hole)是怎么實現的。
預分配實現:
func PreAllocate(f *os.File, sizeInBytes int) error {
// use mode = 1 to keep size
// see FALLOC_FL_KEEP_SIZE
return syscall.Fallocate(int(f.Fd()), 0x0, 0, int64(sizeInBytes))
}
punch hole 實現:
// mode 0 change to size 0x0
// FALLOC_FL_KEEP_SIZE = 0x1
// FALLOC_FL_PUNCH_HOLE = 0x2
func PunchHole(file *os.File, offset int64, size int64) error {
err := syscall.Fallocate(int(file.Fd()), 0x1|0x2, offset, size)
if err == syscall.ENOSYS || err == syscall.EOPNOTSUPP {
return syscall.EPERM
}
return err
}
可以看到,本質上都是系統調用 fallocate ,然后帶不同的參數而已。指定文件偏移和長度,就能預分配物理空間或者釋放物理空間了。
這里有一個知識點:punch hole 的調用要保證 4k 對齊才能釋放空間。
舉個例子,比如:
punch hole [0, 6k] 的數據,你會發現只有 [0, 4k] 的數據物理塊被釋放了,[4k, 6k] 所占的 4k 物理塊還占著空間呢。
這個很容易理解,因為磁盤的物理空間是劃分成 4k 的 block,這個是最小單位了,不能再分了,你無法切割一個最小的單位。
值得注意的是,就算你沒有 4k 對齊的發送調用,fallocate 也不會報錯,這個請注意了。
cp 的秘密
鋪墊了這么久的基礎知識,終于到我們的 cp 命令的解密了。回到最開始的問題,cp 一個 100G 的文件 1 秒都不到,為什么這么快?
說到現在,這個問題就很清晰了,這個 100G 的文件是個稀疏文件,盲猜一手:cp 的時候只拷貝了有效數據,空洞是直接跳過的。 往前看 stat 命令和 ls 命令顯示的差距就知道了。
接下來我們具體看一下 cp 的實現。
cp 有一個參數 --sparse 很有意思,sparse 這個參數控制這 cp 命令對稀疏文件的行為,這個參數有三個值可選:
--sparse=always :空間最省;
--sparse=auto :默認值,速度最快;
--sparse=never :吭呲吭呲 copy,最傻;
cp 默認的時候,sparse 是 auto 策略。auto,always,never 分別是什么策略呢?
spare 三大策略
auto 策略
默認的情況下,cp 會檢查源文件是否具有稀疏語義,對于不占物理空間的位置,目標文件不會寫入數據,從而形成空洞。
所以,對于我們的例子,真實的就只進行了 2M 的 IO ,預期的 100G 文件,只拷貝了 2M 的數據,自然飛快了,自然驚艷所有人。
auto 是默認策略,使用該模式的時候,cp 內部實現是通過系統調用拿到文件的空洞位置情況,然后對這些位置目標文件會保持空洞。
注意,不會對非空洞位置的文件內容做判斷,如果用戶數據占用了物理塊,但是是全 0 數據,這種情況下,auto 模式不會識別,會以全零的數據寫入到目標文件。這個是跟 always 最大的區別。
