

如何理解泛化是深度學習領域尚未解決的基礎問題之一。為什么使用有限訓練數據集優化模型能使模型在預留測試集上取得良好表現?這一問題距今已有 50 多年的豐富歷史,并在機器學習中得到廣泛研究。如今有許多數學工具可以用來幫助研究人員了解某些模型的泛化能力。但遺憾的是,現有的大多數理論都無法應用到現代深度網絡中,這些理論在現實環境中顯得既空泛又不可預測。而理論和實踐之間的差距 在過度參數化模型中尤為巨大,這類模型在理論上能夠擬合訓練集,但在實踐中卻不能做到。
豐富歷史
數學工具
過度參數化
在《Deep Bootstrap 框架:擁有出色的在線學習能力即是擁有出色的泛化能力》(The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers)(收錄于 ICLR 2021)這篇論文中,我們提出了一個解決此問題的新框架,該框架能夠將泛化與在線優化領域聯系起來。在通常情況下,模型會在有限的樣本集上進行訓練,而這些樣本會在多個訓練周期中被重復使用。但就在線優化而言,模型可以訪問無限的樣本流,并且可以在處理樣本流的同時進行迭代更新。在這項研究中,我們發現,能使用無限數據快速訓練的模型,它們在有限數據上同樣具有良好的泛化表現。二者之間的這種關聯為設計實踐提供了新思路,同時也為從理論角度理解泛化找到了方向。
《Deep Bootstrap 框架:擁有出色的在線學習能力即是擁有出色的泛化能力》
Deep Bootstrap 框架
Deep Bootstrap 框架的主要思路是將訓練數據有限的現實情況與數據無限的“理想情況”進行比較。它們的定義如下:
現實情況(N、T):使用來自一個分布的 N 個訓練樣本訓練模型;在 T 個小批量隨機梯度下降 (SGD) 步驟中,照常在多個訓練周期中重復使用這 N 個樣本。這相當于針對經驗損失(訓練數據的損失)運行 SGD 算法,這是監督學習中的標準訓練程序。
理想情況(T):在 T 個步驟中訓練同一個模型,但在每個 SGD 步驟中使用來自分布的新樣本。也就是說,我們運行相同的訓練代碼(相同的優化器、學習速率、批次大小等),但在每個訓練周期中采用全新的訓練樣本集,而不是重復使用相同的樣本。理想情況下,對于一個幾乎達到無限的“訓練集”而言,其訓練誤差和測試誤差之間相差無幾。
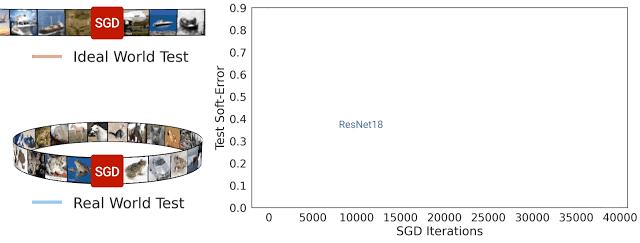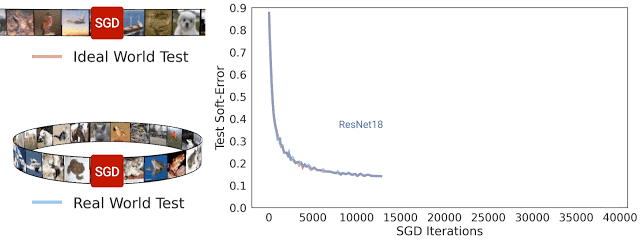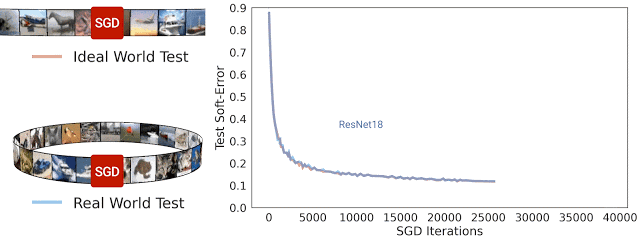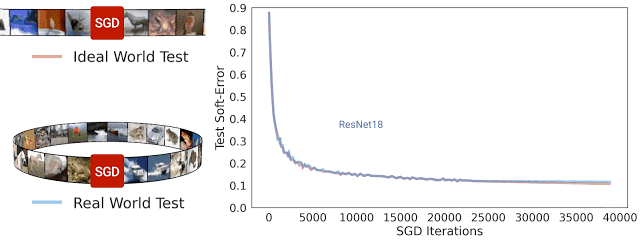
在 SGD 迭代期間 ResNet-18 架構理想情況及現實情況的測試軟誤差。可以看到,兩種誤差非常相近
一般而言,我們認為現實情況和理想情況不會有任何關聯,因為在現實世界中用于模型處理的來自分布的示例數量是有限的,而在理想世界中模型處理的示例數量是無限的。但在實踐中,我們發現現實情況模型和理想情況模型之間的測試誤差非常相近。