auto 策略下 cp 的文件的文件,size,物理 block 數量都和源文件一致。
always
這種方式是最激進的,追求空間的最小化。在 auto 的基礎之上,還多做了一步:對源文件內容做了判斷。
在讀出源數據之后,就算這塊數據位置在源文件不是空洞,也會自己在程序里做一次判斷,判斷是否是全 0 的數據,如果是,那么也會在目標文件里對應的位置創建空洞(不分配物理空間)。
這種方式則會導致源文件的 size 和目標文件一樣(三種策略下,文件size 都是不變的),但是 物理 blocks 占用卻更小。
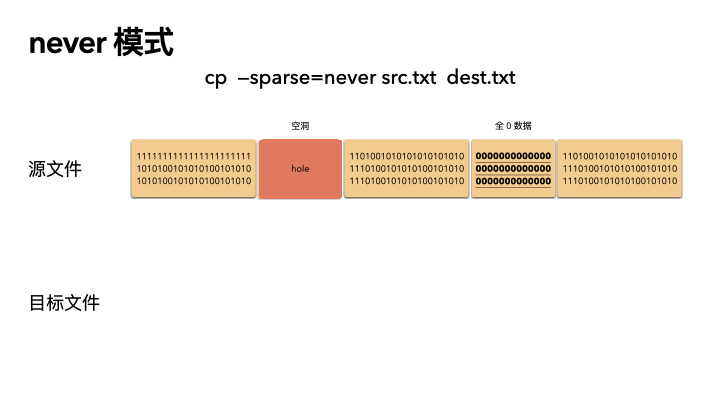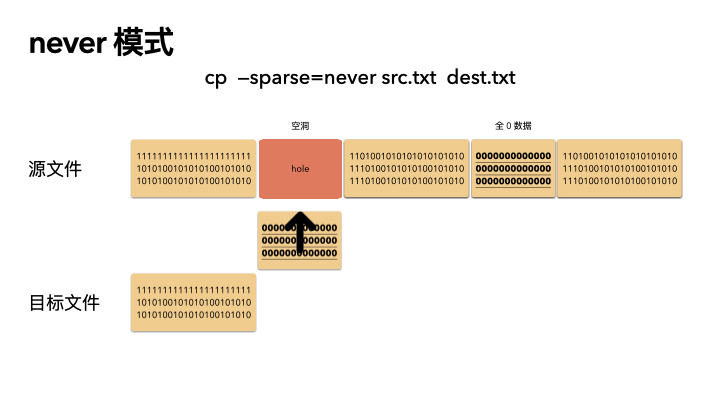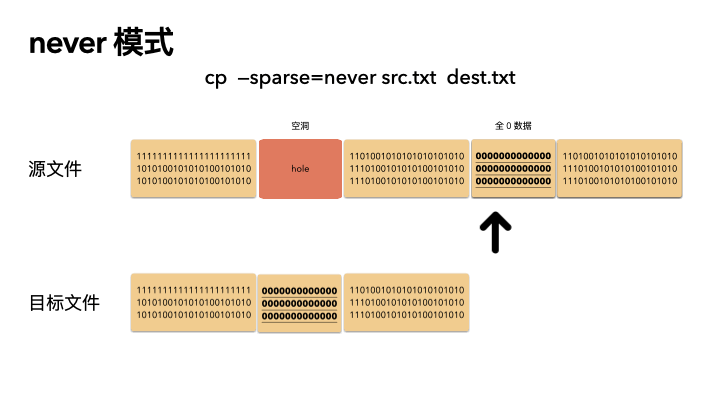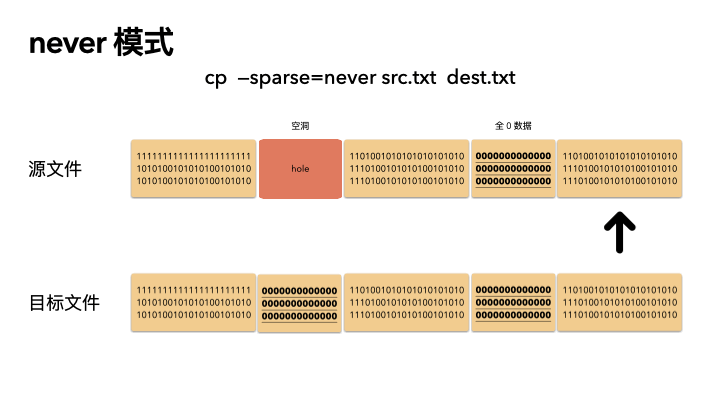
never
這種方式最保守,實現也最簡單。不管源文件是否是稀疏文件,cp 完全不感知,讀出來的任何數據都直接寫入目標文件。也就是說,如果一個 100G 的文件,就算只占用了 4K 的物理空間,也會創建出一個 100G 的目標文件,物理空間就占用 100G。
所以,如果你 cp 的時候帶了這個參數,那么將會非常非常慢。
深入剖析 cp --sparse 源碼
上面的都是結論,現在我們通過源碼再深入理解下 cp 的原理,一起圍觀下 cp 的代碼實現。
cp 命令源碼在 GNU 項目的 coreutils 項目中,為 Linux 提供外圍的基礎命令工具。看似極簡的 cp,其實代碼實現還挺有趣的。
cp 的入口代碼在 cp.c 文件中(以下基于 coreutils 8.30 版本):
以一個 cp 文件的命令舉例,我們一起走一下源碼視角的旅途:
cp 。/src.txt dest.txt
首先,在 main 函數里初始化參數:
switch (c)
{
case SPARSE_OPTION:
x.sparse_mode = XARGMATCH (“--sparse”, optarg,
sparse_type_string, sparse_type);
break;
這里會根據用戶傳入的參數,對應翻譯成一個枚舉值,該枚舉值就是 SPARSE_NEVER,SPARSE_AUTO,SPARSE_ALWAYS 其中之一,默認用戶沒帶這個參數的話,就會是 SPARSE_AUTO:
static enum Sparse_type const sparse_type[] =
{
SPARSE_NEVER, SPARSE_AUTO, SPARSE_ALWAYS
};
所以,main 函數里賦值了 x.sparse_mode 這個參數,這個參數也是稀疏文件行為的指導參數,后面怎么處理稀疏文件,就依賴于這個參數。
下面就是依次調用 do_copy ,copy,copy_internal 函數,do_copy,copy 這兩個函數就是處理一些封裝,校驗,包括涉及目錄的一些邏輯,跟我們本次稀疏文件解密關系不大,直接略過。
copy_internal 則是一個巨長的函數,里面的邏輯多數是一些兼容性,適配場景的考慮,也和本次關系不大。對于一個普通文件( regular 類型) 最終調用到 copy_reg 函數,才是普通文件 copy 的實現所在。
else if (S_ISREG (src_mode)
|| (x-》copy_as_regular && !S_ISLNK (src_mode)))
{
copied_as_regular = true;
// 普通文件的拷貝
if (! copy_reg (src_name, dst_name, x, dst_mode_bits & S_IRWXUGO,
omitted_permissions, &new_dst, &src_sb))
goto un_backup;
普通文件的 copy 就是從函數 copy_reg 才真正開始的。在這個函數里,首先 open 源文件和目標文件的句柄,然后進行數據拷貝。
static bool
copy_reg( 。.. )
{
// 確認要拷貝數據
if (data_copy_required)
{
// 獲取到塊大小,buffer 大小等參數
size_t buf_alignment = getpagesize ();
size_t buf_size = io_blksize (sb);
size_t hole_size = ST_BLKSIZE (sb);
bool make_holes = false;
// 關鍵函數來啦,is_probably_sparse 函數就是用來判斷源文件是否是稀疏文件的;
bool sparse_src = is_probably_sparse (&src_open_sb);
if (S_ISREG (sb.st_mode))
{
if (x-》sparse_mode == SPARSE_ALWAYS)
// sparse_always 模式,也是追求極致空間效率的策略;
// 所以這種方式不管源文件是否真的是稀疏文件,都會生成稀疏的目標文件;
make_holes = true;
// 如果是 sparse_auto 的策略,并且源文件是稀疏文件,那么目標文件也會是稀疏文件(也就是可以有洞洞的文件)
if (x-》sparse_mode == SPARSE_AUTO && sparse_src)
make_holes = true;
}
// 如果到這里判斷不是目標不會是稀疏文件,那么就使用更有效率的方式來 copy,比如用更大的 buffer 來裝數據,一次 copy 更多;
if (! make_holes)
{
// 略
}
// 源文件是稀疏文件的情況下,可以使用 extent_copy 這種更有效率的方式進行拷貝。
if (sparse_src)
{
if (extent_copy (source_desc, dest_desc, buf, buf_size, hole_size,
src_open_sb.st_size,
make_holes ? x-》sparse_mode : SPARSE_NEVER,
src_name, dst_name, &normal_copy_required))
goto preserve_metadata;
}
// 如果源文件判斷不是稀疏文件,那么就使用標準的 sparse_copy 函數來拷貝。
if (! sparse_copy (source_desc, dest_desc, buf, buf_size,
make_holes ? hole_size : 0,
x-》sparse_mode == SPARSE_ALWAYS, src_name, dst_name,
UINTMAX_MAX, &n_read,
&wrote_hole_at_eof))
{
return_val = false;
goto close_src_and_dst_desc;
}
// 略
}
}