為了將此觀察結果量化,我們通過創建一個名為 CIFAR-5m 的數據集模擬了一種理想情況。我們使用 CIFAR-10 訓練了一個生成模型,然后利用該模型生成約六百萬個圖像。選擇生成這么多圖像的目的是為了使此數據集對于模型而言具有“近乎無限性”,從而避免模型重復采樣相同的數據。也就是說,在理想情況下,模型面對的是一組全新的樣本。
CIFAR-5m
生成模型
下圖給出了幾種模型的測試誤差,對比了它們在現實情況(如重復使用數據)和理想情況(使用“全新”數據)中使用 CIFAR-5m 數據訓練的表現。藍色實線展示了 ResNet 模型在現實情況下使用標準 CIFAR-10 超參數針對 50000 個樣本訓練 100 個周期的表現。藍色虛線展示了同樣的模型在理想情況下使用五百萬個樣本一次性訓練完畢的表現。出人意料的是,現實情況和理想情況下的測試誤差非常接近,在某種程度上模型并不會受到樣本是重復使用還是全新的影響。
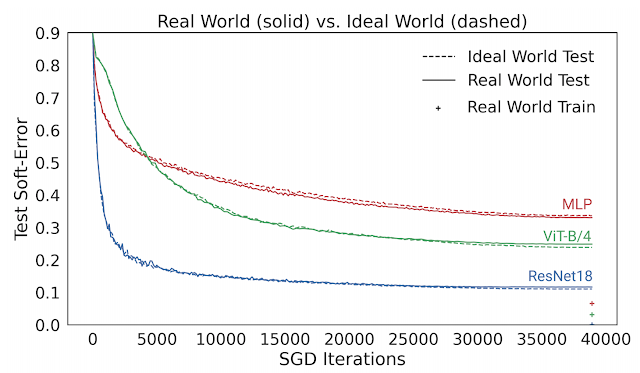
現實情況下的模型使用 50000 個樣本訓練 100 個周期,理想情況下的模型使用五百萬個樣本訓練一個周期。圖中的線展示了測試誤差以及 SGD 步驟的執行次數
這個結果也適用于其他架構,如多層感知架構(紅線)、視覺 Transformer(綠線),以及許多其他架構、優化器、數據分布和樣本大小設置。從這些實驗中,我們得出了一個關于泛化的新觀點,即能使用無限數據快速優化的模型,同樣能使用有限數據進行良好的泛化。例如,ResNet 模型使用有限數據進行泛化的能力要優于 MLP 模型,其原因在于 ResNet 模型使用無限數據進行優化的速度更快。
多層感知
基于優化行為理解泛化
我們從中得出一個重要的觀察結果,即直到現實情況開始收斂前,現實情況和理想情況下的模型在所有時刻的測試誤差都非常接近(訓練誤差 《 1%)。因此,我們可以通過研究模型在理想情況下的行為來理解它們在現實情況下的表現。
也就是說,模型的泛化可以通過研究其在兩種框架下的優化表現來理解:
1. 在線優化:其用于在理想情況下觀察測試誤差的減小速度
2. 離線優化:其用于在現實情況下觀察訓練誤差的收斂速度
因此,研究泛化時,我們可以相應地研究上述兩個方面,它們僅涉及優化問題,因此在概念上較為簡單。通過這項觀察,我們發現出色的模型和訓練程序均符合兩個條件:(1) 能在理想情況下快速優化;(2) 在現實情況下的優化速度較慢。
所有深度學習設計方案都能通過了解它們在這兩方面的表現來進行評估。例如,一些改進,比如卷積、殘差連接和預訓練等,其主要作用是加速理想情況的優化,而另一些改進,比如正則化和數據增強等,其主要作用則是減慢現實情況的優化。
應用 Deep Bootstrap 框架
研究人員可以使用 Deep Bootstrap 框架來研究和指導深度學習設計方案。它所依循的原則是:每當我們做出影響現實情況泛化能力的更改時(架構、學習速率等),我們都應考慮它對以下兩方面帶來的影響:(1) 理想情況的測試誤差優化(越快越好)以及 (2) 現實情況的訓練誤差優化(越慢越好)。