以上對于 copy_reg 的代碼我做了極大的簡化,把關鍵流程梳理了出來。
小結:
copy_reg 函數才是真正 cp 一個普通文件的邏輯所在,源文件的打開,目標文件的創建和數據的寫入都在這里;
拷貝之前,會先用 is_probably_sparse 函數來判斷源文件是否屬于稀疏文件;
如果是 sparse always 模式,那么無論源文件是否是稀疏文件,那么都會嘗試生成稀疏的目標文件(這種模式下,源文件如果是非稀疏文件,會判斷是否是全 0 數據,如果是的話,還是會在目標文件中打洞);
如果是 sparse auto 模式,源文件是稀疏文件,那么生成的目標文件也會是稀疏文件;
源文件為稀疏文件的時候,會嘗試使用效率更高的 extent_copy 函數來拷貝數據;
如果是 never 模式,那么是調用 sparse_copy 函數來拷貝數據,并且里面不會嘗試 punch hole,拷貝過程會非常慢,會生成一個實打實的目標文件,物理空間占用完全和文件size一致;
上面的小結,提到幾個有意思的點,我們一起探秘下幾個問題。
問題一:is_probably_sparse 函數是怎么來判斷源文件的?
看了源碼你會發現,非常簡單,其實就是 stat 一下源文件,拿到文件大小 size,還有物理塊的占用個數(假設物理塊 512 字節),比一下就知道了。
static bool
is_probably_sparse (struct stat const *sb)
{
return (HAVE_STRUCT_STAT_ST_BLOCKS
&& S_ISREG (sb-》st_mode)
&& ST_NBLOCKS (*sb) 《 sb-》st_size / ST_NBLOCKSIZE);
}
舉個例子,文件大小 size 為 100G,物理占用塊 8 個,那么 100G/512字節 》 8,所以就是稀疏文件。
文件大小 size 為 4K,物理占用塊 8 個,那么 4K/512字節 == 8,所以就不是稀疏文件。
問題二:extent_copy 為什么更有效率?
關鍵在于里面的一個子函數 extent_scan_read 的實現,extent_scan_read 位于 extent-scan.c 文件中。extent_scan_read 位于 extent_copy 開頭,用來獲取到源文件的空洞位置信息。這個就是 extent_copy 高效率的根本原因。extent_scan_read 通過這個函數能夠拿到文件的空洞的詳細位置,那么拷貝數據的時候,就能針對性的跳過這些空洞,只拷貝有效的位置即可。
那么,不禁又要問, extent_scan_read 又是怎么實現的呢?
答案是:ioctl 系統調用,搭配 FS_IOC_FIEMAP 參數,也就是 fiemap 的調用。
/* Call ioctl(2) with FS_IOC_FIEMAP (available in linux 2.6.27) to obtain a map of file extents excluding holes. */
fiemap 這個是一個非常關鍵的特性,ioctl 搭配 FS_IOC_FIEMAP 這個函數能夠拿到文件的物理空間分配關系,能夠讓用戶知道長達 100G 的文件中,哪些位置才是真正有物理塊存儲數據的,哪些位置是空洞。
這個特性則由文件系統提供,也就是說,只有文件系統提供了這個對外接口,我們才能拿得到,比如 ext4,就支持這個接口,ext2 就沒有。
問題二:sparse_copy 為什么慢,里面喲是做了啥?