例如, 預訓練在實踐中通常用于促進小數據體系中的模型泛化。然而,人們對預訓練發生作用的機理知之甚少。我們可以使用 Deep Bootstrap 框架,通過觀察預訓練對上述兩方面形成的影響研究這個問題。我們發現,預訓練的主要作用是促進理想情況的優化 (1),即使網絡能夠“快速學習”在線優化。預訓練模型泛化能力的增強幾乎總能帶來其在理想情況下優化能力的提高。下圖比較了使用 CIFAR-10 訓練的視覺 Transformers (ViT) 在 ImageNet 上從零開始訓練和預訓練之間的差別。
ImageNet
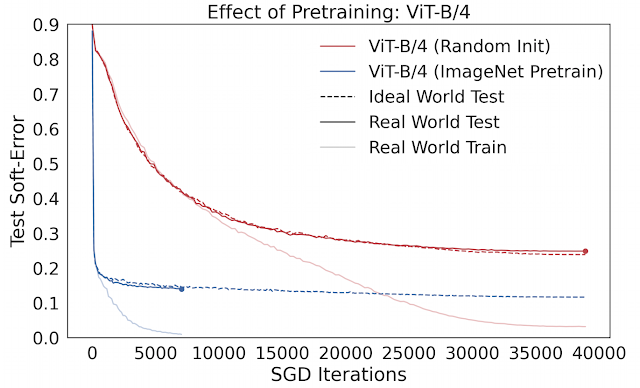
預訓練的作用:經過預訓練的 ViT 在理想情況下的優化速度更快
我們還可以使用此框架研究數據增強。在理想情況下的數據增強相當于對每個新樣本進行一次增強,而不是對同一個樣本進行多次增強。此框架意味著好的數據增強均符合兩個條件:(1) 不會嚴重損害理想情況的優化(即增強樣本的分布不會過于“失范”),(2) 抑制現實情況的優化速度(以使現實世界花更多時間擬合其訓練集)。
數據增強的主要作用通過第二條:延長現實情況的優化時間來實現。關于第一條,一些激進的數據增強 (混合/剪切) 可能會對理想情況造成不良影響,但這種影響與第二條相比不值一提。
結語
Deep Bootstrap 框架為理解深度學習的泛化和經驗現象提供了一個新角度。我們非常期待能夠在未來看到它被用于理解深度學習的其他方面。尤為有趣的是,泛化可以通過純粹的優化方面的考量來描述, 這在理論上和許多主流方法相悖。至關重要的是,我們需同時考慮在線優化和離線優化,單獨考慮二者中的任何一個都是不夠的,它們共同決定了泛化能力。
主流方法
Deep Bootstrap 框架還揭曉了為什么深度學習對于許多設計方案都異常穩健,原因是許多中架構、損失函數、優化器、標準化和激活函數都具有良好的泛化能力。這個框架揭示了一個普適定律:基本上任何具有良好在線優化表現的設計方案,其都能在離線狀態下有良好的泛化表現。
最后,現代神經網絡既可能過參數化(如使用小型數據任務訓練的大型網絡),也可能欠參數化(如 OpenAI GPT-3、Google T5 或 Facebook ResNeXt WSL)。而 Deep Bootstrap 框架表明,在線優化是在這兩種模式中取得成功的關鍵因素。
致謝
感謝我們的合著者 Behnam Neyshabur 對論文的巨大貢獻以及對于博文的寶貴反饋。感謝 Boaz Barak、Chenyang Yuan 和 Chiyuan Zhang 對于博文及論文的有益評論。
-
深度學習
+關注
關注
73文章
5544瀏覽量
122275
原文標題:透過新視角理解深度學習中的泛化
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監

評論