這個函數是標準的 copy 函數,對比 extent_copy 來說,沒有 fiemap 的加持,那么這個函數就自己判斷是否是空洞,怎么判斷?
sparse_copy 認為,只要大塊連續的全 0 數據,那么就認為是空洞,目標文件就不用寫入,直接打洞即可。
判斷是否全 0 的函數是is_nul,位于 system.h 頭文件中,實現非常簡單,就是看整個內存塊是否全部為 0 。
舉個例子,現在 sparse_copy 從源文件里讀出 4k 的數據,發現全都是 0,那么目標文件對應的位置就不會寫入,而是直接 punch hole 打洞,節省空間。
但是注意了,這種行為只有在激進的 sparse always 策略才是這樣的。如果是其他策略,sparse_copy 不會做這樣做,而是老老實實的拷貝數據,哪怕是全 0 的數據,也要如實的寫入到目標文件。
所以,always 模式下,目標文件所占物理空間比源文件小的根本原因就在于 sparse_copy 這個函數的實現。
cp 快速的原因
梳理到這里,cp 的秘密已經徹底揭開了,cp 一個 100G 的文件為什么那么快?
因為源文件是稀疏文件啊,文件看似 100G,實際只占用了 2M 的物理空間。文件系統將文件大小和物理空間占用這兩個概念解耦,使得有更靈活的使用姿勢,更有效的使用物理空間。
cp 默認的情況下,通過文件系統提供的 fiemap 接口,獲取到文件所有的空洞信息,然后跳過這些空洞,只 copy 有效的數據,極大的減少了磁盤 io 的數據量,所以才那么快。
總結下 cp --sparse 三個參數的特點:
auto 模式:默認模式,最一致的模式(如果沒有用戶全0 塊數據,那么可能也是速度最快的),會根據源文件的實際空間占用復制數據,目標文件和源文件一致。無論是文件 size 還是物理 blocks;
always 模式:追求最小空間占用的模式,就算源文件不是稀疏文件,而僅僅是有些連續大塊的全 0 數據,也會嘗試在目標文件上 punch hole,從而節省空間,這種方式會導致目標文件的物理 blocks 可能比源文件要小;
never 模式:最低效,速度最慢的方式。這種方式無論源文件是啥,全都是實打實的復制,不管是空洞還是全 0 數據,都會在目標文件寫入;
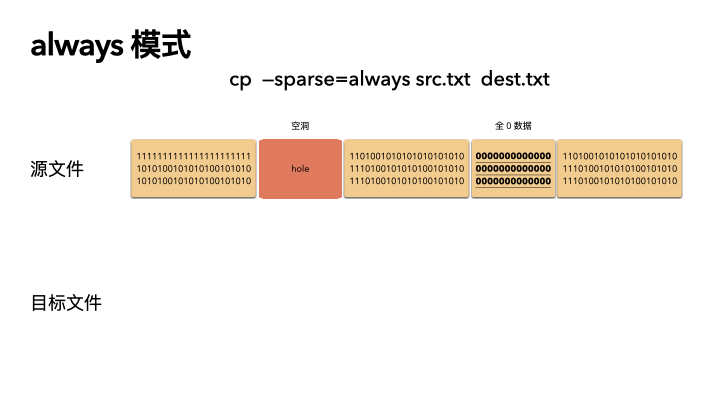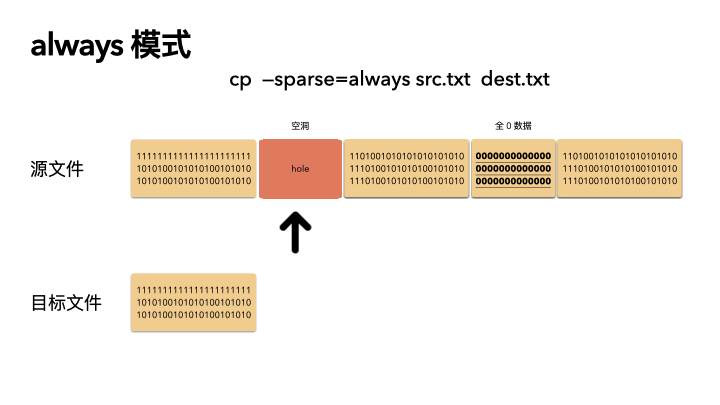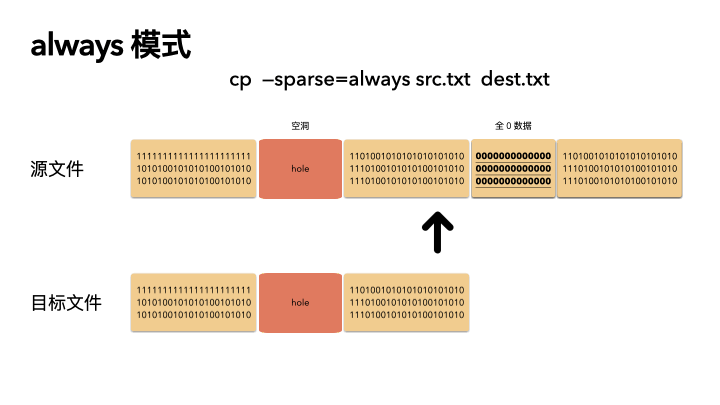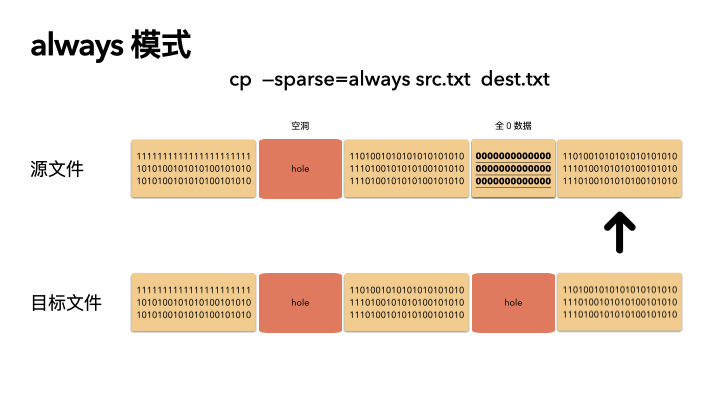
動畫演示(精髓):
精髓所在,前面知識點就算全都忘了,只記得這三張圖,你也賺了。
cp src.txt dest.txt
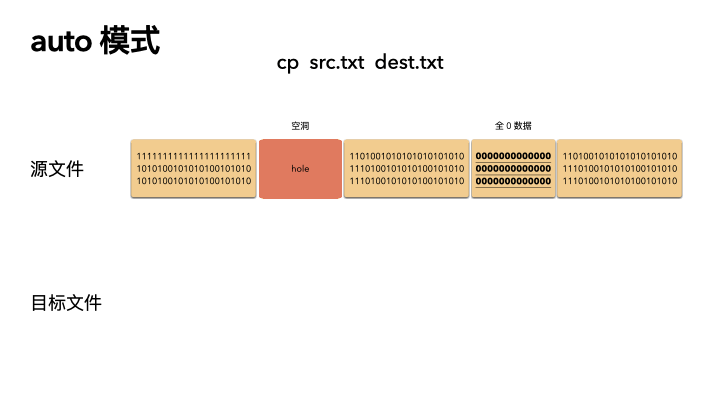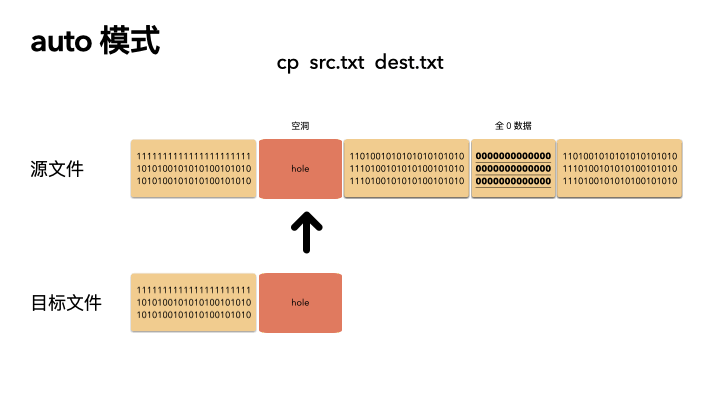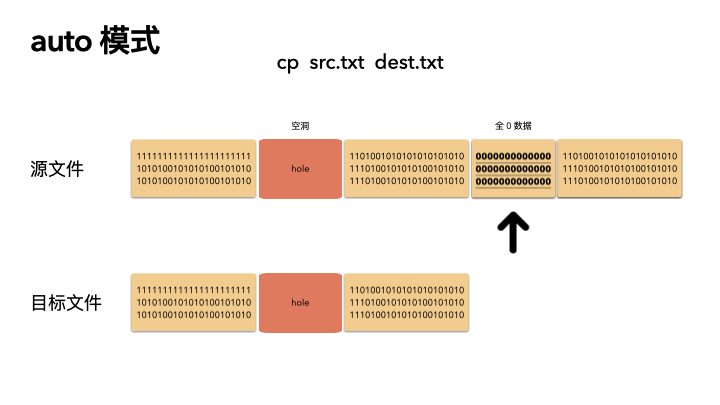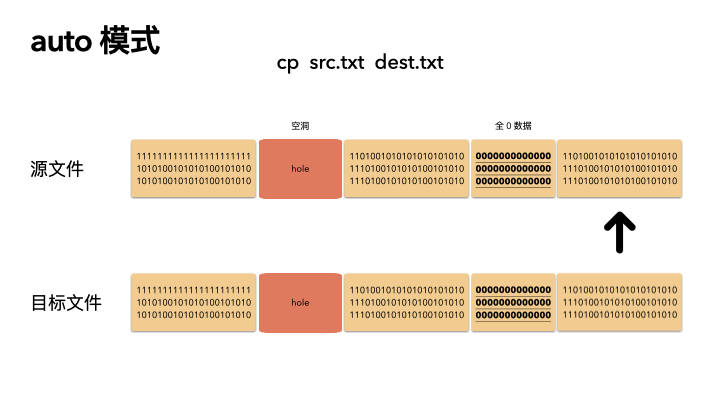
cp --sparse=always src.txt dest.txt
cp --sparse=never src.txt dest.txt
稀疏文件的應用
稀疏文件在哪些地方有應用呢?
數據庫快照:生成一個數據庫快照時會生成一個稀疏文件,稀疏文件一開始并不會占用磁盤空間。當源數據庫發生寫操作時,就把修改前的原數據塊復制且只復制一次到稀疏文件中;
MySQL5.7 有一種數據壓縮方式,其原理就是利用內核Punch hole特性,對于一個16kb的數據頁,在寫文件之前,除了 Page 頭之外,其他部分進行壓縮,壓縮后留白的地方使用 punch hole 進行 “打洞”,在磁盤上表現為不占用空間,從而達到快速釋放物理空間的目的;
qemu 磁盤鏡像文件的空間回收場景;
一起做個實驗
最后我們演示下實驗,檢驗看下你懂了嗎?找一臺 linux 機器,跟著運行下面的命令。
初始條件準備
步驟一:創建一個文件(預期占用 1 個 block)。
echo =========== test ======= 》 test.txt
步驟二:truncate 成 1G 的稀疏文件。
truncate -s 1G 。/test.txt
步驟三:把 1M 到 1M+4K 的位置預分配出來(并且是寫 0 分配,預期到這里要占用 2 個 block,也就是 8K 數據)。
fallocate -o 1048576 -l 4096 -z 。/test.txt
步驟四:stat 命令檢查下情況。
sh-4.4# stat test.txt
File: test.txt
Size: 1073741824 Blocks: 16 IO Block: 4096 regular file
Device: 6ah/106d Inode: 3148347 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-12 1554.427903000 +0000
Modify: 2021-03-12 1500.456246000 +0000
Change: 2021-03-12 1500.456246000 +0000
Birth: -
我們看到 Size: 1073741824 Blocks: 16 ,Size 大小等于 1G,stat 顯示的 Blocks 是扇區(512字節)的個數,也就是說,物理空間占用 8K,符合預期。
也就是說:
文件大小為 1G;
實際數據在 [0, 4K] 和 [1M, 1M+4K] 這兩個位置才有寫入;
其中 [0, 4K] 范圍為正常數據, [1M, 1M+4K] 這段范圍的數據為全 0 數據;
好,初始條件準備好了,下面我們開始對 cp --sparse 的三個行為做實驗。
cp 的實驗驗證
默認策略:
cp 。/test.txt 。/test.txt.auto
always 策略:
cp --sparse=always 。/test.txt 。/test.txt.always
never 策略(這條命令敲下去可能有點慢哦,并且要預留好足夠空間):
cp --sparse=never 。/test.txt 。/test.txt.never
以上三個命令敲完,生成了三個文件,給大家 1 秒鐘的思考時間,思考下 test.txt.auto,test.txt.always,test.txt.never,這三個文件的屬性有何異同。
。..。. 。..。. 。..。.
結果揭秘:
test.txt.auto
sh-4.4# stat 。/test.txt.auto
File: 。/test.txt.auto
Size: 1073741824 Blocks: 16 IO Block: 4096 regular file
Device: 6ah/106d Inode: 3148348 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 1557.395725000 +0000
Modify: 2021-03-13 1557.395725000 +0000
Change: 2021-03-13 1557.395725000 +0000
Birth: -
Size: 1073741824:文件大小 1G
Blocks: 8:物理空間占用 8K
test.txt.always
sh-4.4# stat 。/test.txt.always
File: 。/test.txt.always
Size: 1073741824 Blocks: 8 IO Block: 4096 regular file
Device: 6ah/106d Inode: 3148349 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 1501.064725000 +0000
Modify: 2021-03-13 1501.064725000 +0000
Change: 2021-03-13 1501.064725000 +0000
Birth: -
Size: 1073741824:文件大小 1G
Blocks: 8:物理空間占用 4K
test.txt.never
sh-4.4# stat 。/test.txt.never
File: 。/test.txt.never
Size: 1073741824 Blocks: 2097160 IO Block: 4096 regular file
Device: 6ah/106d Inode: 3148350 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 1504.774725000 +0000
Modify: 2021-03-13 1505.977725000 +0000
Change: 2021-03-13 1505.977725000 +0000
Birth: -
Size: 1073741824:文件大小 1G
Blocks: 2097160:物理空間占用 1G
所以,你學會了嗎?
知識點總結
文件系統對外提供文件語義,本質只是管理磁盤空間的軟件而已;
經典的文件系統主要劃分 3 大塊 superblock 區,inode 區,block 區(塊描述區,bitmap區這里暫不介紹)。一個文件在文件系統的內部形態由一個 inode 記錄元數據加上 block 存儲用戶存儲用戶數據樣子;
文件系統的 size 是文件大小,是邏輯空間大小,文件大小 size 和真實的物理空間并不是一個概念;
稀疏語義是文件系統提供的一種特性,根本用途是用來更有效的利用磁盤空間;
后分配空間是空間利用最有效的方式,公有云的云盤靠什么賺錢?就是后分配,你買了 2T 的云盤,在沒有寫入數據的時候,一個字節都沒給你分配,你卻是付出 2T 的價格;
stat 命令能夠查看物理空間占用,Blocks 表示的是扇區(512字節)個數;
稀疏文件的空洞和用戶真正的全 0 數據是無法區分的,因為對外表現是一樣的(這點非常重要);
cp 命令通過調用 ioctl(fiemap)系統調用,可以獲取到文件空洞的分布情況,cp 過程中跳過這些空洞,極大的提高了效率(100G 的源文件,cp 只做了十幾次 io 搞定了,所以 1 秒足以);
cp 的 sparse 參數從速度最快,空間最省,數據最拷貝最多,各有特點,小小的 cp 命令出來的目標文件,其實和源文件并不相同,只不過你沒注意到;
預分配和 punch hole 其實都是fallocate 調用,只是參數不同而已,調用的時候,注意要 4k 對齊才能達到目的;
稀疏文件的 punch hole 應用有很多場景,通常是用來快速釋放空間,比如鏡像文件。
原文標題:深度剖析 Linux cp 命令的秘密
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
Linux
+關注
關注
87文章
11292瀏覽量
209331 -
命令
+關注
關注
5文章
683瀏覽量
22011
原文標題:深度剖析 Linux cp 命令的秘密
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux常用命令



shell基本介紹及常用命令之shell介紹
Windows操作系統中的常用命令
Jlink.exe(Jlink commander)的常用命令






 工商網監
工商網監
評論